
3 ответа
Лучший ответ
Я недавно пережил то же самое. См. Добавление столбец, не допускающий значения NULL, в существующую таблицу не удается. Атрибут value игнорируется?
Невозможно (в одном операторе SQL) добавить столбец со значением для существующих строк, не установив его в качестве значения столбца по умолчанию. Поэтому, если вы хотите, чтобы существующие строки имели значение, отличное от добавленных новых строк (в том числе, если вам вообще не нужно значение по умолчанию для столбца), вам понадобятся как минимум два оператора SQL. Таким образом, используя Liquibase, вам все равно нужно будет добавить этот столбец на трех описанных вами шагах.
Итак, мой ответ на ваш вопрос: Да, использование Liquibase дает преимущества по сравнению с простым обслуживанием ряда сценариев SQL. Но это не один из них. ![]()
1
Community
23 Май 2017 в 12:23
Главное, что дает Liquibase — это возможность отслеживать, какие изменения были применены к каким базам данных.
В вашем примере SQL, который вы перечисляете, будет именно тем, что будет делать Liquibase, но он сможет знать, что ваша база данных разработчика находится в версии Y, и когда вы «обновите» свою базу данных, она применит только пару новых изменений, тогда как производство находится в версии X, и когда вы «обновите» производство, он внесет больше изменений.
Примечание: Liquibase отслеживает изменения независимо, а не использует одну версию для поддержки нескольких разработчиков и / или веток кода.
Помимо отслеживания внесенных изменений, Liquibase может дать вам следующие преимущества:
- Возможность иметь одно и то же описание изменения для нескольких типов баз данных.
- Возможность иметь логику «если / то» в том, что применяется.
- Сгенерирована документация по истории базы данных.
- Возможность легко указывать более сложные изменения, состоящие из нескольких операторов.
5
Steven Shaw
18 Авг 2012 в 12:56
На мой взгляд, Mite дает вам лучшее из обоих миров. Вы можете продолжать использовать свои сценарии sql, и он управляет тем, был ли сценарий выполнен в базе данных, и дает вам те же возможности вверх и вниз, что и при типичной миграции на основе рельсов или Liquibase.
Дайте мне знать, что вы думаете.
Martin Murphy
28 Июл 2012 в 22:35
Править:
Спасибо за ответы, кажется, существует некоторое согласие, что байт используется для хранения размера, но это не улаживает вопрос окончательно в моем уме.
Если метаданные (длина строки) хранятся в той же непрерывной памяти/диске, это имеет некоторый смысл. 1 байт метаданных и 255 байтов строковых данных, удовлетворили бы друг другу очень приятно и вписались бы в 256 непрерывных байтов устройства хранения данных, которое, по-видимому, аккуратно и опрятно.
Но… Если метаданные (длина строки) хранятся отдельно от фактических строковых данных (в основной таблице, возможно), то ограничить длину данных строки на один байт, просто потому что легче сохранить только 1-байтовое целое число метаданных, кажется немного нечетным.
4 ответа
Лучший ответ
Всегда выбирайте наименьший возможный тип данных. SQL не может угадать, каким должно быть максимальное значение, но он может оптимизировать хранение и производительность, если вы укажете тип данных.
Чтобы ответить на ваше обновление:
занимает ровно столько места, сколько вы используете, поэтому вы правы, когда говорите, что символ «a» займет 1 байт (в латинской кодировке) независимо от размера выбранное вами поле. Это не относится к любому другому типу поля в SQL.
Однако вы, скорее всего, пожертвуете эффективностью ради места, если сделаете все полем varchar. Если все является полем фиксированного размера, то SQL может выполнить простое постоянное умножение, чтобы найти ваше значение (например, массив). Если у вас есть поля varchar, то единственный способ узнать, где хранятся ваши данные, — это просмотреть все предыдущие поля (например, связанный список).
Если вы начинаете SQL, я советую просто держаться подальше от полей varchar, если вы не ожидаете, что у вас будут поля, которые иногда содержат очень небольшие объемы текста, а иногда и очень большие объемы текста (например, сообщения в блогах). Требуется опыт, чтобы знать, когда лучше всего использовать поля переменной длины, и даже я в большинстве случаев не знаю.
4
Kai
27 Окт 2009 в 03:48
Традиционно каждый бит, сохраненный в размере страницы, означал небольшое улучшение скорости: более узкие строки означают больше строк на страницу, что означает меньше потребляемой памяти и меньше запросов ввода-вывода, что приводит к повышению скорости. Однако с сжатием страниц SQL Server 2008 все становится нечетким. Алгоритм сжатия может сжимать целые 4 байта со значениями меньше 255 даже меньше байта.
Алгоритмы сжатия строк сохранят 4-байтовое int в одном байте для значения меньше 127 (int подписано), 2 байта для значений меньше 32768 и так далее и так далее.
Однако, учитывая, что удобные функции сжатия доступны только на серверах Enterprise Edition, имеет смысл сохранить привычку использовать минимально возможный тип данных.
