
Проверка Email
Описание:
Начнем с указания parser найти начало строки (^). Внутри первой группы мы сопоставляем одну или несколько строчных букв, цифр, символов подчёркивания, точек или дефисов. Я убрал точки, потому что открытая точка означает любой символ. Сразу после этого должен быть знак «at». Далее следует имя домена, которое должно быть: одна или несколько строчных букв, цифр, символов подчёркивания, точек или дефисов. Затем (экранированная) точка, с расширением от двух до шести букв или точек. У меня от 2 до 6 из-за специфических для страны TLD (.ny.us или .co.uk). В финале нам нужен конец строки ($).
Состав
Типичный URL-адрес, содержащий строку запроса, выглядит следующим образом:
Когда сервер получает запрос на такую страницу, он может запускать программу, передавая строку запроса, которая в данном случае остается неизменной для программы. Знак вопроса используется как разделитель и не является частью строки запроса.
Веб-платформы могут предоставлять методы для анализа нескольких параметров в строке запроса, разделенных некоторым разделителем. В приведенном ниже примере URL-адреса несколько параметров запроса разделены амперсандом » «:
Точная структура строки запроса не стандартизирована. Методы, используемые для синтаксического анализа строки запроса, могут различаться на разных веб-сайтах.
Ссылка на веб-странице может иметь URL-адрес, содержащий строку запроса. HTML определяет три способа, которыми пользовательский агент может генерировать строку запроса:
- HTML — формы с помощью элемента
- с помощью атрибута на элементе с конструкцией
- индексированный поиск через устаревший элемент
Веб-формы
Одно из первоначальных применений заключалось в том, чтобы содержать содержимое HTML-формы , также известной как веб-форма. В частности, когда форма , содержащая поля , , представляется, содержание полей кодируется в виде строки запроса следующим образом :
- Строка запроса состоит из серии пар «поле-значение».
- В каждой паре имя поля и значение разделяются знаком равенства » «.
- Серии пар разделяются амперсандом » » (или точкой с запятой » » для URL-адресов, встроенных в HTML и не генерируемых a . См. Ниже).
Хотя окончательного стандарта не существует, большинство веб-фреймворков позволяют связывать несколько значений с одним полем (например, ).
Для каждого поля формы строка запроса содержит пару . Веб-формы могут включать поля, которые не видны пользователю; эти поля включаются в строку запроса при отправке формы.
Это соглашение является рекомендацией W3C . W3C рекомендует, чтобы все веб-серверы поддерживали разделители точек с запятой в дополнение к разделителям амперсандов, чтобы разрешить строки запроса с кодом application / x-www-form-urlencoded в URL-адресах в документах HTML без необходимости экранирования амперсандов.
Содержимое формы кодируется в строке запроса URL-адреса только в том случае, если метод отправки формы — GET . Такая же кодировка используется по умолчанию, когда метод отправки — POST , но результат отправляется как тело HTTP-запроса, а не включается в измененный URL-адрес.
Индексированный поиск
До того, как формы были добавлены в HTML, браузеры отображали элемент как однострочный элемент управления вводом текста. Текст, введенный в этот элемент управления, был отправлен на сервер как дополнение строки запроса к запросу GET для базового URL-адреса или другого URL-адреса, указанного в атрибуте. Это было предназначено для того, чтобы позволить веб-серверам использовать предоставленный текст в качестве критериев запроса, чтобы они могли возвращать список совпадающих страниц.
Когда текст, вводимый в элемент управления индексированным поиском, передается, он кодируется как строка запроса следующим образом:
- Строка запроса состоит из серии аргументов путем разбора текста на слова в пробелах.
- Серии разделяются знаком плюс , ‘ ‘.
Хотя этот элемент устарел, и большинство браузеров больше не поддерживают и не отображают его, все еще существуют остатки индексированного поиска. Например, это источник специальной обработки знака «плюс » в процентной кодировке URL-адресов браузера (которая сегодня, с отказом от индексированного поиска, практически избыточна ). Также некоторые веб-серверы, поддерживающие CGI (например, Apache ), будут преобразовывать строку запроса в аргументы командной строки, если она не содержит знака равенства ‘ ‘ (согласно разделу 4.4 CGI 1.1). Некоторые сценарии CGI по-прежнему зависят от этого исторического поведения и используют его для URL-адресов, встроенных в HTML.
