
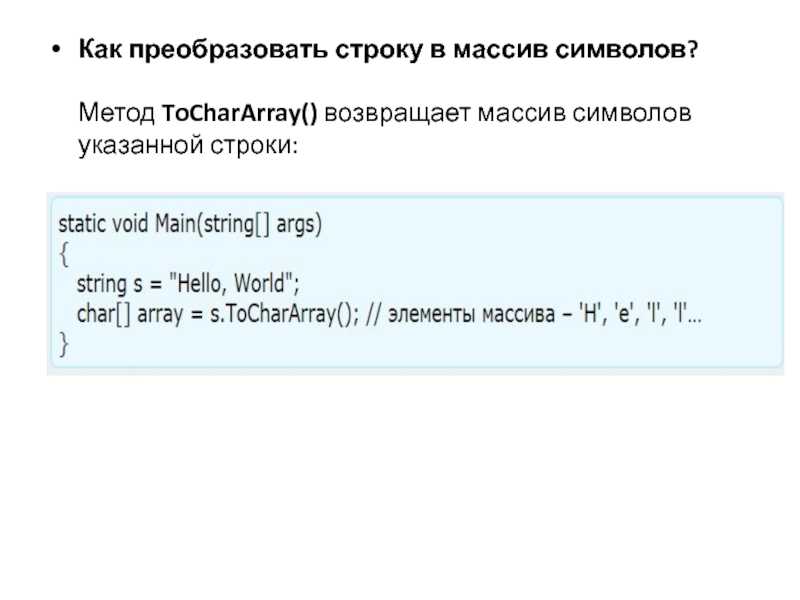
Строковые функции в Python
Python предоставляет различные встроенные функции, которые используются для работы со строками.
| Метод | Описание |
|---|---|
| Выводит первый символ строки заглавными буквами. Эта функция устарела в python3 | |
| Возвращает версию строки, пригодную для сравнений без регистра. | |
| Возвращает строку, заполненную пробелами, причем исходная строка центрируется с равным количеством пробелов слева и справа. | |
| Подсчитывает количество вхождений подстроки в строку между начальным и конечным индексом. | |
| Декодирует строку. | |
| Кодирование строки. Кодировка по умолчанию — . | |
| Возвращает булево значение, если строка заканчивается заданным суффиксом между begin и end. | |
| Определяет табуляцию в строке до нескольких пробелов. По умолчанию количество пробела равно 8. | |
| Возвращает значение индекса строки, в которой найдена подстрока между начальным и конечным индексами. | |
| Возвращает форматированную версию строки, используя переданное значение. | |
| Выбрасывает исключение, если строка не найдена. Работает так же, как и метод . | |
| Возвращает true, если символы в строке являются буквенно-цифровыми, т.е. алфавитами или цифрами, и в ней есть хотя бы один символ. В противном случае возвращается . | |
| Возвращает , если все символы являются алфавитными и есть хотя бы один символ, иначе . | |
| Возвращает , если все символы строки являются десятичными. | |
| Возвращает , если все символы являются цифрами и есть хотя бы один символ, иначе . | |
| Возвращает , если строка является действительным идентификатором. | |
| Возвращает , если символы строки находятся в нижнем регистре, иначе . | |
| Возвращает , если строка содержит только числовые символы. | |
| Возвращает , если все символы строки являются печатными или строка пустая, в противном случае возвращает . | |
| Возвращает , если символы строки находятся в верхнем регистре, иначе . | |
| Возвращает , если символы строки являются пробелами, иначе . | |
| Возвращает , если строка имеет правильный заголовок, и в противном случае. Заголовок строки — это строка, в которой первый символ в верхнем регистре, а остальные символы в нижнем регистре. | |
| Он объединяет строковое представление заданной последовательности. | |
| Возвращает длину строки. | |
| Возвращает строки, заполненные пробелами, с исходной строкой, выровненной по левому краю до заданной ширины. | |
| Он преобразует все символы строки в нижний регистр. | |
| Удаляет все пробелы в строке, а также может быть использован для удаления определенного символа из строки. | |
| Он ищет разделитель в строке и возвращает часть перед ним, сам разделитель и часть после него. Если разделитель не найден, возвращается кортеж в виде переданной строка и двух пустых строк. | |
| Возвращает таблицу перевода для использования в функции . | |
| Заменяет старую последовательность символов на новую. Если задано значение , то заменяются все вхождения. | |
| Похож на , но обходит строку в обратном направлении. | |
| Это то же самое, что и , но обходит строку в обратном направлении. | |
| Возвращает строку с пробелами, исходная строка которой выровнена по правому краю на указанное количество символов. | |
| Он удаляет все пробелы в строке, а также может быть использован для удаления определенного символа. | |
| Он аналогичен функции , но обрабатывает строку в обратном направлении. Возвращает список слов в строке. Если разделитель не указан, то строка разделяется в соответствии с пробелами. | |
| Разделяет строку в соответствии с разделителем . Строка разделяется по пробелу, если разделитель не указан. Возвращает список подстрок, скомпонованных с разделителем. | |
| Он возвращает список строк в каждой строке с удаленной строкой. | |
| Возвращает булево значение, если строка начинается с заданной строки между и . | |
