Выражения в квадратных скобках и Классы символов
В дополнение к совпадению любого символа в заданной позиции в нашем регулярном выражении, мы также, используя выражения в квадратных скобках, можем задать совпадение единичного символа из указанного набора символов. С выражениями в квадратных скобках мы можем указать набор символов для соответствия (включая символы, которые в противном случае были бы истолкованы как метасимволы). В этом примере, используя набор из двух символов:
grep -h 'zip' dirlist*.txt bzip2 bzip2recover gzip
мы найдём любые строчки, содержащие строки «bzip» или «gzip».
Набор может содержать любое количество символов, а метасимволы теряют своё специальное значение, когда помещаются внутрь квадратных скобок. Тем не менее, есть два случая в которых метасимволы, используемые внутри квадратных скобок, имеют различные значения. Первый – это каретка (^), которая используется для указания отрицания; второй – это тире (-), которое используется для указания диапазона символов.
Отрицание
Если первым символом выражения в квадратных скобках является каретка (^), то остальные символы принимаются как набор символов, которые не должны присутствовать в заданной позиции символа. Сделаем это изменив наш предыдущий пример:
grep -h 'zip' dirlist*.txt bunzip2 gunzip funzip gpg-zip mzip p7zip preunzip prezip prezip-bin unzip unzipsfx
С активированным отрицанием, мы получили список файлов, которые содержат строку «zip», перед которой идёт любой символ, кроме «b» или «g»
Обратите внимание, что zip не был найден. Отрицаемый набор символов всё равно требует символ на заданной позиции, но символ не должен быть членом инвертированного набора.
Символ каретки вызывает отрицание только если он является первым символом внутри выражения в квадратных скобках; в противном случае, он теряет своё специальное назначение и становится обычным символом из набора.
Традиционные диапазоны символов
Если мы хотим сконструировать регулярное выражение, которое должно найти каждый файл из нашего списка, начинающийся на заглавную букву, мы можем сделать следующее:
grep -h '^' dirlist*.txt MAKEDEV GET HEAD POST VBoxClient X X11 Xorg ModemManager NetworkManager VBoxControl VBoxService
Суть в том, что мы разместили все 26 заглавных букв в выражение внутри квадратных скобок. Но мысль печатать их все не вызывает энтузиазма, поэтому есть другой путь:
grep -h '^' dirlist*.txt
Используя трёхсимвольный диапазон, мы можем сократить запись из 26 букв. Таким способом можно выразить любой диапазон символов, включая сразу несколько диапазонов, такие, как это выражение, которое соответствует всем именам файлов, начинающихся с букв и цифр:
grep -h '^' dirlist*.txt
В диапазонах символов мы видим, что символ чёрточки трактуется особым образом, поэтому как мы можем включить символ тире в выражение внутри квадратных скобок? Сделав его первым символом в выражении. Рассмотрим два примера:
grep -h '' dirlist*.txt
Это будет соответствовать каждому имени файла, содержащему заглавную букву. При этом:
grep -h '' dirlist*.txt
будет соответствовать каждому имени файла, содержащему тире, или заглавную «A», или заглавную «Z».
Классы символов POSIX
Подробнее о POSIX вы можете почитать в Википедии.
В POSIX имеются свои классы символов, которые вы можете использовать в регулярных выражениях:
| Класс символов | Описание |
|---|---|
| Алфавитно-цифровые символы. В ASCII эквивалентно: | |
| То же самое, что и , с дополнительным символом подчёркивания (_). | |
| Алфавитные символы. В ASCII эквивалентно: | |
| Включает символы пробела и табуляции. | |
| Управляющие коды ASCII. Включает ASCII символы с 0 до 31 и 127. | |
| Цифры от нуля до девяти. | |
| Видимые символы. В ASCII сюда включены символы с 33 по 126. | |
| Буквы в нижнем регистре. | |
| Символы пунктуации. В ASCII эквивалентно: [-!»#$%&'()*+,./:;?@_`{|}~] | |
| Печатные символы. Все символы в плюс символ пробела. | |
| Символы белых пробелов, включающих пробел, табуляцию, возврат каретки, новую строку, вертикальную табуляцию и разрыв страницы. В ASCII эквивалентно: | |
| Символы в верхнем регистре. | |
| Символы, используемые для выражения шестнадцатеричных чисел. В ASCII эквивалетно: |
В этих выражениях квадратные скобки и двоеточия являются частью записи класса символов (диапазонов).