Советы
Старайтесь составлять простые регулярные выражения, чтобы другим пользователям было легче интерпретировать и изменять их.
Используйте обратную косую черту (\) для обозначения метасимволов регулярных выражений, которые нужно интерпретировать буквально. Например, если вы используете точку в качестве десятичного разделителя в IP-адресе, исключите ее с помощью обратной косой черты (\.), чтобы она не читалась как подстановочный знак.
Регулярные выражения не обязательно должны содержать метасимволы. Например, вы можете создать сегмент для всех данных из Индии со следующими условиями фильтрации: Страна соответствует регулярному выражению Индия.
Регулярные выражения по умолчанию имеют максимально возможный охват. Если явные ограничения не заданы, то будет найдена указанная последовательность символов в окружении любых смежных с ними. Например, регулярному выражению site соответствуют слова mysite, yoursite, theirsite, parasite (то есть любые строки, где содержится site). Если вы ищете конкретную строку, задайте регулярное выражение с соответствующими ограничениями. Чтобы найти именно слово site, обозначьте, что оно должно стоять одновременно в начале и конце строки: ^site$.
Регулярные выражения
Известно, что регулярные выражения уже плотно вошли в нашу жизнь. И не надо быть программистом, чтобы знать, что их лучше знать.
В формулах Таблиц Google широко используется формальный язык поиска и осуществления манипуляций с подстроками в тексте. Проще говоря, регулярные выражения
. Эти выражения имеют синтаксис из библиотеки RE2
.
Вообще, регулярное выражение — это строка, которая указывает на некоторую группу строк, которым оно, регулярное выражение, соответствет. Например, выражению соответствует строка “арбуз”, а выражению — любая строка, которая содержит один или более символов русского алфавита и заканчивается на букву “з”, это и “арбуз”, и “заказ”, и “порез” и т.д.
Что это дает?
Зная регулярное выражение можно:
- Проверить наличие подстроки в строке
- Выбрать или посчитать изначально неопределенное количество строк, соответствующих регулярному выражению
- Произвести подстановку или замену одних символов на другие, одну группу символов на другую
Основные формулы, которые используют регулярные выражения:
-
REGEXMATCH
— проверяет соответствие строки заданному регулярному выражению -
REGEXEXTRACT
— пытается извлечь подстроку, соответствующую регулярному выражению -
REGEXREPLACE
— заменяет строки согласно регулярному выражению
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
7 ответов
Лучший ответ
Действительно, нет определенного стандарта. Чтобы подтвердить эту информацию, загляните в Википедию в главе Строка запроса. Вот такой комментарий:
Кроме того, если вы посмотрите на RFC 3986, в разделе , нет определения для параметров с несколькими значениями.
Большинство приложений используют первый из показанных вами вариантов: . Чтобы подтвердить эту информацию, взгляните на эту ссылку на Stackoverflow , и эту ссылку MSDN относительно ASP. NET, которые используют один и тот же стандарт для параметров с несколькими значениями.
Однако, поскольку вы разрабатываете API, я предлагаю вам сделать то, что для вас проще всего, поскольку у вызывающего API не будет особых проблем с созданием строки запроса.
189
Community
23 Май 2017 в 11:47
Я бы посоветовал посмотреть, как браузеры обрабатывают формы по умолчанию. Например, посмотрите на элемент формы и то, как он обрабатывает несколько значений из этого примера в w3schools.
Для использования PHP:
Если сверху щелкнуть «saab, opel» и нажать «Отправить», будет получен результат cars = saab & cars = opel . Затем, в зависимости от внутреннего сервера, параметр cars должен отображаться как массив, который вы можете обрабатывать в дальнейшем.
Надеюсь, это поможет любому, кто ищет более «стандартный» способ решения этой проблемы.
6
phanf
8 Май 2019 в 21:10
Я описываю простой метод, который очень плавно работал в Python (Django Framework).
1. Отправляя запрос, отправляйте его так:
2. Теперь в моем бэкэнде я разделяю полученное значение с помощью функции разделения, которая всегда создает список.
Пример: Итак, если я отправлю два значения в запросе,
Тогда фильтр данных
Если я отправлю только одно значение в запросе,
Тогда результат фильтра
3. Чтобы отфильтровать данные, я просто использую функцию «in»
Который, грубо говоря, выполняет SQL-эквивалент
С первым запросом и,
Со вторым запросом.