Remus Rusanu
27 Окт 2009 в 03:54
Преимущество есть, но оно может быть незначительным, если у вас много строк и не выполняется потеря операций. Будет улучшение производительности и меньшее хранилище.
o.k.w
27 Окт 2009 в 03:07
Это соображение производительности, связанное с конструкцией вашей системы. В общем, чем больше данных вы поместите на страницу данных Sql Server, тем лучше будет производительность.
Одна страница в Sql Server — 8k. Использование крошечных целых чисел вместо целых позволит вам разместить больше данных на одной странице, но вы должны подумать, стоит ли это того. Если вы собираетесь обрабатывать тысячи обращений в минуту, тогда да. Если это хобби-проект или что-то, что когда-либо увидят всего несколько десятков пользователей, это не имеет значения.
4
Paul Sasik
27 Окт 2009 в 03:08
2 ответа
Лучший ответ
Я не знаком ни с одним диалектом SQL, который реализует varchar (n), который ведет себя так, как вы предлагаете — рекомендуемый начальный размер, а затем позволяющий ему увеличиваться. Это применимо к Oracle, SQL Server, MySQL и Postgres. Во всех этих базах данных varchar (n) ведет себя примерно так же, как вы видите в Teradata в операторах SELECT с явным приведением типов. Я не верю, что какая-либо причина ошибки усечения, когда более длинная строка помещается в более короткую.
Как отмечает Бранко в своем комментарии, на этапах модификации данных поведение отличается, когда неявное приведение действительно вызывает ошибку.
Я не знаком со всеми деталями Teradata. В SQL Server исторически существует огромная разница между varchar (max) и varchar (8000). Первые будут размещены на отдельной странице данных, а вторые — на той же странице, что и данные. (Правила были изменены в более поздних версиях, поэтому символы varchars могут вытекать за пределы страницы данных.)
Другими словами, при использовании varchar (max) могут быть другие соображения, включая то, как данные хранятся на страницах, как на них строятся индексы, и, возможно, другие соображения.
Я предлагаю вам выбрать достаточно большой размер, скажем, 1000 или около того, и позволить приложению продолжить работу оттуда. Если вам нужна реальная гибкость, используйте varchar (max). Вам также следует изучить через документацию Teradata и / или связаться с техническими специалистами, в чем заключаются проблемы с объявлением очень больших строк.
2
Gordon Linoff
23 Авг 2012 в 13:03
Терадата работает в двух режимах: Терадата (BT; .. ET;) и ANSI (фиксация;). У них есть список различий, и одно из них вы встречали во время разработки — режим Teradata позволяет обрезать отображаемые данные. Напротив — ANSI запрещает такое усечение, поэтому вы увидите ошибку. Чтобы понять это, воспользуйтесь простым примером: создайте таблицу check_exec_mode (str varchar (5)); выберите * из check_exec_mode; вставить в значения check_exec_mode (‘123456’); Если вы настроите подключения своего клиента тераданных (например, Teradata Studio Express) в TMODE (режим транзакции) = TERA, то в результате вы получите одну усеченную строку в таблице (‘12345’). Изменение режима транзакции на ANSI и выполнение оператора вставки приведет к ошибке «Правое усечение строковых данных».
1
Dima
30 Июн 2015 в 17:51
Устройство файла *.1CD
На самом нижнем уровне файл *.1CD или файл базы данных содержит внутри своего рода файловую систему, включающую в себя так называемые внутренние файлы. Файл *.1CD имеет страничную организацию, то есть состоит из страниц размером 4096 байт (4 К). Размер файла *.1CD всегда кратен 4 К.
Страницы адресуются их номерами. Номер страницы представлен 4-байтовым целым числом без знака. Следовательно, файл *.1CD может содержать не более чем 4 294 967 296 страниц.
Страница с номером 0 содержит служебные данные файла *.1CD, такие как версия формата файла базы данных, общее число страниц в файле и т. п.
Страница с номером 1 используется менеджером свободных страниц.
Каждая из остальных страниц может либо принадлежать какому-либо из внутренних файлов, либо находиться в списке свободных страниц.
Внутренние файлы
Страницы, относящиеся к внутреннему файлу, бывают трех видов:
- корневая страница,
- индексные страницы,
- страницы данных.
Эти страницы образуют дерево, корнем которого является корневая страница, промежуточными узлами являются индексные страницы, а листьями – страницы данных.
Корневая страница содержит служебную информацию внутреннего файла, такую как длина файла, номер версии данных файла и т. п. Кроме того, на корневой странице содержится до 1018 номеров индексных страниц.
Индексные страницы образуют промежуточный уровень дерева. Индексная страница содержит число страниц данных, адресуемых данной индексной страницей, и до 1023 номеров страниц данных.
Страница данных содержит только данные.
Из сказанного выше следует, что внутренний файл может включать не более чем 1 041 414 (1018 * 1023) страниц данных. Следовательно, максимальный размер внутреннего файла не может превышать 4 265 631 744 (1018 * 1023 * 4096) байта. Для адресации отдельных байтов внутреннего файла используются 4-байтовые целые числа без знака.