Внимание: в зависимости от настроек локали, , , и другие буквенные диапазоны могут включать буквы вашего алфавита, например, русского. Т.е
может соответствовать не , а .
Справочная информация о Regular Expressions
Вот что Википедия говорит:
Это ничего не говорит мне о фактических образцах. Регулярные выражения, которые я буду обсуждать сегодня, содержат такие символы, как \w, \s, \1 и многие другие, которые ни на что другое не похожи.
Если вы хотите немного узнать о регулярных выражениях, прежде чем продолжать читать эту статью, я предложил бы посмотреть серию Regular Expressions for Dummies.
Главное, что нужно помнить о регулярных выражениях, — это то, что они почти одинаково читаются вперёд и назад. В этом предложении больше смысла, когда мы говорим о совпадении тегов HTML.
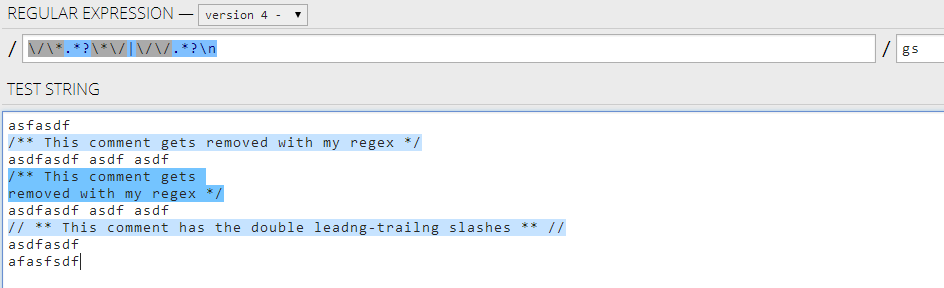
Примечание: Ограничителями, используемыми в регулярных выражениях, являются косые черты, «/». Каждый шаблон начинается и заканчивается разделителем. Если прямая косая черта появляется в regex, мы должны убрать её обратной косой: «\ /».
Согласование Hex Value
Описание:
Начнём с указания parser найти начало строки (^). Затем знак числа является необязательным, поскольку за ним следует вопросительный знак. Вопросительный знак говорит parser, что предыдущий символ — в данном случае знак числа — является необязательным, но чтобы был «жадным» и отметил его, если он есть. Далее, внутри первой группы (первая группа круглых скобок) мы можем иметь две разные ситуации. Первая — любая буква в нижнем регистре между a и f или число шесть раз. Вертикальная полоса говорит нам, что мы можем также иметь три строчные буквы между a и f или номерами. Наконец, нам нужен конец строки ($).
Причина, по которой я ставил шесть символов перед этим, заключается в том, что parser запишет значение hex value типа #ffffff. Если бы я перевернул его так, чтобы три символа стали первыми, parser мог бы получить только #fff, а не другие три f.
Альтернативы¶
Выражения в списке альтернатив разделяются .
Таким образом, будет соответствовать любому из , или (также как и ).
Первое выражение включает в себя все от последнего разделителя шаблона (, или начало шаблона) до первого , а последнее выражение содержит все от последнего к следующему разделителю шаблона.
Звучит сложно, поэтому обычной практикой является заключение списка альтернатив в скобки, чтобы минимизировать путаницу относительно того, где он начинается и заканчивается.
Выражения в списке альтернатив пробуются слева направо, принимается первое же совпадение.
Например, регулярное выражение в строке будет соответствовать — первое же совпадение.
Также помните, что в квадратных скобках воспринимается просто как символ, поэтому, если вы напишите , это тоже самое что .
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Символы¶
Серия символов соответствует этой серии символов во входной строке.
| RegEx | Находит |
|---|---|
Непечатные символы (escape-коды)
Для представления непечатаемого символа в регулярном выражении используется с шестнадцатеричным кодом. Если код длиннее 2 цифр (более U+00FF), то он обрамляется в фигурные скобки.