Это также будет работать с более чем двумя значениями параметров в запросе!
6
MGLondon
21 Июл 2020 в 13:38
Вышеупомянутые решения не сработали. Он просто отображал последние пары ключ / значение, но это действительно так:
Возврат:
1
Robert Sinclair
15 Фев 2021 в 16:17
Мой ответ больше ориентирован на PHP .
Отправка полей формы с несколькими значениями, то есть отправка массивов, может быть выполнена несколькими различными способами , поскольку стандарт не обязательно оговаривается.
Три возможных способа отправки многозначных полей или массивов:
- ? cars [] = Saab & cars [] = Audi (лучший способ — PHP считывает это в массив)
- ? cars = Saab & cars = Audi (Плохой путь — PHP регистрирует только последнее значение)
- ? cars = Saab, Audi (Общий способ — вам нужно взорвать строку, чтобы получить значения в виде массива)
Например :
Возврат
(ПРИМЕЧАНИЕ
В этом случае важно присвоить ключ запроса some_name [], чтобы результирующие переменные запроса регистрировались PHP как массив). 1
Shakil Alam
6 Апр 2021 в 06:44
1
Shakil Alam
6 Апр 2021 в 06:44
Поскольку URL-адрес является одним параметром и несколькими значениями. Очень простое решение в java — разделить строку, а затем добавить ее к себе. Например ниже:
Dharman
4 Июн 2021 в 11:11
Стандарта нет, но большинство фреймворков поддерживают оба, например, для java spring вы можете видеть, что он принимает оба
И Spring MVC отобразит параметр идентификатора, разделенный запятыми:
Или список отдельных параметров id:
Ousama Hadj Aissa
23 Июл 2020 в 10:08
Примеры использования регулярных выражений
Проверка e-mail
Как проверить, действителен ли адрес электронной почты, введенный пользователем в соответствующее поле на сайте?
/+.+.{2,4}/igm
Проверка телефонных номеров
Этот пример может применяться для проверки любого телефонного номера:
^\+?\d{1,3}??\(?(?:\d{2,3})\)??\d\d\d?\d\d\d\d$
Проверка телефонного номера с кодом конкретной страны (например, Украины):
^((\+?3|8) ?)?((\(\d{3}\))|(\d{3}))?()?(\d{3}?\d{2}?\d{2})$
Проверка строки с адресом видео на YouTube
Подходит для всех URL-адресов на YouTube:
/http:\/\/(?:youtu\.be\/|(?:{2,3}\.)?youtube\.com\/watch(?:\?|#\!)v=)({11}).*/gi
Проверка формата URL
Проверяет URL-адреса на соответствие синтаксису доменов. Учитывает протоколы HTTP и HTTPS:
/:%_\+.~#?&//=]{2,256}\.{2,4}\b(\/:%_\+.~#?&//=]*)?/gi
Проверка текста на повторяющиеся слова
Поиск соответствий на повторяющиеся слова:
\b(\w+)\s+\b
\b — это граница слова, а \1 — ссылка на зафиксированное совпадение (первое слово).
Синтаксис поисковых запросов Google
Это выражение может стать основой для создания собственного алгоритма поиска. «+» добавляет ключевые слова, «–» — исключает слова из результатов выдачи:
/(?(?:'.+?'|".+?"|{1}*))/g
Проверка имени пользователя
Username может включать буквы, цифры и символы, такие как: «–», «_», «*». Наборы допустимых в имени символов так же, как и длину строки, можно задавать самостоятельно:
/^{3,16}$/
где:
- ^ — начало строки;
- _-* — набор допустимых символов;
- 3,16 — длина строки;
- $ — конец строки.
Проверка надежности паролей
Чтобы создать надежный пароль, необходимо придерживаться некоторых стандартов — использовать помимо букв и цифр другие символы в разных регистрах, а также спецзнаки. Это регулярное выражение уже содержит необходимые требования для проверки надежности паролей:
/^(?=.*.*)(?=.*#$&*])(?=.*.*)(?=.*.*.*).{8,}$/
Проверка номера кредитной карты
С помощью регулярных выражений можно исключить номера платежных карт, в которых содержатся умышленные или случайные ошибки, неправильные последовательности введенных цифр:
/^(?:4{12}(?:{3})?|5{14}|6(?:011|5){12}|3{13}|3(?:0|){11}|(?:2131|1800|35\d{3})\d{11})$/
Проверка цен
Цены имеют множество представлений и форматов. Единого регулярного выражения для них не существует. Приведем пример выражения для извлечения из текста цен в долларовом эквиваленте:
/($+(\.{2})?)/
где {2} — комбинация, которая указывает на то, что символ из должен повториться дважды (дробная часть цены).