| Он используется для выполнения функций и над строкой. | |
| Он инвертирует регистр всех символов в строке. | |
| Он используется для преобразования строки в заглавный регистр, т.е. строка будет преобразована в . | |
| Он переводит строку в соответствии с таблицей перевода, переданной в функцию . | |
| Он преобразует все символы строки в верхний регистр. | |
| Возвращает исходную строку, дополненную нулями минимального количества символов (параметр ); предназначена для чисел, сохраняет любой заданный знак (за вычетом одного нуля). | |
| Ищет последнее вхождение указанной строки и разбивает строку на кортеж, содержащий три элемента (часть перед указанной строкой, саму строку и часть после нее). |
Примечание – Вы можете добавить любое количество одинарных и двойных кавычек внутри строки, но три кавычки в начале и конце являются обязательными.
Поскольку ошибка EOL При сканировании строкового литерала возникает из-за неполных строк, неожиданный EOF при синтаксическом анализе возникает, когда в коде есть другие неполные блоки. Интерпретатор ждал завершения определенных скобок, но они так и не были заполнены в коде. Основная причина этой ошибки-неполные скобки, квадратные скобки и отсутствие блоков с отступами.
Например, рассмотрим цикл «for» в вашем коде, который не имеет предполагаемого блока, следующего за ним. В таких случаях будет сгенерирована синтаксическая ошибка EOF.
Кроме того, проверьте параметры, передаваемые в ваших функциях, чтобы избежать этой ошибки. Передача недопустимого аргумента также может привести к этой ошибке. Следующий пример кода может помочь вам понять ошибки синтаксического анализа –
Кроме того, проверьте параметры, передаваемые в ваших функциях, чтобы избежать этой ошибки. Передача недопустимого аргумента также может привести к этой ошибке. Следующий пример кода может помочь вам понять ошибки синтаксического анализа –
В этом примере в операторе print() отсутствует скобка. Интерпретатор достигает конца строки до того, как скобка завершается, в результате чего
В этом примере в операторе print() отсутствует скобка. Интерпретатор достигает конца строки до завершения скобки, что приводит к синтаксической ошибке. Такие ошибки можно устранить, просто добавив еще одну скобку.
Ошибка –
Пример 2 –
В этом примере нет блока кода после оператора «for». Интерпретатор python ожидает, что после оператора for a будет выполнен блок кода с отступом, но здесь его нет. В результате этот код выдает ошибку EOF. Чтобы устранить эту ошибку, вставьте предполагаемый блок в
В этом примере нет блока кода после оператора «for». Интерпретатор python ожидает, что после оператора for a будет выполнен блок кода с отступом, но здесь его нет. В результате этот код выдает ошибку EOF. Чтобы устранить эту ошибку, вставьте предполагаемый блок в конце.
Решение –
SQL функции для объединения строк
Одна из самых популярных категорий функций. Ведь частенько бывает нужно объединить значения нескольких полей таблиц базы данных сайта. В языке SQL есть сразу несколько функций для конкатенации строк.
Функция CONCAT:
string CONCAT(str1 string, str2 string,…)
Функция возвращает строку, созданную путем объединения аргументов. Можно указывать более двух аргументов. Если один из аргументов является NULL, то и возвращаемый результат будет NULL. Числовые значения преобразуются в строку.
Пример:
SELECT CONCAT (‘Hello’, ‘ ‘, ‘world’, ‘!’);
Результат: ‘Hello world!’
SELECT CONCAT (‘Hello’, NULL, ‘world’, ‘!’);
Результат: NULL
SELECT CONCAT (‘Число пи’, ‘=’, 3.14);
Результат: ‘Число пи=3.14’
Как видно из примеров, строки объединяются без разделителей. Для того чтобы разделить слова в первом примере в качестве аргумента приходится использовать пробел. Если бы слов было больше, то каждый раз вставлять пробелы было бы не очень удобно.