RegEx
Находит
символ с 2-значным шестнадцатеричным кодом
символ с 1-4 значным шестнадцатеричным кодом
(обратите внимание на пробел в середине)
Существует ряд предопределенных для непечатных символов, как в языке :
| RegEx | Находит |
|---|---|
| tab (HT/TAB), тоже что | |
| символ новой строки (LF), то же что | |
| возврат каретки (CR), тоже что | |
| form feed (FF), то же что | |
| звонок (BEL), тоже что | |
| escape (ESC), то же что | |
| … |
chr(0) по chr(25). |
Рекомендации:
- страницы руководства ()
- http://droptips.com/using-grep-and-ignoring-case-case-insensitive-grep
JavaScript
Если вы хотите сделать регистр нечувствительным, просто добавьте в конце регулярного выражения:
// Возвращает [»Контрольная работа»]
Без
// Возвращает [»Т»]
В Java конструктор
Итак, чтобы игнорировать случаи, используйте
Вы можете попрактиковаться в Regex в Visual Studio и Visual Studio Code, используя команду find / replace.
Для регулярных выражений с регистром необходимо выбрать как Match Case, так и Regular Expressions. Иначе [A-Z] не будет работать. Введите описание изображения здесь
![]()
Вы также можете перевести исходную строку, которую вы собираетесь проверить на соответствие шаблону, в нижний регистр. И используя соответственно строчные символы в вашем шаблоне.
Проверка URL
Описание:
Это regex почти походит к заключительной части вышеупомянутого регулярного выражения, собрав его между «http: //» и некоторой структурой файла в конце. Это звучит намного проще, чем есть на самом деле. Для начала мы ищем начало строки с помощью каретки.
Первая группа охвата — это все опции. Он позволяет URL-адресу начинаться с «http: //», «https: //» или без них. У меня вопросительный знак после s, чтобы разрешить URL-адреса с http или https. Чтобы сделать всю эту группу необязательной, я просто добавил вопросительный знак к её концу.
Далее идет доменное имя: одно или несколько чисел, букв, точек или дефисов, за которыми следует другая точка, затем от двух до шести букв или точек. Следующий раздел — это необязательные файлы и каталоги. Внутри группы мы хотим сопоставить любое количество косой черты, буквы, цифры, символы подчёркивания, пробелы, точки или дефисы. Затем мы говорим, что эту группу можно сопоставлять столько раз, сколько мы хотим. В значительной степени это позволяет совместить несколько каталогов вместе с файлом в конце. Я использовал звезду вместо вопросительного знака, потому что звезда говорит ноль или больше, а не ноль или один. Если бы в нём использовался вопросительный знак, мог быть сопоставлен только один файл/каталог.
Затем завершающая косая черта сопоставляется, но она может быть необязательной. Наконец, мы заканчиваем с концом строки.
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Компоненты распознавания и печати штрих-кодов Промо
Комплект программного обеспечения для реализации функций оптического распознавания штрих-кодов различных систем при помощи обычной web-камеры, а также их отображения в печатных формах. Программы могут работать в составе конфигураций, созданных на базе платформ «1С-Предприятие» версий 7.7, 8.2, 8.3. Компонент чтения кодов реализован в виде внешней компоненты 1С с COM-интерфейсом. Компонент отображения создан по стандартной технологии ActiveX для Windows, и может быть встроен в любое приложение, поддерживающее встраивание ActiveX элементов управления, например в документ Word или Excel, или форму VBA.
P.S. Добавлена новая версия программы распознавания. Новые функции: обработка видео в реальном режиме (а не по таймеру, как раньше), добавлена возможность распознавания штрих-кодов из графических файлов JPEG, PNG, GIF, BMP, а также передавать для распознавания картинки из 1С, теперь можно получить в 1С захваченное с камеры или файла изображение, как с выделением мест, содержащих коды, так и без, а также отдельные фрагменты изображений, содержащие код. Добавлены новые свойства и методы для программирования. Обновлена документация.
10 стартмани
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
5 ответов
Лучший ответ
Perl позволяет сделать часть вашего регулярного выражения нечувствительной к регистру с помощью модификатора шаблона (? I :).
Современные разновидности регулярных выражений позволяют применять модификаторы только к части регулярного выражения. Если вы вставите модификатор (? Ism) в середину регулярного выражения, модификатор применяется только к той части регулярного выражения, которая находится справа от модификатора. Вы можете выключить режимы, поставив перед ними знак минус. Все режимы после знака минус будут отключены. Например. (? i-sm) включает нечувствительность к регистру и выключает как однострочный, так и многострочный режим.





Не все регулярные выражения поддерживают это. JavaScript и Python применяют все модификаторы режима ко всему регулярному выражению. Они не поддерживают синтаксис (? -Ismx), поскольку отключение опции не имеет смысла, когда модификаторы режима применяются ко всем регулярным выражениям. Все параметры по умолчанию отключены.
Вы можете быстро проверить, как используемый вами вариант регулярного выражения обрабатывает модификаторы режима. Регулярное выражение (? I) te (? — i) st должно соответствовать test и TEst, но не teST или TEST.
93
Espo
4 Сен 2008 в 16:35
На каком языке ты говоришь? Стандартный способ сделать это — что-то вроде / ( {2} | BAR) / с включенной чувствительностью к регистру, но в Java, например, есть модификатор чувствительности к регистру (? I), который делает все символы справа от него нечувствительны к регистру и (? -i), который устанавливает чувствительность. Пример этого модификатора регулярного выражения Java можно найти здесь.
6
akdom
4 Сен 2008 в 16:41
К сожалению, синтаксис для сопоставления без учета регистра встречается нечасто. В .NET вы можете использовать флаг RegexOptions.IgnoreCase или модификатор ? I
6
aku
4 Сен 2008 в 16:41
Это правда, что можно полагаться на встроенные модификаторы, как описано в Включение и выключение режимов только для части регулярного выражения :
Однако немного более поддерживаемая функция — это группа встроенных модификаторов (см. Диапазон модификаторов ). Синтаксис: , затем шаблон, который вы хотите сделать без учета случайности, а затем .
Обратное : если ваш шаблон скомпилирован с параметром без учета регистра и вам нужно сделать часть регулярного выражения чувствительной к регистру, вы добавляете после : .
Пример использования на разных языках (заключение совпадений в угловые скобки):
- php — (демо)
- python — (демо) (примечание Python поддерживает встроенные группы модификаторов, начиная с Python 3.6)
- c # / vb.net / . net — ( демо)
- java — (демо)
- perl — (демо)
- рубин — (демо)
- r — (демо)
- быстро —
- go — (использует RE2) — (демонстрация)
Не поддерживается в javascript, bash, sed, c ++ , lua, tcl.
6
Wiktor Stribiżew
12 Ноя 2019 в 23:16
Вы могли бы использовать
Знак?: В скобках в .Net означает, что он не захватывает, и просто используется для группировки терминов | (или) заявление.
4
Kibbee
4 Сен 2008 в 16:37
Основы
Чтобы быстро изучить регулярные выражения с помощью этого руководства, перейдите на Regex101, где вы можете создавать шаблоны регулярных выражений и тестировать их на строках (тексте), которые вы предоставляете.
Когда вы откроете сайт, вам нужно будет выбрать вариант JavaScript, который мы будем использовать в этом руководстве. (Синтаксис регулярных выражений в основном одинаков для всех языков, но есть некоторые незначительные отличия.)
Далее, вам необходимо отключить в Regex101 флаги global и multi line. Мы рассмотрим их в следующем разделе. А пока мы сосредоточимся на простейшей форме регулярного выражения, которую мы можем создать. Введите следующее:
поле ввода регулярного выражения: cat
тестовая строка: rat bat cat sat fat cats eat tat cat mat CAT
Обратите внимание, что регулярные выражения в JavaScript начинаются и заканчиваются на /. Если бы вы написали регулярное выражение в коде JavaScript, оно выглядело бы как /cat/ без кавычек
В приведенном выше примере регулярное выражение соответствует строке «cat». Однако, как вы можете видеть на изображении выше, есть несколько «кошачьих» строк, которые не совпадают. В следующем разделе мы рассмотрим, почему.
Повторы¶
Повтор
За любым элементом регулярного выражения может следовать допустимое число повторений элемента.
| RegEx | Находит |
|---|---|
| ровно раз | |
| по крайней мере раз | |
| по крайней мере , но не более чем раз | |
| ноль или более, аналогично | |
| один или несколько, похожие на | |
| ноль или единица, похожая на |
То есть цифры в фигурных скобках определяются минимальное и максимальное количество повторов (совпадений во входном тексте).
эквивалентно и означает . совпадает или более раз.
Теоретически значение n и m не ограничены (можно использовать максимальное значение для 32-х битного числа).
| RegEx | Находит |
|---|---|
| , и | |
| , , но не | |
| , и , но не | |
| , , и т. д. | |
| , или , но не | |
| , или экземпляров ( это ) |
Жадность
в режиме захватывают как можно больше из входного текста, в режиме — как можно меньше.
По умолчанию все повторы являются . Используйте Чтобы сделать любой повтор .
Для строки :
| RegEx | Находит |
|---|---|
| пустую строку | |
Вы можете переключить все повторы в режим (, ниже мы используем ).
| RegEx | Находит |
|---|---|
Регулярные выражения в Java
В Java есть пакет java.util.regex, который позволяет работать с регулярными выражениями. В нем есть интерфейс MatchResult — результат операции сравнения, классы Matcher — механизм, который выполняет операции сопоставления последовательности символов путем интерпретации шаблона и Pattern — скомпилированное представление регулярного выражения.
У класса Pattern есть метод compile(), который возвращает Pattern, соответствующий регулярному выражению. Метод matches — сравнивает выражение с набором символов и возвращает true, false в зависимости от того совпали строки или нет.
Например проверка пароля, которую мы делали через метод equals может быть реализована более элегантно с помощью метода matches.
А как насчет проверить состоит ли строка только с цифр? С помощью вышеупомянутого метода сделать это легко.
Результат выполнения кода узнаете, когда скопируете и запустите программу у себя.
Метод matches также есть и у класса String. Программа выше будет работать корректно если заменить строку Pattern.matches(«+», string) на string.matches(«+»). Попробуйте поэкспериментировать.
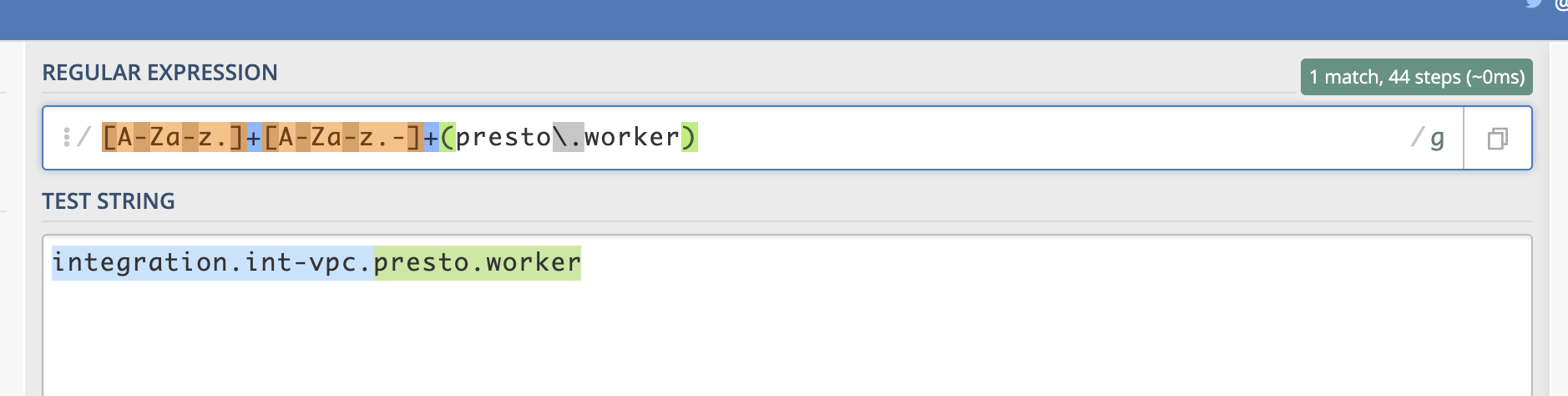


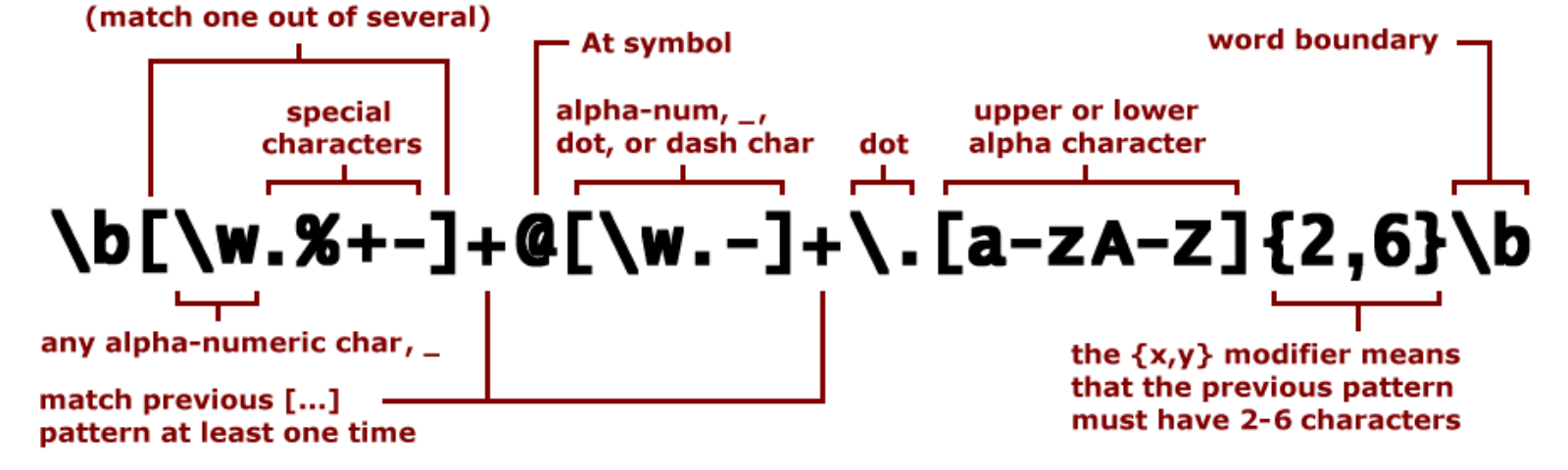
+ и есть регулярное выражение. Оно означает, что принимаются только символы от 0 до 9, а знак + означает, что их может быть один или несколько.
Поиск совпадений с использованием findall, search и match
Предположим, вы хотите извлечь все номера курсов, то есть 100, 213 и 156 из приведенного выше текста. Как это сделать?
Что делает re.findall()?
В приведенном выше коде специальный символ является регулярным выражением, которое соответствует любой цифре. В этой статье вы узнаете больше о таких шаблонах. Добавление к нему символа означает наличие по крайней мере 1 числа.
Подобно , есть символ , для которого требуется 0 или более чисел. Это делает наличие цифры не обязательным, чтобы получилось совпадение. Подробнее об этом позже.
В итоге, метод извлекает все вхождения 1 или более номеров из текста и возвращает их в список.
re.search() против re.match()
Как понятно из названия, ищет шаблоны в заданном тексте. Но, в отличие от , который возвращает согласованные части текста в виде списка, возвращает конкретный объект соответствия. Он содержит первый и последний индекс первого соответствия шаблону.
Аналогично, также возвращает объект соответствия. Но разница в том, что он требует, чтобы шаблон находился в начале самого текста.
В качестве альтернативы вы можете получить тот же результат, используя метод для объекта соответствия.
Проверка тега HTML
Описание:
Одно из наиболее полезных regexes в списке. Он соответствует любому тегу HTML с содержимым внутри. Как обычно, берём начало строки.
Сначала появляется имя тега. Это должна быть одна или несколько букв. Это первая группа захвата, она очень полезна, когда нам нужно взять закрывающий тег. Следующее — атрибуты тега. Это символ больше (>). Поскольку это необязательно, но я хочу, чтобы они совпадали с более чем одним символом, используется звезда. Знак плюс составляет атрибут и значение, а звезда говорит столько атрибутов, сколько вы хотите.
Затем идет третья группа без захвата. Внутри он будет содержать либо знак больше, некоторый контент и закрывающий тег; или пробелы, прямая косая черта и знак больше. Первая опция ищет знак больше, чем любое количество символов, и закрывающий тег. \1 который представляет содержимое, которое было захвачено в первой группе. В данном случае это имя тега. Теперь, если это невозможно сопоставить, мы хотим найти самозакрывающийся тег (например, тег img, br или hr). Это должно иметь один или несколько пробелов, за которыми следует «/>».
Регулярное выражение заканчивается концом строки.