Внимание! Регулярные выражения имеют в своем арсенале специальные символы, которые в обязательном порядке необходимо экранировать. В этот список входят:
^ $ * + ? { } \ | ( ). Перед каждым таким символом необходимо добавлять обратный слэш \.
Согласование Hex Value
Описание:
Начнём с указания parser найти начало строки (^). Затем знак числа является необязательным, поскольку за ним следует вопросительный знак. Вопросительный знак говорит parser, что предыдущий символ — в данном случае знак числа — является необязательным, но чтобы был «жадным» и отметил его, если он есть. Далее, внутри первой группы (первая группа круглых скобок) мы можем иметь две разные ситуации. Первая — любая буква в нижнем регистре между a и f или число шесть раз. Вертикальная полоса говорит нам, что мы можем также иметь три строчные буквы между a и f или номерами. Наконец, нам нужен конец строки ($).
Причина, по которой я ставил шесть символов перед этим, заключается в том, что parser запишет значение hex value типа #ffffff. Если бы я перевернул его так, чтобы три символа стали первыми, parser мог бы получить только #fff, а не другие три f.
Что означают символы в регулярных выражениях и как их использовать
Вертикальная линия |
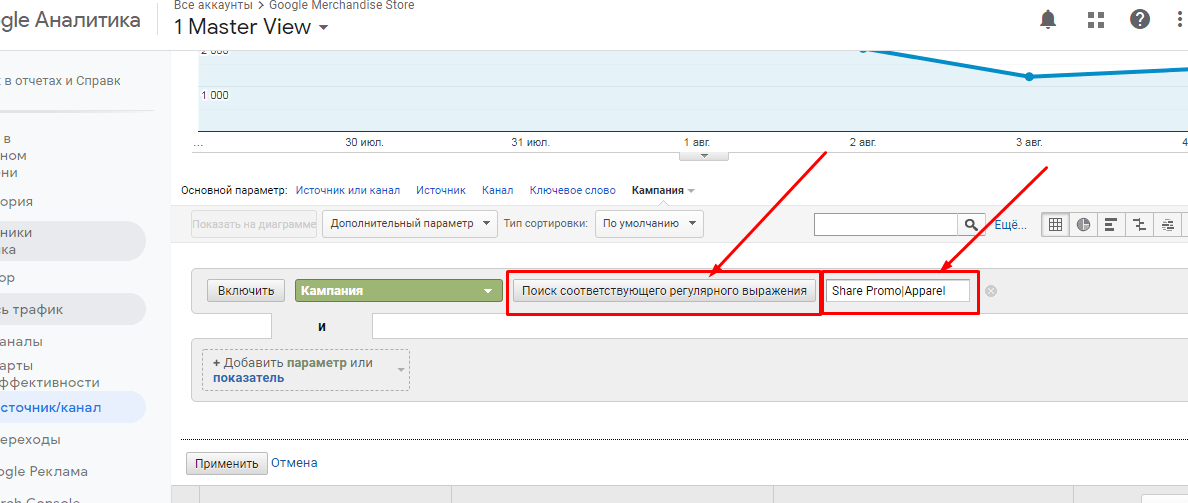
Означает «или». Символ можно использовать, например, когда нужно искать сразу по двум рекламным кампаниям. Допустим, они называются Share promo и Apparel. Чтобы найти информацию в Share или Apparel, нужно написать:
Share promo|Apparel
Означает один любой символ. Если вам нужно найти слова «тлен», «клен», «плен», пишите так:
.лен
Звездочка *
Означает повторение предыдущего символа ноль или больше раз. Например, если вам нужно найти gogle, google, gooogle, goooogle, пишите так:
goo*gle


Чаще всего звездочку используют в паре с точкой или в составе других регулярных выражений.