Для таких случаев существует функция CONCAT_WS:
string CONCAT_WS(separator string, str1 string, str2 string,…)
Функция объединяет строки как и функция CONCAT, но вставляет между аргументами разделитель separator. В случае если аргумент separator является NULL, то и результат будет NULL. Аргументы строки равные NULL пропускаются.
Пример:
SELECT CONCAT_WS (‘ ‘, ‘Иванов’, ‘Иван’, ‘Иванович’);
Результат: ‘Иванов Иван Иванович’
SELECT CONCAT_WS (NULL, ‘Иванов’, ‘Иван’, ‘Иванович’);
Результат: NULL
SELECT CONCAT_WS (‘ ‘, ‘Иванов’, NULL, ‘Иван’, ‘Иванович’);
Результат: »Иванов Иван Иванович’
В случае объединения большого количества строк, которые необходимо отделять разделителем, функция CONCAT_WS гораздо удобнее функции CONCAT.
Иногда бывает необходимо удлинить строку до определенного количества символов за счет повторения какого-либо символа. Это тоже своего рода объединение строк. Для этого можно использовать функции LPAD и RPAD. Функции имеют следующий синтаксис:
string LPAD(str string, len integer, padstr string)string RPAD(str string, len integer, padstr string)
Функция LPAD возвращает строку str дополненную слева строкой padstr до длины len. Функция RPAD выполняет тоже самое, только удлинение происходит с правой стороны.
Пример:
SELECT LPAD (‘test’, 10, ‘.’);
Результат: ……test
SELECT RPAD (‘test’, 10, ‘.’);
Результат: test……
В данных функциях необходимо обратить внимание на параметр len, который ограничивает количество выводимых символов. Поэтому если длина строки str будет больше чем параметр len, то строка будет обрезана:. SELECT LPAD (‘test’, 3, ‘.’);
Результат: tes
SELECT LPAD (‘test’, 3, ‘.’);
Результат: tes
Форматирование строки Python
Управляющая последовательность
Предположим, нам нужно написать текст – They said, “Hello what’s going on?” – данный оператор может быть записан в одинарные или двойные кавычки, но он вызовет ошибку SyntaxError, поскольку он содержит как одинарные, так и двойные кавычки.
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
str = "They said, "Hello what's going on?"" print(str)
Выход:
SyntaxError: invalid syntax
Мы можем использовать тройные кавычки для решения этой проблемы, но Python предоставляет escape-последовательность.
Символ обратной косой черты(/) обозначает escape-последовательность. За обратной косой чертой может следовать специальный символ, который интерпретируется по-разному. Одиночные кавычки внутри строки должны быть экранированы. Мы можем применить то же самое, что и в двойных кавычках.
Пример –
# using triple quotes
print('''''They said, "What's there?"''')
# escaping single quotes
print('They said, "What\'s going on?"')
# escaping double quotes
print("They said, \"What's going on?\"")
Выход:
They said, "What's there?" They said, "What's going on?" They said, "What's going on?"
Список escape-последовательностей приведен ниже:
| Номер | Последовательность | Описание | Пример |
|---|---|---|---|
| 1. | \newline | Игнорирует новую строку |
print("Python1 \
Python2 \
Python3")
Output: Python1 Python2 Python3 |
| 2. | \\ | Косая черта |
print("\\")
Output: \ |
| 3. | \’ | одиночные кавычки |
print('\'')
Output: ' |
| 4. | \\” | Двойные кавычки |
print("\"")
Output: " |
| 5. | \a | ASCII Bell |
print("\a")
|
| 6. | \b | ASCII клавиша Backspace |
print("Hello \b World")
Output: Hello World |
| 7. | \f | ASCII Formfeed |
print("Hello \f World!")
Hello World!
|
| 8. | \n | ASCII Linefeed |
print("Hello \n World!")
Output: Hello World! |
| 9. | \r | ASCII Carriege Return(CR) |
print("Hello \r World!")
Output: World! |
| 10. | \t | ASCII горизонтальный tab |
print("Hello \t World!")
Output: Hello World! |
| 11. | \v | ASCII вертикальный Tab |
print("Hello \v World!")