Для представления внутреннего файла нулевой длины достаточно одной только корневой страницы. Если размер внутреннего файла составляет от 1 до 4096, то он представляется тремя страницами: одной корневой, одной индексной и одной страницей данных. При дальнейшем росте размера файла добавляются новые страницы данных, и их номера помещаются в индексную страницу. Как только индексная страница перестает вмещать номера страниц данных, добавляется новая индексная страница и ее номер добавляется в корневую страницу. И так далее.
Внутренние файлы не имеют имен. Для идентификации внутренних файлов используются номера их корневых страниц.
Список свободных страниц
Страницы, не относящиеся к какому-либо из внутренних файлов, находятся в списке свободных страниц. Свободные страницы могут образоваться при сокращении размера или удалении внутреннего файла. Любые освободившиеся страницы внутренних файлов помещаются в список свободных страниц.
При необходимости увеличения размера или создании нового внутреннего файла по возможности используются страницы из списка свободных страниц.
7 ответов
При максимальной длине 255 символов СУБД может выбрать использование одного байта для указания длины данных в поле. Если бы ограничение было 256 или больше, потребовалось бы два байта.
Для данных , безусловно, допустимо значение длины ноль (если нет других ограничений). Большинство систем рассматривают такую пустую строку как отличную от NULL, но некоторые системы (в частности, Oracle) рассматривают пустую строку идентично NULL. В системах, где пустая строка не является NULL, потребуется дополнительный бит где-то в строке, чтобы указать, следует ли считать значение NULL или нет.
Как вы заметили, это историческая оптимизация и, вероятно, не актуальна для большинства систем сегодня.
ответ дан 23 November 2019 в 06:07
255 было пределом varchar в mySQL4 и ранее.
Также 255 символов + нулевой терминатор = 256
Или описатель длины в 1 байт дает возможный диапазон 0-255 символов
ответ дан 23 November 2019 в 06:07
Часто символы varchars реализуются как строки паскаля: они содержат фактическую длину в байте №0. Таким образом, длина была привязана к 255. (Значение байта варьируется от 0 до 255.)
ответ дан 23 November 2019 в 06:07
Проверьте, принадлежит ли каждый из ваших файлов в .git/текущему пользователю.
У меня была та же самая проблема, когда я понимал, что сделал некоторые фиксации с корневым пользователем, и что создал объекты (под .git/objects), где принадлежать корню, тригерируя ошибки при запуске git как обычного пользователя.
Эта команда решила проблему:
-121—3147423-
Похоже, никто не упомянул Query Express ( http://www.albahari.com/queryexpress.aspx ) и вилку Query ExPlus (также ссылка в нижней части http://www.albahari.com/queryexpress.aspx )
BTW. Первый URL — главная страница Джозефа Албахари, который является автором LINQPad (проверьте этот инструмент убийцы)
-121—2032036-
Максимальная длина 255 позволяет ядру СУБД использовать только 1 байт для хранения длины каждого поля. Правильно, что 1 байт пространства позволяет хранить 2 ^ 8 = 256 различные значения длины последовательности.
Но если вы разрешаете полю хранить текстовые последовательности нулевой длины, вы должны иметь возможность хранить ноль в длину. Таким образом, можно разрешить 256 различных значений длины, начиная с нуля: 0-255.
ответ дан 23 November 2019 в 06:07
255 — максимальное значение 8-битного целого числа : 11111111 = 255.
ответ дан 23 November 2019 в 06:07
255 — это наибольшее числовое значение, которое может храниться в однобайтовом беззнаковом целом (предполагая 8-битные байты) — следовательно, приложения, которые хранят длину строки для какой-то цели, предпочтут 255 вместо 256, потому что это означает, что они должны выделить только 1 байт для переменной «size».
ответ дан 23 November 2019 в 06:07
8 бит без знака = 256 байтов
255 символов + байт 0 для длины
ответ дан 23 November 2019 в 06:07
Другие вопросы по тегам:
7 ответов
Лучший ответ
Что касается обеспечения этого в ограничении , моим решением было бы создать зависимую таблицу, чтобы строки, на которые есть ссылки, не могли быть удалены.
Теперь никто не может удалить строки в со значениями id 0, 1 или 2, если они сначала не удалят соответствующие строки в . Вы можете ограничить удаление зависимой таблицы с помощью привилегий SQL.
10
Bill Karwin
14 Дек 2008 в 23:04
Вы делаете это, написав триггер базы данных, который срабатывает при DELETE для рассматриваемой таблицы. Все, что ему нужно сделать, это выбросить исключение, если идентификатор недействителен.
5
D’Arcy Rittich
14 Дек 2008 в 22:45
Если вы не доверяете своим пользователям, добавьте безопасность.