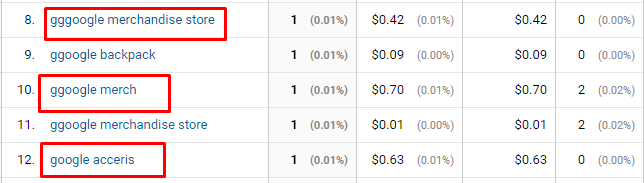
Знак плюс +
Похож на звездочку, но соответствует одному или более предыдущим символам. Если вам нужно найти gggoogle, ggoogle, google, пишите так:
g+oogle

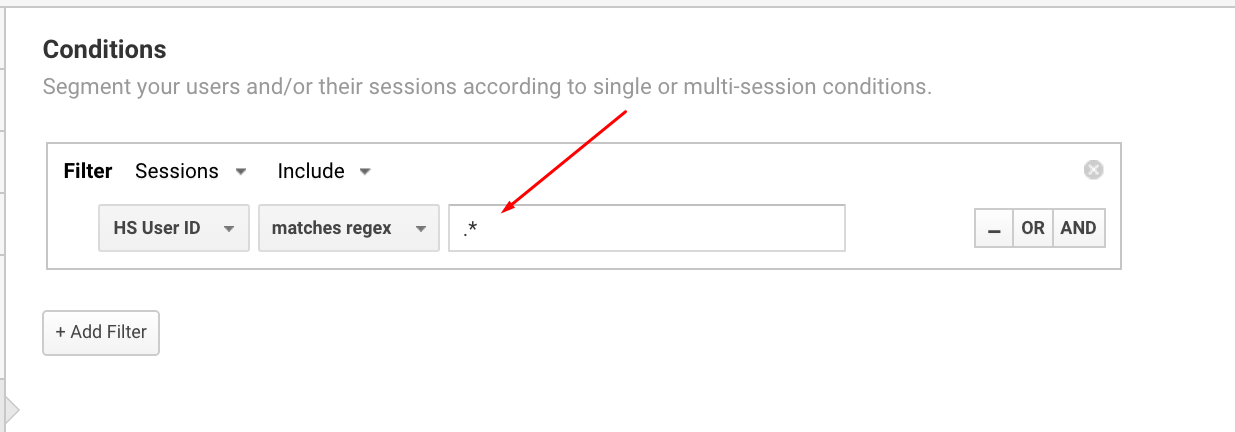
Точка звездочка .*
Выражение соответствует нулю или большему количеству случайных символов. Если проще — любой комбинации символов или отсутствию символов. Регулярное выражение можно использовать в Google Analytics, например, чтобы настроить сегменты пользователей с User ID.
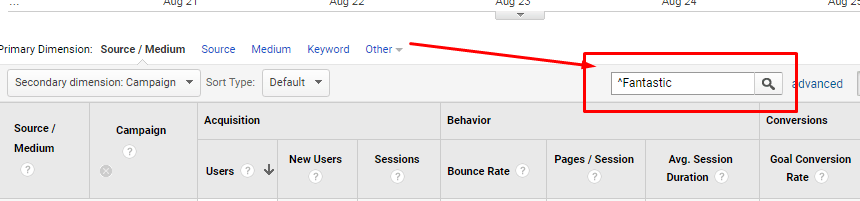
Каретка ^
Помогает найти текст, который начинается с определенной фразы или слова. Например, у вас запущено несколько рекламных кампаний с похожими названиями: Fantastic campaign end, Our Fantastic campaign, The best Fantastic campaign, Test Fantastic campaign. И нужно найти именно Fantastic campaign end. В таком случае пишем:
^Fantastic campaign
Символ доллар $
Работает наоборот и помогает найти название, которое заканчивается на определенный символ или слово. Рассмотрим тот же пример с кампаниями Fantastic campaign end, Our Fantastic campaign, The best Fantastic campaign, Test Fantastic campaign. Чтобы найти первую, нужно написать:
campaign end$
Вопросительный знак ?
Означает, что символ перед ним не обязательный. Например, вам нужно найти все кампании, связанные с фирмой Kerrigan и ее брендом rainnor. Но вы не уверены, что названия правильно пишутся с двумя rr и двумя nn. В этом случае ищите так:
Kerr?igan|rainn?or

Вы получите все кампании, со словами Kerrigan, Kerigan, rainnor и rainor
Скобки ()
Круглые скобки отделяют одну часть выражения от другой. Допустим, у вас есть три разных страницы — мужская, женская и детская обувь, и вы хотите получить данные о них одним запросом.