Output: Hello World! |
| 12. | \ooo | Символ с восьмеричным значением |
print("\110\145\154\154\157")
Output: Hello |
| 13 | \xHH | Символ с шестнадцатеричным значением |
print("\x48\x65\x6c\x6c\x6f")
Output: Hello |
Вот простой пример escape-последовательности.
print("C:\\Users\\DEVANSH SHARMA\\Python32\\Lib")
print("This is the \n multiline quotes")
print("This is \x48\x45\x58 representation")
Выход:
C:\Users\DEVANSH SHARMA\Python32\Lib This is the multiline quotes This is HEX representation
Мы можем игнорировать escape-последовательность из данной строки, используя необработанную строку. Мы можем сделать это, написав r или R перед строкой. Рассмотрим следующий пример.
print(r"C:\\Users\\DEVANSH SHARMA\\Python32")
Выход:
C:\\Users\\DEVANSH SHARMA\\Python32
Функции LTRIM и RTRIM
LTRIM (<строковое выражение>)
RTRIM (<строковое выражение>)
отсекают соответственно лидирующие и конечные пробелы строкового выражения, которое неявно приводится к типу VARCHAR.
Пусть требуется построить такую строку: имя пассажира_идентификатор пассажира для каждой записи из таблицы Passenger. Если мы напишем
| SELECT name + ‘_’ + CAST(id_psg AS VARCHAR) FROM Passenger, |
то в результате получим что-то типа:
A _1
Это связано с тем, что столбец name имеет тип CHAR(30). Для этого типа короткая строка дополняется пробелами до заданного размера (у нас 30 символов). Здесь нам как раз и поможет функция RTRIM:
| SELECT RTRIM(name) + ‘_’ + CAST(id_psg AS VARCHAR) FROM Passenger |
Примеры использования массивов Bash
Теперь рассмотрим примеры массивов bash. Сначала нам нужно создать массив, который мы будем использовать для примеров, на мой взгляд будет проще использовать синтаксис с круглыми скобками. Вообще, массивы используются в скриптах, но мы будем их применять прямо в оболочке Bash. Для начала так будет проще. Создаем массив:
![]()
Теперь попытаемся вывести один из элементов массива по его индексу:
![]()
Чаще всего используются массивы строк Bash, но иногда могут встречаться и цифры. Помните про нумерацию? Индексы элементов массива начинаются с нуля. Для вывода значения элемента по индексу можно использовать и немного другой синтаксис:
![]()
Вы можете вывести все элементы:
![]()
Все элементы, начиная с номера 1:
![]()
Вывести все элементы которые находятся в диапазоне от 1 до 4:
![]()
Чтобы узнать длину первого элемента выполните:
![]()
А посмотреть количество элементов массива Bash можно таким же синтаксисом:
![]()
Кроме всего прочего, вы можете заменить одни символы в определенном элементе массива или во всем массиве на другие. Для этого используйте:
![]()
В некоторых случаях, для перебора элементов массива очень удобно использовать циклы. На этот раз сделаем небольшой скрипт:
#!/bin/bash
array=(первый второй третий четвертый пятый)
for i in ${array}
do
echo $i
done
![]()
Внутри цикла вы можете делать со значением элемента все, что вам нужно. Как я уже писал выше, вы можете прочитать значения для массива с помощью функции read:
#!/bin/bash
echo «Введите элементы массива:»
read -a array
echo «Результат:»
for i in ${array}
do
echo $i
done
![]()
Как и в любом другом варианте, вам нужно, чтобы все элементы были разделены пробелом. Точно так же можно присвоить массиву результат выполнения команды. Например, сохраним список файлов, полученный от ls:






![]()
Усложним задачу и сделаем скрипт, который будет выводить все файлы из указанной директории, которые имеют права доступа 755:
#!/bin/bash
ERR=27
EXT=0
if ; then
echo «Используйте: $0 <путь>»
exit $ERR
fi
if ; then
echo «Каталог $1 не существует»
exit $ERR
fi
temp=( $(find $1 -maxdepth 1 -type f) )
for i in «${temp}»
do
perm=$(ls -l $i)
if ; then
echo ${i##*/}
fi
done
exit $EXT
![]()
Теперь проверим наш скрипт на папке /bin. Но перед этим нужно дать ему права на выполнение:
![]()
Как видите, все работает. Кроме номеров, в качестве индексов для массивов можно использовать строки. Такие массивы Bash называются ассоциативными и поддерживаются они начиная с четвертной версии Bash. Для создания ассоциативного массива используется declare с опцией -A:
![]()
Несмотря на то что Bash поддерживает только одномерные массивы, мы можем выполнять симуляцию работы с многомерными матрицами с помощью ассоциативных массивов:
![]()
Чтобы удалить массив, созданный с помощью declare используйте функцию unset:
Причины ошибки EOL При сканировании строкового литерала
Существуют известные причины ошибки EOL в Python. Как только вы узнаете их все, вы сможете легко отлаживать свой код и исправлять его. Хотя эти причины не обязательно являются единственными известными причинами ошибки. Некоторые другие ошибки также могут привести к возникновению ошибки EOL. Давайте сразу перейдем ко всем причинам –
Причина 1: Незамкнутые Одинарные кавычки
Строковые литералы в python могут быть объявлены с помощью одинарных кавычек в вашей программе. Эти литералы должны быть закрыты в пределах двух одинарных кавычек знака (‘ ‘). Если вам не удалось заключить строку между этими двумя кавычками, она выдаст EOL При сканировании строкового литерала с ошибкой. Более того, если вы дадите дополнительную одинарную кавычку в своей строке, она также выдаст ту же ошибку. Следующие примеры помогут вам понять –
Пример 1 –
example1 = 'Single Quotes String"Triple Quotes String""" example1 # will print S
В этом примере в строке 1 отсутствует конечная одинарная кавычка. Эта пропущенная цитата заставляет интерпретатор анализировать следующие строки как неверные. Добавление одной кавычки в конце строки 1 может решить эту проблему.
Пример 2 –
x = 'This is a String print(x)
В этом примере в конце строки 1 отсутствует одинарная кавычка.
Пример 3 –
В этом специальном примере в первой строке есть три одиночные кавычки. Согласно python, строка для переменной x заканчивается в конце одинарной кавычки. Следующая часть будет рассматриваться как часть другого кода, а не как строка. Это приводит к появлению синтаксической ошибки на экране.
Причина 2: Незамкнутые Двойные кавычки
Строковые литералы также могут быть объявлены с помощью двойных кавычек. В большинстве языков программирования двойные кавычки-это способ объявления строки по умолчанию. Таким образом, если вы не заключите строку в двойные кавычки, она вызовет SyntaxError. Более того, если вы использовали нечетное количество кавычек («) в своей строке, она также выдаст эту ошибку из-за пропущенной кавычки. Следующий пример поможет вам понять –
Пример 1 –
«»triple>
В этом примере в конце второй строки отсутствует двойная кавычка. Эта пропущенная цитата заставляет интерпретатор анализировать все следующие коды как часть строки для переменной пример 2. В конце концов, он выдает ошибку EOL, когда достигает конца файла.
Пример 2 –
x = "This is a String print(x)
Аналогично, в конце строки 1 отсутствует двойная кавычка.
Пример 3 –
В этом специальном примере в первой строке есть три двойные кавычки. Согласно python, строка для переменной x заканчивается в конце одинарной кавычки. Следующая часть будет рассматриваться как часть другого кода, а не как строка. Это приводит к появлению синтаксической ошибки на экране.
В Python существует специальный способ объявления строк с использованием трех двойных кавычек («»»). Этот способ чрезвычайно часто используется, когда вам приходится включать двойные и одинарные кавычки в вашу строку. С помощью этого типа объявления вы можете включить в строку любой символ. Итак, если вы не закрыли эту тройную цитату, я брошу ошибку EOL. Следующие примеры помогут вам понять –
Пример 1 –
В строке 3 примера отсутствует цитата из набора тройных кавычек. В результате интерпретатор python будет рассматривать все следующие строки как часть переменной string for example 3. В конце концов, поскольку нет окончательных тройных кавычек, это вызовет ошибку EOL.
«triple>
Пример 2 –
Как и в примере 1, в строке 1 отсутствуют две кавычки.
«this>
Причина 4: Нечетное число обратных косых черт в необработанной строке
Обратные косые черты используются в строке для включения в нее специальных символов. Например, если вы хотите добавить двойные кавычки в строку с двойными кавычками, вы можете использовать\», чтобы добавить ее. Каждый символ после обратной косой черты имеет свое значение для python. Таким образом, если вы не предоставите соответствующий следующий символ после обратной косой черты (\), вы получите EOL При сканировании строкового литерала Ошибки. Следующие примеры помогут вам понять это –
Пример 1 –
Следующая строка недопустима, так как после обратной косой черты нет следующего символа. В настоящее время python обрабатывает строки так же, как и стандартный C. Чтобы избежать этой ошибки, поставьте «r» или «R» перед вашей строкой.