- Добавьте хранимую процедуру, которая позволяет пользователям удалять нужные им строки, но запрещает любые из них в соответствии с вашими собственными правилами. Затем запретите удаление доступа к таблице и разрешите выполнение доступа к sproc
- Добавьте вторичную таблицу со ссылками на внешние ключи, вызовите таблицу MasterAccounts или аналогичную, запретите доступ к обновлению / удалению этой таблицы и добавьте ссылки на нее в соответствующие учетные записи, это предотвратит удаление учетной записи кем-либо, пока существует ссылка на него из этой таблицы
- Добавьте триггер, как предлагает OrbMan
- Добавьте представление, в котором они могут удалять строки, сделайте так, чтобы представление пропустило все те учетные записи, которые им не разрешено удалять, запретите удаление доступа к главной таблице и разрешите доступ на удаление для просмотра
Сказав это, если у ваших пользователей достаточно доступа, чтобы разговаривать с вашей базой данных через SQL, тогда вы на самом деле просто напрашиваетесь на проблемы. Вам следует усилить безопасность и разрешить доступ к базе данных только через ваше приложение и установленные протоколы. Тогда у вас есть много способов избежать подобных проблем.
3
Community
23 Май 2017 в 15:33
Я использую следующий триггер:
1
Tom
15 Дек 2008 в 01:16
Вы уверены, что это правда, что вы никогда не захотите, чтобы кто-либо удалял эти строки? Даже себя или ДБА? Или работы по обслуживанию dbms?
Если это только некоторые пользователи, вам понадобится что-то вроде таблицы пользователей с разрешениями, чтобы ее можно было запросить в триггере, чтобы отличить неавторизованных пользователей от авторизованных.
dkretz
14 Дек 2008 в 23:55
Вы можете попробовать фильтровать свои запросы с помощью функции, которая проверяет, не пытается ли пользователь удалить вашу основную учетную запись.
-1
Milhous
14 Дек 2008 в 22:36
В решении, которое я предпочитаю, используется реляционная модель и ее правила целостности.
Для каждой записи в , которую нельзя удалить, я бы добавил запись в , где — внешний ключ. не доступен для обновления, кроме как администратором базы данных. После этого никто другой не сможет удалить записи из , которые связаны с .

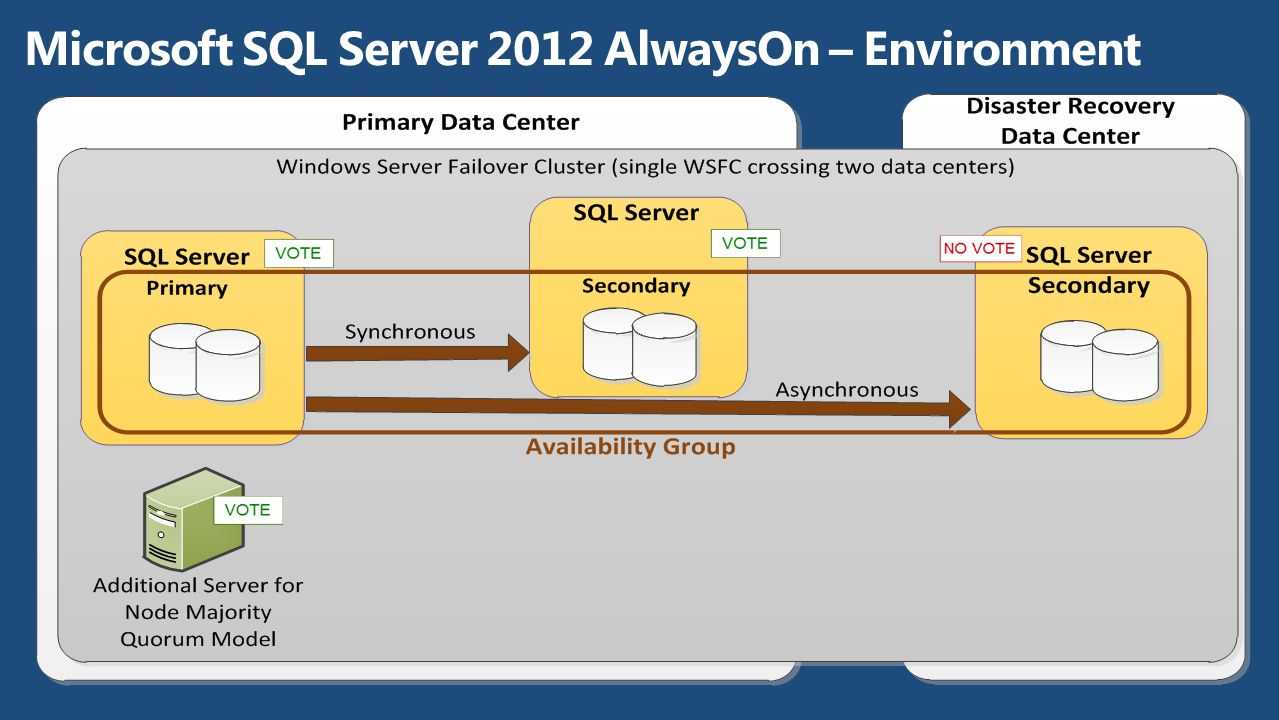

РЕДАКТИРОВАТЬ: я только что заметил, что такая же идея была разработана здесь. Спасибо, Билл!
Community
23 Май 2017 в 15:19
5 ответов
Лучший ответ
Из стандарта SQL ANSI-92 (выполните поиск по запросу «НЕКОТОРЫЕ»). Также здесь текст
Я подозреваю, что причина в том, что язык SQL появился в начале 1970-х годов, но не имел стандарта до 1986 года. Стандарт взял бы элементы существующих диалектов SQL, так что у нас есть НЕКОТОРЫЕ / ЛЮБОЙ аномалии.
В этой статье блога Брэда Шульца объясняются некоторые различия: «ВСЕ, ЛЮБЫЕ и НЕКОТОРЫЕ: Три марионетки «
16
doubleDown
26 Июл 2013 в 03:19
НЕКОТОРЫЕ и ЛЮБЫЕ эквивалентны. ANY — синтаксис ANSI. Почему введено НЕКОТОРЫЕ, я не знаю. Может быть, из-за удобочитаемости, но оба следующих предложения легко понять.
Хотя в обоих случаях SQL-сервер выполнит:
Что тоже очень легко понять.
6
Joel
5 Сен 2009 в 19:28
«Существуют ли какие-либо исторические причины, по которым они имеют одинаковую функциональность?»
Я отвечу на собственно вопрос … Вначале было просто ВСЕ и ЛЮБОЕ.
ВСЕ — универсальный квантор, в то время как ЛЮБОЙ всегда должен был быть квантификатором существования. Однако в английском языке ANY также часто используется в качестве универсального квантификатора. «Я могу победить ЛЮБОГО из вас» не является синонимом «Я могу победить НЕКОТОРЫХ из вас». Фактически, это синоним «Я могу победить ВСЕХ вас».
Поскольку ANY сбивает с толку, SOME был введен как более надежный синоним ANY с принятием стандарта SQL-92. ЛЮБОЙ должен был быть сохранен на некоторое время только для обратной совместимости с предыдущими версиями продукта. Но он у нас все еще есть сегодня.
4
Cristi S.
4 Авг 2016 в 23:17
SOME и ANY эквивалентны в стандарте SQL-92, поэтому, хотя он не отвечает на ваш вопрос, чтобы указать на это, он указывает на то, что история имеет долгую историю.
3
Steve Kass
5 Сен 2009 в 23:49
Помните, что некоторые продукты для баз данных существуют уже почти три десятилетия. Такие производители, как Oracle, IBM и Microsoft, всегда включали в свои продукты функции, которые впоследствии были включены в стандарт ANSI.
Иногда эти функции разрабатывались несколькими поставщиками независимо друг от друга, поэтому либо стандарт, либо поставщик должны были поддерживать синонимы для ключевых слов. Например, в Oracle задолго до того, как ANSI определил . Oracle поддерживает оба использования.
Я не знаю, применим ли аналогичный сценарий к НЕКОТОРЫМ и ЛЮБЫМ. Но это кажется вероятным.
2
APC
6 Сен 2009 в 09:29
6 ответов
Лучший ответ
Мне кажется, что наличие отдельного стола — это хорошо. Таким образом, вы можете сохранить только то, что было изменено, а не все остальное.
2
John
9 Сен 2009 в 21:48
Для простоты я часто использую столбец «статус» в базе данных, чтобы определить, доступна ли определенная строка для всеобщего просмотра. Затем в своем SQL вы должны добавить
Это хорошо работает для простых сайтов.
Для более загруженных сайтов я подозреваю, что отсутствие этого предложения WHERE дает некоторый выигрыш в производительности. Было бы неплохо иметь ожидающие изменения в отдельной таблице, а затем вы вставляете INSERT INTO … SELECT FROM, чтобы переместить его в живую таблицу.
2
Brandon
9 Сен 2009 в 21:52
Вы можете встроить немного рабочего процесса в свое приложение. Таким образом, у вас будет таблица рабочего процесса, в которой будут определены различные состояния (например, введено, предложено, одобрено и т. Д.).
Затем у вас также может быть таблица PendingChanges, в которой хранятся предлагаемые изменения. Когда предложенное изменение будет одобрено, вы объедините его с основным изменением профиля пользователя.
1
AngryHacker
9 Сен 2009 в 21:45
Если у вас много таких случаев (во многих разных таблицах), у вас может быть таблица TempObject, в которой вы сериализуете изменения в XML или какое-либо другое состояние до тех пор, пока они не будут утверждены.
Или, если это просто таблица профиля пользователя, у вас может быть уникальный ключ на UserID + Approved (логический). Когда пользователь редактирует свои данные, они попадают в таблицу как UserID, Approved = false, затем, чтобы утвердить его, вы просто удаляете одобренный и обновляете неутвержденный до одобренного (конечно, в транзакции).
В конце концов, у вас уже есть структура для хранения всех этих данных — почему бы не использовать ее повторно?
1
David Boike
9 Сен 2009 в 21:50
Это кажется самым простым: вы можете добавить поля VERSION и STATUS в таблицу USERS. Затем используйте поле STATUS, чтобы отобразить строку с наивысшей VERSIONed, если это необходимо. Очевидно, это также дает вам возможность управлять версиями записей.
Пока ВЕРСИЯ и СОСТОЯНИЕ проиндексированы, они не замедлят никаких операций отображения. Добавление строк будет немного медленнее, так как индексы необходимо поддерживать.
1
ndp
16 Сен 2009 в 05:54
Вторая таблица в том же формате, что и первая, не позволяет легко ставить в очередь несколько изменений.
Я бы рекомендовал разработать конкретную структуру для записи каждого запроса на изменение как запроса на изменение. Поля для кого это меняется, что меняется, к чему, кто сделал запрос, когда и т. Д.
Затем имейте код для применения изменения, если / после проверки.
Это также может быть легко отслеживаемым контрольным журналом.
Я бы не стал вносить изменения в одну и ту же таблицу, это сильно связывает реализации вместе и делает последующее обслуживание головной болью. Независимость снижает степень взаимозависимости, что обеспечивает большую гибкость в будущем.
MatBailie
9 Сен 2009 в 22:11
Точность с типов плавающей запятой
Рассмотрим дробь 1/3. Десятичное представление этого числа – 0,33333333333333… с тройками, уходящими в бесконечность. Если бы вы писали это число на листе бумаги, ваша рука в какой-то момент устала бы, и вы, в конце концов, прекратили бы писать. И число, которое у вас осталось, будет близко к 0,3333333333…. (где 3-ки уходят в бесконечность), но не совсем.
На компьютере число бесконечной длины потребует для хранения бесконечной памяти, но обычно у нас есть только 4 или 8 байтов. Эта ограниченная память означает, что числа с плавающей запятой могут хранить только определенное количество значащих цифр – и что любые дополнительные значащие цифры теряются. Фактически сохраненное число будет близко к необходимому, но не точно.
Точность числа с плавающей запятой определяет, сколько значащих цифр оно может представлять без потери информации.
При выводе чисел с плавающей точкой по умолчанию имеет точность 6, то есть предполагает, что все переменные с плавающей точкой имеют только до 6 значащих цифр (минимальная точность с плавающей точкой), и, следовательно, он будет отсекать всё, что идет дальше.
Следующая программа показывает усечение до 6 цифр:
Эта программа выводит:
Обратите внимание, что каждое из напечатанных значений имеет только 6 значащих цифр. Также обратите внимание, что в некоторых случаях переключился на вывод чисел в экспоненциальном представлении
В зависимости от компилятора показатель степени обычно дополняется до минимального количества цифр. Не беспокойтесь, 9.87654e+006 – это то же самое, что 9.87654e6, только с некоторым количеством дополнительных нулей. Минимальное количество отображаемых цифр показателя степени зависит от компилятора (Visual Studio использует 3, некоторые другие в соответствии со стандартом C99 используют 2)
Также обратите внимание, что в некоторых случаях переключился на вывод чисел в экспоненциальном представлении. В зависимости от компилятора показатель степени обычно дополняется до минимального количества цифр
Не беспокойтесь, 9.87654e+006 – это то же самое, что 9.87654e6, только с некоторым количеством дополнительных нулей. Минимальное количество отображаемых цифр показателя степени зависит от компилятора (Visual Studio использует 3, некоторые другие в соответствии со стандартом C99 используют 2).
Число цифр точности переменной с плавающей запятой зависит как от размера (у точность меньше, чем у ), так и от конкретного сохраняемого значения (некоторые значения имеют большую точность, чем другие). Значения имеют точность от 6 до 9 цифр, при этом большинство значений имеют не менее 7 значащих цифр. Значения имеют от 15 до 18 цифр точности, при этом большинство значений имеют не менее 16 значащих цифр. Значения имеет минимальную точность 15, 18 или 33 значащих цифр в зависимости от того, сколько байтов этот тип занимает.
Мы можем переопределить точность по умолчанию, которую показывает , используя функцию манипулятора вывода с именем . Манипуляторы вывода изменяют способ вывода данных и определяются в заголовке iomanip.
Вывод программы:
Поскольку с помощью мы устанавливаем точность в 16 цифр, каждое из приведенных выше чисел печатается с 16 цифрами. Но, как видите, числа определенно неточны до 16 цифр! А поскольку числа менее точны, чем числа , число ошибок у больше.
Проблемы с точностью влияют не только на дробные числа, они влияют на любое число со слишком большим количеством значащих цифр. Рассмотрим большое число:
Вывод программы:
123456792 больше, чем 123456789. Значение 123456789.0 имеет 10 значащих цифр, но значения обычно имеют точность 7 цифр (и результат 123456792 точен только до 7 значащих цифр). Мы потеряли точность! Когда теряется точность из-за того, что число не может быть точно сохранено, это называется ошибкой округления.
Следовательно, нужно быть осторожным при использовании чисел с плавающей запятой, которые требуют большей точности, чем могут содержать переменные.
Лучшая практика
Если нет ограничений по использованию памяти, отдавайте предпочтение использованию вместо , поскольку неточность часто приводит к погрешностям.
Типы данных SQL Server
Типы строковых данных:
| Тип данных | Описание | Максимальный размер | Хранения |
|---|---|---|---|
| char(n) | Фиксированная ширина символьной строки | 8,000 Символов | Определенная ширина |
| varchar(n) | Переменная ширина символьная строка | 8,000 Символов | 2 байта + количество символов |
| varchar(max) | Переменная ширина символьная строка | 1,073,741,824 Символов | 2 байта + количество символов |
| text | Переменная ширина символьная строка | 2GB of text data | 4 байта + количество символов |
| nchar | Фиксированная ширина строки Юникода | 4,000 Символов | Определенная ширина x 2 |
| nvarchar | Переменная ширина Юникод строка | 4,000 Символов | |
| nvarchar(max) | Переменная ширина Юникод строка | 536,870,912 Символов | |
| ntext | Переменная ширина Юникод строка | 2GB of text data | |
| binary(n) | Фиксированная ширина двоичной строки | 8,000 bytes | |
| varbinary | Переменная ширина двоичная строка | 8,000 bytes | |
| varbinary(max) | Переменная ширина двоичная строка | 2GB | |
| image | Переменная ширина двоичная строка | 2GB |
Типы данных чисел:
| Тип данных | Описание | Хранения |
|---|---|---|
| bit | Целое число, которое может быть 0, 1 или null | |
| tinyint | Позволяет целые числа от 0 до 255 | 1 byte |
| smallint | Позволяет целые числа между -32 768 и 32 767 | 2 bytes |
| int | Позволяет целые числа между -2 147 483 648 и 2 147 483 647 | 4 bytes |
| bigint | Позволяет целые числа между -9223372036854775808 и 9 223 372 036 854 775 807 | 8 bytes |
| decimal(p,s) | Fixed precision and scale numbers.
Разрешает числа от-10 ^ 38 + 1 до 10 ^ 38 – 1. Параметр p указывает максимальное общее количество цифр, которые могут быть сохранены (как слева, так и справа от десятичной запятой). p должно быть значением от 1 до 38. Значение по умолчанию — 18. Параметр s указывает максимальное число цифр, хранящихся справа от десятичной запятой. s должно быть значением от 0 до p. значение по умолчанию 0 |
5-17 bytes |
| numeric(p,s) | Фиксированные значения точности и масштаба.
Разрешает числа от-10 ^ 38 + 1 до 10 ^ 38 – 1. Параметр p указывает максимальное общее количество цифр, которые могут быть сохранены (как слева, так и справа от десятичной запятой). p должно быть значением от 1 до 38. Значение по умолчанию — 18. Параметр s указывает максимальное число цифр, хранящихся справа от десятичной запятой. s должно быть значением от 0 до p. значение по умолчанию 0 |
5-17 bytes |
| smallmoney | Денежные данные от-214 748,3648 до 214 748,3647 | 4 bytes |
| money | Денежные данные от-922 337 203 685 477,5808 до 922 337 203 685 477,5807 | 8 bytes |
| float(n) | Плавающая точность данных чисел от-1.79 e + 308 до 1.79 e + 308.
Параметр n указывает, должно ли поле содержать 4 или 8 байт. float (24) содержит 4-байтное поле и float (53) содержит 8-байтное поле. Значение по умолчанию n — 53. |
4 or 8 bytes |
| real | Плавающие данные о точности чисел от-38 e + | 4 bytes |
Типы данных дат:
| Тип данных | Описание | Хранения |
|---|---|---|
| datetime | С 1 января 1753 по 31 декабря 9999 с точностью 3,33 миллисекунд | 8 bytes |
| datetime2 | С 1 января 0001 по 31 декабря 9999 с точностью 100. | 6-8 bytes |
| smalldatetime | С 1 января 1900 по 6 июня 2079 с точностью до 1 минуты | 4 bytes |
| date | Хранить только дату. С 1 января 0001 по 31 декабря 9999 | 3 bytes |
| time | Хранить время только для точности 100-ти секунд | 3-5 bytes |
| datetimeoffset | Так же, как datetime2 с добавлением смещения часового пояса | 8-10 bytes |
| timestamp | Хранит уникальный номер, который обновляется каждый раз при создании или изменении строки. Значение timestamp основывается на внутренних часах и не соответствует реальному времени. Каждая таблица может иметь только одну переменную timestamp |