Адреса страниц выглядят так:
- /products/men/shoes/
- /products/women/shoes/
- /products/kids/shoes/
Нужно найти страницы, которые начинаются с /products, заканчиваются на shoes/, а между этими словами содержат men или women или kids. Для решения задачи используйте регулярно выражение:
^/products/(men|women|kids)/shoes/$


Квадратные скобки []
Квадратные скобки помогают создать список. Например, у вас есть три слова baker341, baker342, baker343. Чтобы найти их все за раз, напишите:
baker34


Аналогично можно искать слова на кириллице. Чтобы найти сон, тон и фон, пишем он.
Дефис —
Помогает создать продвинутый список, его лучше использовать вместе с квадратными скобками:
- соответствует всем строчным буквам;
- соответствует всем заглавным буквам;
- соответствует всем числам;
- соответствует всем буквам и цифрам.
Допустим, вам нужно вывести все ourCampaign, в названии которых есть даты с 2013 по 2019 год. Пишем так:
ourCampaign201
Фигурные скобки { }
Указывают, сколько раз нужно повторить предыдущий символ или выражение.
- {1,2} — нужно повторить последний «пункт» не менее 1 раза и не более 2 раз.
- {2} — нужно повторить последний «пункт» 2 раза.
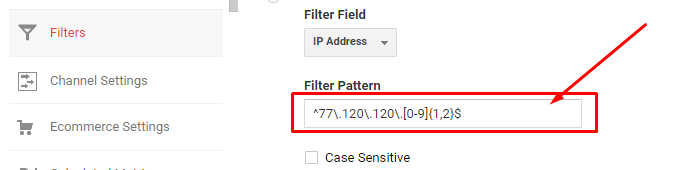
Например, нужно выбрать список IP адресов определенного диапазона с 77.120.120.0 по 77.120.120.99. Если вводить их вручную, придется писать 100 разных адресов. С помощью регулярного выражения можно обойтись одной строкой: \
^77\.120\.120\.{1,2}$
Обратная косая черта \
Существует много символов регулярных выражений, которые встречаются и в простом тексте — точка, знак вопроса, дефис и другие. С помощью обратной косой черты можно указать, что эти символы часть текста, а не регулярного выражения.
Допустим, нужно отфильтровать все строки запроса в Google Analytics, которые начинаются с / search /? s = (URL поиска на сайте). Регулярное выражение будет выглядеть так:
search \ / \? s =
Проверка URL
Описание:
Это regex почти походит к заключительной части вышеупомянутого регулярного выражения, собрав его между «http: //» и некоторой структурой файла в конце. Это звучит намного проще, чем есть на самом деле. Для начала мы ищем начало строки с помощью каретки.
Первая группа охвата — это все опции. Он позволяет URL-адресу начинаться с «http: //», «https: //» или без них. У меня вопросительный знак после s, чтобы разрешить URL-адреса с http или https. Чтобы сделать всю эту группу необязательной, я просто добавил вопросительный знак к её концу.
Далее идет доменное имя: одно или несколько чисел, букв, точек или дефисов, за которыми следует другая точка, затем от двух до шести букв или точек. Следующий раздел — это необязательные файлы и каталоги. Внутри группы мы хотим сопоставить любое количество косой черты, буквы, цифры, символы подчёркивания, пробелы, точки или дефисы. Затем мы говорим, что эту группу можно сопоставлять столько раз, сколько мы хотим. В значительной степени это позволяет совместить несколько каталогов вместе с файлом в конце. Я использовал звезду вместо вопросительного знака, потому что звезда говорит ноль или больше, а не ноль или один. Если бы в нём использовался вопросительный знак, мог быть сопоставлен только один файл/каталог.
Затем завершающая косая черта сопоставляется, но она может быть необязательной. Наконец, мы заканчиваем с концом строки.
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Ограничения
Особых ограничений и недостатков RE2 не имеет. Но существуют типы задач, которые эта билиотека без внешнего кода решить не может.