Пример 2 –
Следующий пример содержит нечетное число обратных косых черт без следующих символов. Это приводит к возникновению ошибки EOL, поскольку интерпретация ожидает следующего символа.
Пример 3 –
Последняя обратная косая черта в строке не имеет следующего символа. Это приводит к тому, что компилятор выдает ошибку.
Потоки
Файл, из которого осуществляется чтение, называется стандартным потоком ввода, а в который осуществляется запись — стандартным потоком вывода.
Стандартные потоки:
При перенаправлении потоков, вы можете указывать ссылки на определенные потоки. Например, перенаправим вывод и ошибки команды в файл:
Перенаправление потоков
Для перенаправления потоков используются основные команды: <, >, >>, <<<, |. Рассмотрим как можно перенаправлять стандартные потоки.
Перенаправление потока вывода:
Перенаправление потока ввода (прием данных):
Перенаправление вывода ошибок:
Примечание
Если вам нужно захватить вывод команды в переменную и при этом отобразить вывод на экране, используйте :
Подстановка процессов
Передать процессу команда1 файл (созданный налету канал или файл /dev/fd/…), в котором находятся данные, которые выводит команда2:
Примеры
Логировать результат поиска и ошибки:
Эта конструкция позволяет читать из строки как из файла. Демонстрационный пример:
Создаем временный файл и записываем в него поток переданный скрипту:
А теперь откроем файл в текстовом редакторе с «отвязкой» (отключением) от терминала, подавляем вывод сообщений в терминал:
Разделение
Класс Java String содержит метод split(), который можно использовать для разделения String на массив объектов String:
String source = "A man drove with a car.";
String[] occurrences = source.split("a");
После выполнения этого кода Java массив вхождений будет содержать экземпляры String:
"A m" "n drove with " " c" "r."
Исходная строка была разделена на символы a. Возвращенные строки не содержат символов a. Символы a считаются разделителями для деления строки, а разделители не возвращаются в результирующий массив строк.
Параметр, передаваемый методу split(), на самом деле является регулярным выражением Java, которые могут быть довольно сложными. Приведенное выше соответствует всем символам, даже буквам нижнего регистра.
Метод String split() существует в версии, которая принимает ограничение в качестве второго параметра – limit:
String source = "A man drove with a car.";
int limit = 2;
String[] occurrences = source.split("a", limit);
Параметр limit устанавливает максимальное количество элементов, которое может быть в возвращаемом массиве. Если в строке больше совпадений с регулярным выражением, чем заданный лимит, то массив будет содержать совпадения с лимитом – 1, а последним элементом будет остаток строки из последнего среза – 1 совпадением. Итак, в приведенном выше примере возвращаемый массив будет содержать эти две строки:
"A m" "n drove with a car."
Первая строка соответствует регулярному выражению. Вторая – это остальная часть строки после первого куска.
Выполнение примера с ограничением 3 вместо 2 приведет к тому, что эти строки будут возвращены в результирующий массив String:
"A m" "n drove with " " car."
Обратите внимание, что последняя строка по-прежнему содержит символ в середине. Это потому, что эта строка представляет остаток строки после последнего совпадения (a после ‘n водил с’)
Выполнение приведенного выше примера с пределом 4 или выше приведет к тому, что будут возвращены только строки Split, поскольку в String есть только 4 совпадения с регулярным выражением a.
Удаление пробелов из строки
Для удаления лишних пробелов из начала и конца строки в языке SQL есть три функции.
Функция LTRIM:
string LTRIM(str string)
Удаляет с начала строки str пробелы и возвращает результат.
Функция RTRIM:
string RTRIM(str string)
Также удаляет пробелы из строки str, только с конца. Обе функции поддерживают многобайтовые символы.








Пример:
SELECT LTRIM (‘ текст ‘);
Результат: ‘текст ‘
SELECT RTRIM (‘ текст ‘);
Результат: ‘ текст’
И третья функция TRIM позволяет сразу удалять пробелы из начала и из конца строки:
string TRIM( string FROM] str string)
Параметр str обязательный, остальные параметры не обязательные. В случае если задан только один параметр str, то возвращает строку str удалив пробелы из начала и конца строки одновременно.
Пример:
SELECT TRIM (‘ текст ‘);
Результат: ‘текст’
С помощью пара метра remstr можно задавать символы или подстроки, которые будут удаляться из начала и конца строки. С помощью управляющих параметров BOTH, LEADING, TRAILING можно задавать откуда будут удаляться символы:
- BOTH — удаляет подстроку remstr с начала и с конца строки;
- LEADING — удаляет remstr с начала строки;
- TRAILING — удаляет remstr с конца строки.
Пример:
SELECT TRIM (BOTH ‘а’ FROM ‘текст’);
Результат: ‘текст’
SELECT TRIM (LEADING ‘а’ FROM ‘текстааа’);
Результат: ‘текстааа’
SELECT TRIM (TRAILING ‘а’ FROM ‘ааатекст’);
Результат: ‘ааатекст’
Функция SPACE позволяет получить строку состоящую из определенного количества пробелов:
string SPACE(n integer)
Возвращает строку, которая состоит из n пробелов.
Функция REPLACE нужна для замены заданных символов в строке:
string REPLACE(str string, from_str string, to_str string)
Функция заменяет в строке str все подстроки from_str на to_str и возвращает результат. Поддерживает многобайтные символы.
Пример:
SELECT REPLACE ( ‘замена подстроки’, ‘подстроки’, ‘текста’ )
Результат: ‘замена текста’
Функция REPEAT:
string REPEAT(str string, count integer)
Функция возвращает строку, которая состоит из count повторений строки str. Поддерживает многобайтовые символы.
Пример:
SELECT REPEAT (‘w’, 3);
Результат: ‘www’
Функция REVERSE переворачивает строку:
string REVERSE(str string)
Переставляет в строке str все символы с последнего на первый и возвращает результат. Поддерживает многобайтовые символы.
Пример:
SELECT REVERSE (‘текст’);
Результат: ‘тскет’
Функция INSERT для вставки подстроки в строку:
string INSERT(str string, pos integer, len integer, newstr string)
Возвращает строку полученную в результате вставки в строку str подстроки newstr с позиции pos. Параметр len указывает сколько символов будет удалено из строки str, начиная с позиции pos. Поддерживает многобайтовые символы.
Пример:
SELECT INSERT (‘text’, 2, 5, ‘MySQL’);
Результат: ‘tMySQL’
‘SELECT INSERT (‘text’, 2, 0, ‘MySQL’);
Результат: ‘tMySQLext’
SELECT INSERT (‘вставка текста’, 2, 7, ‘MySQL’);
Результат: ‘SELECT INSERT (‘вставка текста’, 2, 7, ‘MySQL’);’
Если вдруг понадобиться заеменить в тексте все заглавные буквы на прописные, то можно воспользоваться одной из двух функций:
string LCASE(str string) и string LOWER(str string)
Обе функции заменяют в строке str заглавные буквы на прописные и возвращают результат. И та и другая поддерживают многобайтовые символы.
Пример:
SELCET LOWER (‘АБВГДеЖЗиКЛ’);
Результат:’абвгдежзикл’
Если же наоборот необходимо прописные буквы заменить заглавными, то также можно применить одну из двух функцийй:
string UCASE(str string) и string UPPER (str string)
Функции возвращают строку str, заменив все прописные символы на заглавные. Также поддерживают многобайтовые символы.
Пример:
SELECT UPPER (‘Абвгдежз’);
Результат: ‘АБВГДЕЖЗ’
Классы символьных потоков
|
Класс |
Назначение |
|
BufferedReader |
Буферизованный входной символьный поток. |
|
BufferedWriter |
Буферизованный выходной символьный поток. |
|
CharArrayReader |
Входной поток, который читает из символьного массива. |
|
CharArrayWriter |
Выходной поток, который пишет в символьный массив. |
|
FileReader |
Входной поток, читающий файл. |
|
FileWriter |
Выходной поток, пишущий в файл. |
|
FilterReader |
Фильтрующий читатель. |
|
FilterWriter |
Фильтрующий писатель. |
|
InputStreamReader |
Входной поток, транслирующий байты в символы. |
|
LineNumberReader |
Входной поток, подсчитывающий строки. |
|
OutputStreamWriter |
Выходной поток, транслирующий байты в символы. |
|
PipedReader |
Входной канал. |
|
PipedWriter |
Выходной канал. |
|
PrintWriter |
Выходной поток, включающий print() и println(). |
|
PushbackReader |
Входной поток, позволяющий возвращать символы обратно в поток. |
|
Reader |
Абстрактный класс, описывающий символьный ввод. |
|
StringReader |
Входной поток, читающий из строки. |
|
StringWriter |
Выходной поток, пишущий в строку. |
|
Writer |
Абстрактный класс, описывающий символьный вывод. |
#pushd and #popd command in linux | what is #directory #stack
https://youtube.com/watch?v=gOG40rWhi1A
#pushd and #popd command in linux | what is #directory #stack



и — это команды, которые позволяют вам работать со стеком каталогов и изменять текущий рабочий каталог в Linux и других Unix-подобных операционных системах. Хотя и являются очень мощными и полезными командами, они недооцениваются и используются редко.
В этом руководстве мы покажем вам, как использовать команды и для навигации по дереву каталогов вашей системы.
Стек каталогов представляет собой список каталогов, к которым вы ранее обращались. Содержимое стека каталогов можно увидеть с помощью команды . Каталоги добавляются в стек при переходе в каталог с помощью команды и удаляются с команды .
Текущий рабочий каталог всегда находится на вершине стека каталогов. Текущий рабочий каталог — это каталог (папка), в котором в данный момент работает пользователь. Каждый раз, когда вы взаимодействуете с командной строкой, вы работаете в каталоге.
Команда позволяет вам узнать, в каком каталоге вы сейчас находитесь.
При навигации по файловой системе используйте клавишу для автозаполнения имен каталогов. Добавление косой черты в конце имени каталога не является обязательным.
, и — встроенные функции оболочки, и их поведение может немного отличаться от оболочки к оболочке. Мы рассмотрим встроенную версию команд Bash.
Команда
Синтаксис команды следующий:
Например, чтобы сохранить текущий каталог в верхней части стека каталогов и изменить его на , введите:
В случае успеха указанная выше команда напечатает стек каталогов. каталог, в котором мы выполнили команду . Символ тильды означает домашний каталог.
Сначала сохраняет текущий рабочий каталог в верхней части стека, а затем переходит к указанному каталогу. Поскольку текущий каталог всегда должен быть на вершине стека, после изменения новый текущий каталог попадает на вершину стека, но не сохраняется в стеке. Чтобы сохранить его, вы должны вызвать из него. Если вы используете для перехода в другой каталог, верхний элемент стека будет потерян,
Давайте добавим еще один каталог в стек:
Чтобы отменить изменение по умолчанию для каталога, используйте параметр . Например, чтобы добавить каталог в стек, но не вносить в него изменения, введите:
Поскольку текущий каталог (который всегда находится сверху) не изменяется, каталог добавляется вторым сверху вершины стека:
принимает две опции, и что позволяет вам перейти к каталогу стека. Опция изменяется на элемент списка стека, считая слева направо, начиная с нуля. Когда используется , направление отсчета идет справа налево.
Чтобы лучше проиллюстрировать параметры, давайте напечатаем текущий стек каталогов:
Вывод покажет индексированный список стека каталогов:
При подсчете сверху вниз (или слева направо) индекс каталога равен .
При подсчете снизу вверх индекс каталога равен .
Когда используется без каких-либо аргументов, переключит две верхние директории и сделает новую вершину текущей директорией. Это то же самое, что и при использовании команды .
Команда принимает форму:
При использовании без аргументов удаляет верхний каталог из стека и переходит в новый верхний каталог.
Допустим, у нас есть следующий стек каталогов:
Вывод покажет новый стек каталогов:
Опция подавляет изменение каталога по умолчанию и удаляет второй элемент из стека:
Как и , также принимает параметры и , которые можно использовать для удаления каталога стека.
Вывод
Обычно вы используете команду для перехода из одного каталога в другой. Однако, если вы проводите много времени в командной строке, команды и повысят вашу производительность и эффективность.
терминал bash
Знание того, как использовать командную строку, может быть очень полезным. В этой статье мы рассмотрим некоторые из наиболее распространенных команд Linux, которые ежедневно используются системными администраторами Linux.
Команда du, сокращение от использования диска, сообщает о приблизительном объеме дискового пространства, используемого данными файлами или каталогами. Это практически полезно для поиска файлов и каталогов, занимающих много места на диске.
Сколько места осталось на моем жестком диске? В системах на основе Linux вы можете использовать команду df, чтобы получить подробный отчет об использовании дискового пространства системы.




![Вы хотите разрешить следующую программу от неизвестного издателя …? [fix]](http://fuzeservers.ru/wp-content/uploads/4/5/c/45c7609074a10a904c80ff2ebbbbe80f.png)