Другие типы данных:
| Тип данных | Описание |
|---|---|
| sql_variant | Хранит до 8 000 байт данных различных типов данных, за исключением текста, ntext и отметки времени |
| uniqueidentifier | Хранит глобальный уникальный идентификатор (GUID) |
| xml | Хранит XML-форматированные данные. Максимум 2 ГБ |
| cursor | Хранит ссылку на курсор, используемый для операций с базой данных |
| table | Хранит результирующий набор для последующей обработки |
Поля, представляемые в базе данных
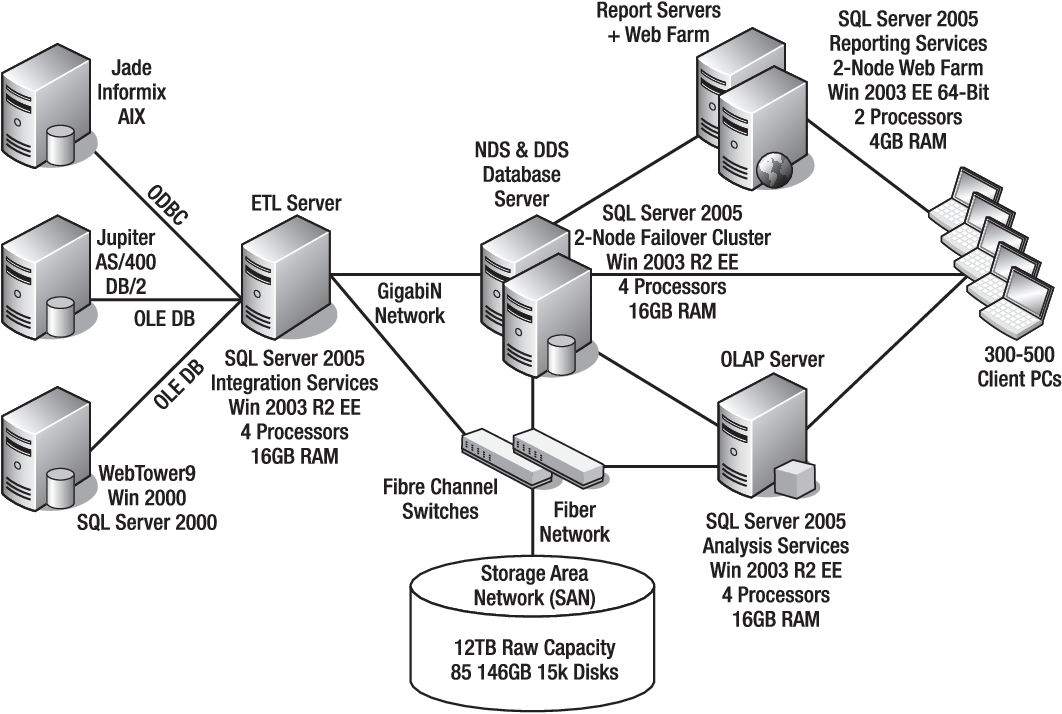
Многие из объектов метаданных, с которыми работает 1С:Предприятие 8, определяют таблицы и поля базы данных. Ниже приведен список таких объектов метаданных с указаниями, какие объекты базы данных они определяют:
- План обмена — таблица.
- Реквизит — поле.
- Табличная часть — таблица.
- Справочник — таблица.
- Реквизит — поле.
- Табличная часть — таблица.
- Документ — таблица.
- Реквизит — поле.
- Табличная часть — таблица.
- Последовательность — таблица.
- Журнал документов — таблица.
- Перечисление — таблица.
- План видов характеристик — таблица.
- Реквизит — поле.
- Табличная часть — таблица.
- План счетов — таблица.
- Реквизит — поле.
- Признак учета — поле.
- Признак учета субконто — поле (специализированной табличной части).
- Табличная часть — таблица
- План видов расчета — таблица.
- Реквизит — поле.
- Табличная часть — таблица.
- Регистр сведений — таблица.
- Измерение — поле.
- Ресурс — поле.
- Реквизит — поле.
- Регистр накопления — таблица.
- Измерение — поле.
- Ресурс — поле.
- Реквизит — поле.
- Регистр бухгалтерии — таблица.
- Измерение — поле.
- Ресурс — поле.
- Реквизит — поле.
- Регистр расчета — таблица.
- Измерение — поле.
- Ресурс — поле.
- Реквизит — поле.
- Перерасчет — таблица.
- Бизнес-процесс — таблица.
- Реквизит — поле.
- Табличная часть — таблица.
- Задача — таблица.
- Реквизит адресации — поле.
- Реквизит — поле.
- Табличная часть — таблица.
Подробнее о соответствии таблиц базы данных объектам метаданных описано в разделе «Размещение данных 1С:Предприятия 8». В нем особый интерес представляют те объекты метаданных, которые определяют поля базы данных.
Объекты репликации
Максимальные размеры и количества для различных объектов, определяемых в компонентах репликации SQL Server .
| SQL Server Объект Replication | Максимальные размеры и количества для SQL Server (64-разрядная версия) |
|---|---|
| Статей (публикация слиянием) | 2048 |
| Статей (моментальный снимок или публикация транзакций) | 32 767 |
| Столбцов в таблице* (публикация слиянием) | 246 |
| Столбцов в таблице** (моментальный снимок или публикация транзакций SQL Server) | 1000 |
| Столбцов в таблице** (моментальный снимок или публикация транзакций Oracle) | 995 |
| Байтов на столбец, используемый в фильтре строк (публикация слиянием) | 1024 |
| Байтов на столбец, используемый в фильтре строк (моментальный снимок или публикация транзакций) | 8000 |
* Если для обнаружения конфликтов применяется трассировка на уровне строк (по умолчанию), базовая таблица может содержать не более 1024 столбцов, однако столбцы из статьи должны быть отфильтрованы, чтобы было опубликовано не более 246 столбцов. Если применяется трассировка на уровне столбцов, базовая таблица может содержать не более 246 столбцов.
** Базовая таблица может включать максимальное количество столбцов, разрешенное в базе данных публикации (1024 для SQL Server), но столбцы должны быть отфильтрованы из статьи, если они превышают максимальное количество, заданное для данного типа публикации.