Задача на удаление повторов
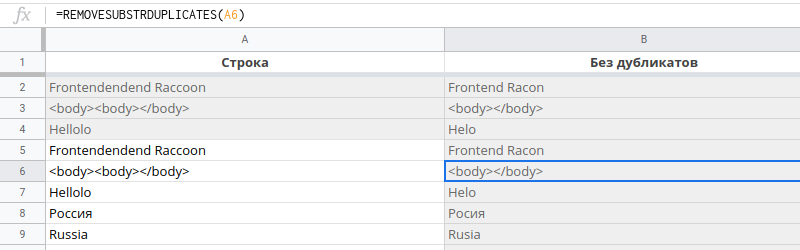
Положим, у нас есть строка . Из спецификации языка HTML известно, что тег может присутствавать в документе только однажды. Очевидно, что отдно из лишнее.
Элегатно решить эту задачу можно через регулярные выражения, если обратиться к найденной подстроке тут же в регулярном выражении.
- И так. Найдем какую-то строку .
- Хм, пусть символов будет один или больше .
- Ок. Теперь запомним ее .
- Магия на следующем шаге.
- Обратимся к запомненному элементу .
- Если этих элементов больше 2, тогда учтем и это .
Ближайшая комбинация, которая удовлетворит этому выражению — это строка .
Скрипт для пользовательской функции может иметь вид
Какие параметры запросов исключать
Из отчетов надо исключать параметры второго вида, то есть те, которые не влияют на работу сайта, но передают дополнительные параметры.
Но перед удалением параметров обязательно надо обсудить с командой проекта, не связан ли какой-нибудь отчет с этими параметрами.
Ниже пример параметров, которые мы обычно исключаем:
utm_banner,_openstat,mixid,field_city_tid,yclid,block,pos,utm_adid,field_,fb_comment_id,field_works_value,Firstname,utm_keyword,pm_source,pm_block,pm_position,roistat,roistat_referrer,roistat_pos,campaignid,adgroupid,loc_physical_ms,device,placement,phone,Phone,fmode,back_url_admin,pageurl,comment_id,type,url,cm_id,p,rb_clickid,type,source,added,block,pos,key,campaign,retargeting,ad,phrase,gbid,device,region,region_name,redir-setuniq,yclid,target_ref,turbo_url,mlid,msid,lr,t,stid,from,lang,target_ref
Без предварительной подготовки из отчетов не рекомендуется исключать параметры, которые влияют на работу сайта: пагинация, фильтрация, сортировка, действия пользователей. Так как эти параметры могут служить хорошим источником информации для разных исследований и гипотез. Например, какие фильтры с какими значениями предпочитают выбирать пользователи из разных рекламных кампаний.
Отойду от темы и скажу, что часть информации из параметров лучше отправлять в пользовательские параметры. Но это тема отдельной статьи.
Отслеживание
Программа, получающая строку запроса, может игнорировать ее частично или полностью. Если запрошенный URL-адрес соответствует файлу, а не программе, вся строка запроса игнорируется. Однако, независимо от того, используется строка запроса или нет, весь URL-адрес, включая его, сохраняется в файлах журнала сервера .
Эти факты позволяют использовать строки запроса для отслеживания пользователей аналогично тому, как это предусмотрено файлами cookie HTTP . Чтобы это работало, каждый раз, когда пользователь загружает страницу, необходимо выбирать уникальный идентификатор и добавлять его в качестве строки запроса к URL-адресам всех ссылок, содержащихся на странице. Как только пользователь переходит по одной из этих ссылок, соответствующий URL запрашивается на сервере. Таким образом, загрузка этой страницы будет связана с предыдущей.
Например, когда запрашивается веб-страница, содержащая следующее:
<a href="foo.html">see my page!</a> <a href="bar.html">mine is better</a>
выбирается уникальная строка, например, как , и страница изменяется следующим образом:
<a href="foo.html?e0a72cb2a2c7">see my page!</a> <a href="bar.html?e0a72cb2a2c7">mine is better</a>
Добавление строки запроса не меняет способ отображения страницы пользователю. Когда пользователь следует, например, по первой ссылке, браузер запрашивает страницу на сервере, который игнорирует то, что следует, и отправляет страницу, как ожидалось, добавляя строку запроса к своим ссылкам.
Таким образом, любой последующий запрос страницы от этого пользователя будет содержать ту же строку запроса , что позволит установить, что все эти страницы были просмотрены одним и тем же пользователем. Строки запроса часто используются вместе с веб-маяками .
Основные различия между строками запроса, используемыми для отслеживания, и файлами cookie HTTP заключаются в следующем:
- Строки запроса составляют часть URL-адреса и поэтому включаются, если пользователь сохраняет или отправляет URL-адрес другому пользователю; Файлы cookie могут поддерживаться во время сеансов просмотра, но не сохраняются и не отправляются с URL-адресом.
- Если пользователь попадает на один и тот же веб-сервер двумя (или более) независимыми путями, ему будут назначены две разные строки запроса, а сохраненные файлы cookie будут одинаковыми.
- Пользователь может отключить файлы cookie, и в этом случае использование файлов cookie для отслеживания не работает. Однако использование строк запроса для отслеживания должно работать во всех ситуациях.
- Различные строки запроса, передаваемые при разных посещениях страницы, будут означать, что страницы никогда не обслуживаются из кеша браузера (или прокси-сервера, если он есть), тем самым увеличивая нагрузку на веб-сервер и замедляя взаимодействие с пользователем.
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Что делать с параметрами
Самое просто решение — исключать их из отчетов Google Analytics. При этом исключаются не сами взаимодействия, а удаляются параметры из URL-адресов страниц, “приклеивая” оставшуюся информацию к основной странице. То есть, если в отчете есть информация о 10 взаимодействиях с основной страницей и информация о 10 взаимодействиях с параметрами этой страницы, после исключения параметров мы получим 20 взаимодействий с основной страницей.
Google Analytics по умолчанию сам умеет исключать параметры (_ga, UTM-метки). Для исключения других параметров в Google Analytics есть удобный встроенный инструмент исключения параметров запросов URL. Находится он в разделе “Администратор > Представление > Настройки представления”.
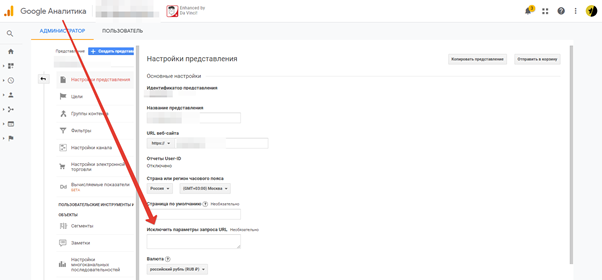
Достаточно указать в данном поле через запятую все параметры, которые надо исключать из отчетов, и в момент внесения изменений данные в представлении будут отображаться без параметров.
Тут стоит сделать две важные ремарки:
Хорошим тоном для работы со счетчиками Google Analytics является создание двух представлений: чистое представление, данные в котором не меняются, и “рабочее” представление, в которое вносятся все правки
Это важно, так как изменение данных на уровне представления откатить нельзя, и, если появится какая-то ошибка, правильные данные можно извлечь из чистого представления.
Иногда я слышу опасения, что исключение параметров может исказить отчетность. Этого можно не бояться, так как распределение данных по отчетам Google Analytics проводит на этапе обработки сырых данных
Сначала Google Analytics распределит данные по отчетам, а только потом исключит все указанные параметры.
Регулярные выражения Key Collector
При помощи регулярных выражений в Key Collecor можно составлять сложные конструкции для фильтрации данных. При использовании фильтра по регулярному выражению используется стандартный синтаксис RegExp.
Популярные варианты использования регулярных выражений:
-
\d+ — выбрать все фразы, содержащие цифры;
-
^скачать — выбрать все фразы, начинающиеся со слова «скачать»;
-
скачать$ — выбрать все фразы, заканчивающиеся на слово «скачать»;
-
скачать — выбрать все фразы, содержащие слово «скачать»;
-
скачать|купить|продать — выбрать все фразы, содержащие любое из слов «скачать», «купить» или «продать»;
-
^пластиковые(.*)цены$ — выбрать все фразы, начинающиеся на «пластиковые» и заканчивающиеся на «цены». Комбинация (.*) в регулярном выражении означает последовательность символов любой длины.
-
^(\S+\s\S+)$ — выбрать все фразы, содержащие точно два слова;
-
^(\S+\s\S+\s\S+)$ — выбрать все фразы, содержащие точно три слова; таким образом можно собрать фразы, содержащие до пяти конкретных слов.
Использование фильтра в Key Collector: выражение выберет все фразы, начинающиеся на «пластиковые» и заканчивающиеся на «цены». Комбинация (.* ) означает последовательность символов любой длины
Если комбинировать в работе операторы Wordstat и Key Collector, то можно существенно ускорить подбор семантики.
Настройка сбора запросов в Key Collector с использованием операторов Wordst
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples