
Небольшое введение
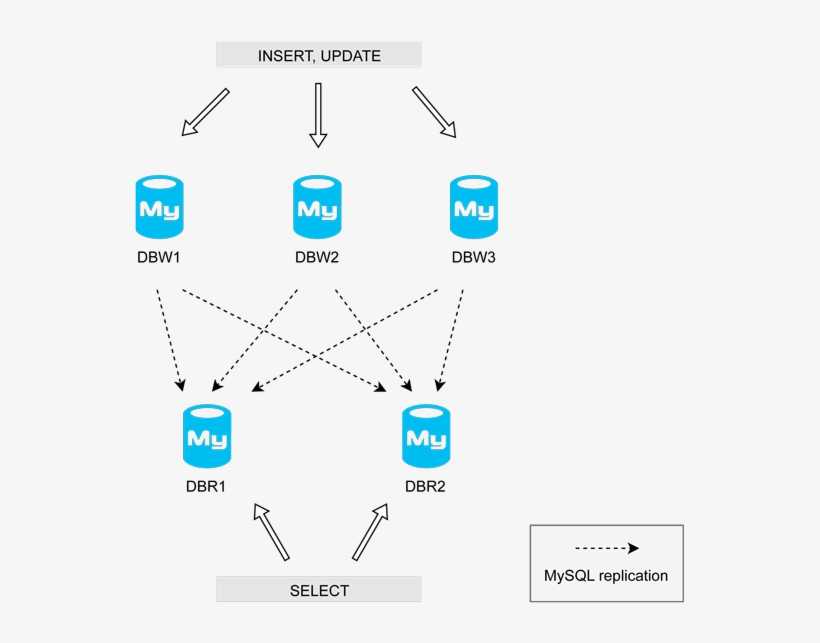
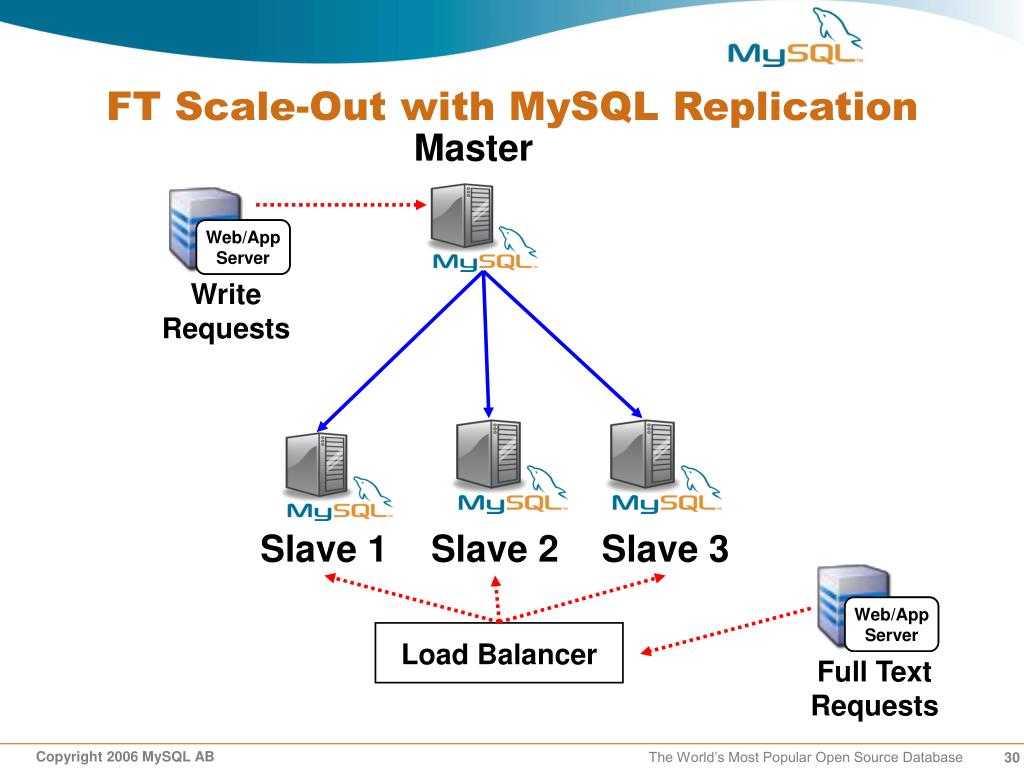
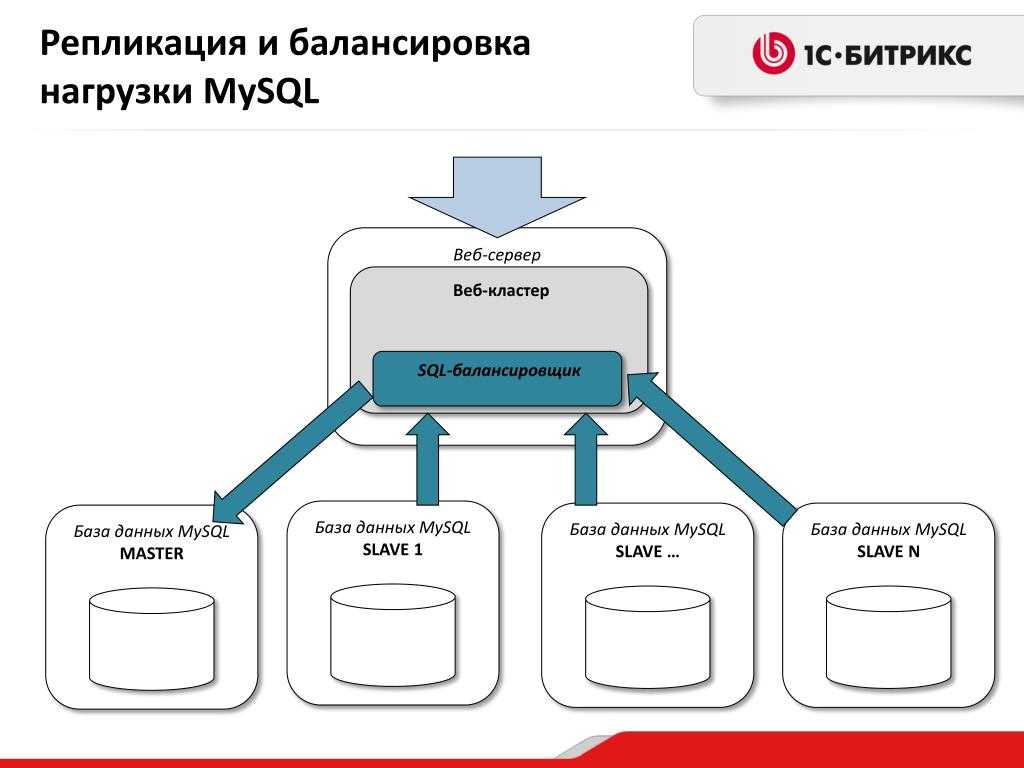
Репликация (от лат. replico — повторяю) — это тиражирование изменений данных с главного сервера БД на одном или нескольких зависимых серверах. Главный сервер будем называть мастером, а зависимые — репликами.
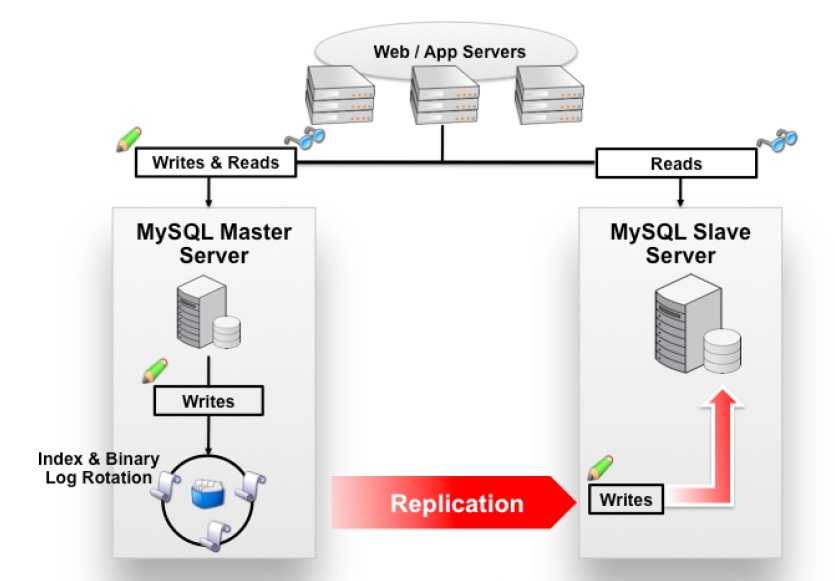
Изменения данных, происходящие на мастере, повторяются на репликах, но не наоборот. Поэтому запросы на изменение данных (INSERT, UPDATE, DELETE и т. д.) выполняются только на мастере, а запросы на чтение данных (проще говоря, SELECT) могут выполняться как на репликах, так и на мастере. Процесс репликации на одной из реплик не влияет на работу других реплик, и практически не влияет на работу мастера.
При репликации содержимое БД дублируется на нескольких серверах. Зачем необходимо прибегать к дублированию? Есть несколько причин:
- производительность и масштабируемость. Один сервер может не справляться с нагрузкой, вызываемой одновременными операциями чтения и записи в БД. Выгода от создания реплик будет тем больше, чем больше операций чтения приходится на одну операцию записи в вашей системе.
- отказоустойчивость. В случае отказа реплики, все запросы чтения можно безопасно перевести на мастера. Если откажет мастер, запросы записи можно перевести на реплику (после того, как мастер будет восстановлен, он может принять на себя роль реплики).
- резервирование данных. Реплику можно “тормознуть” на время, чтобы выполнить mysqldump, а мастер — нет.
- отложенные вычисления. Тяжелые и медленные SQL-запросы можно выполнять на отдельной реплике, не боясь помешать нормальной работе всей системы.
Кроме того, есть некоторые другие интересные возможности. Поскольку на реплики передаются не сами данные, а запросы, вызывающие их изменения, мы можем использовать различную структуру таблиц на мастере и репликах. В частности, может отличаться тип таблицы (engine) или набор индексов. Например, для осуществления полнотекстового поиска мы можем на реплике использовать тип таблицы MyISAM, несмотря на то, что мастер будет использовать InnoDB.
ЗАПУСК MARIADB GALERA
После успешной настройки всех нод нам останется только запустить кластер Galera на первой ноде. Перед тем как мы сможем запустить кластер, вам нужно убедиться, что сервис MariaDB остановлен на всех серверах:
Дальше запустите скрипт создания нового кластера:
![]()
Проверить запущен ли кластер и сколько к нему подключено машин можно командой:
![]()
Сейчас там только одна машина, теперь перейдите на другой сервер и запустите ноду там:
Вы можете проверить прошел ли запуск успешно и были ли какие-либо ошибки командой:
![]()
Затем, выполнив ту же команду, вы убедитесь, что новая нода была автоматически добавлена к кластеру:
![]()
Чтобы проверить как работает репликация просто создайте базу данных на первой ноде:
![]()
Затем посмотрите действительно ли она была добавлена на всех других:
![]()
Как видите, действительно база данных автоматически появляется на другой машине. Репликация данных mysql работает.
Подготовка рабочей среды
Нужно установить и настроить две базы данных PostgreSQL.
В этом примере вы узнаете как это сделать с помощью двух виртуальных
CentOS Linux
на
VirtualBox
В этом примере:
у ведущего сервера (master) IP адрес 192.168.56.109 (master_ip)
у ведомого (slave/stand by) 192.168.56.110 (slave_ip)
Темы с которыми рекомендуется познакомиться для создания аналогичного сетапа:
-
CentOS Linux
-
VirtualBox
-
CentOS7 на VirtualBox
-
SSH
На каждом хосте установите
PostgreSQL
sudo yum install postgresql-server postgresql-contrib
Задайте пароль пользователю postgres
sudo passwd postgres
Залогиньтесь под этим пользователем
sudo su — postgres
Создайте ssh-ключ для этого пользователя.
На все появившиеся уведомления нажмите Enter.
Передайте ключ на другой сервер:
IP_адрес_другого_сервера
Инициализируйте базу данных и запустите сервер
cd /var/lib/pgsql
postgresql-setup initdb
/usr/bin/pg_ctl -D /var/lib/pgsql/data -l logfile start
На обоих хостах отройте порт 5432. Если вы не знаете как это сделать — инструкцию можно
найти в статье
Многопоточная репликация
До недавнего времени Mysql реплика работала всего в один поток. Тогда, даже если мастер и слейв идентичны по характеристикам, слейв все равно может отставать от мастера.
... slave-parallel-workers = 2 ...
# Включение репликации в 2 потока
Число задает количество потоков и может принимать значения от до . Значение отключит многопоточную обработку бинлога.
При включении этой настройки Mysql будет распределять обработку бинлога разных баз данных между разными потоками. Это даст возможность Mysql не ждать завершения операций в разных базах, а выполнять их параллельно. На мастере для этого ничего настраивать не нужно.
Понятно, что если у вас всего одна база данных, вы не получите прирост в производительности. Зато в версии Mysql 5.7 можно изменить тип распределения операций с помощью настройки в my.cnf:
... slave-parallel-workers = 2 ...
# Изменения типа параллелизации обработки бинлога
В таком случае, уже все операции (точнее закомиченные транзакции) из бинлога будут обрабатываться параллельно.
Создание связи между исходным сервером и сервером-репликой для запуска репликации входных данных
-
Настройте исходный сервер.
Все функции репликации входных данных выполняются хранимыми процедурами. Все процедуры можно найти в статье о хранимых процедурах репликации входных данных. Хранимые процедуры можно выполнять в оболочке MySQL или MySQL Workbench.
Чтобы создать связь между двумя серверами и начать репликацию, войдите на целевой сервер-реплику в Базе данных Azure для MySQL и задайте внешний экземпляр в качестве исходного сервера. Это делается с помощью хранимой процедуры на сервере Базы данных Azure для MySQL.
Необязательно: если вы хотите настроить репликацию на основе GTID, для связывания двух серверов необходимо использовать указанную ниже команду.
-
master_host: имя узла исходного сервера.
-
master_user: имя пользователя для исходного сервера
-
master_password: пароль для исходного сервера
-
master_port: номер порта, на котором исходный сервер прослушивает подключения (порт по умолчанию, на котором прослушивается MySQL, — 3306).
-
master_log_file: имя файла двоичного журнала из выполняемой команды .
-
master_log_pos: позиция в двоичном журнале из выполняемой команды .
-
master_ssl_ca: контекст сертификата центра сертификации. Если протокол SSL не используется, передайте пустую строку.
Этот параметр рекомендуется передавать в виде переменной. Дополнительные сведения см. в следующих примерах.
Примечание
Если исходный сервер размещается на виртуальной машине Azure, установите для параметра «Разрешить доступ к службам Azure» значение «ВКЛ», чтобы разрешить исходному серверу и серверу реплики взаимодействовать друг с другом. Этот параметр можно изменить в параметрах Безопасность подключения. Дополнительные сведения см. в разделе Управление правилами брандмауэра с помощью портала.
Примеры
Репликация с использованием SSL
Переменная создается путем выполнения следующих команд MySQL:
Репликация с использованием SSL настраивается между исходным сервером, размещенным в домене companya.com, и сервером-репликой, размещенным в Базе данных Azure для MySQL. Эта хранимая процедура выполняется на реплике.
Репликация без SSL
Репликация без SSL настраивается между исходным сервером, размещенным в домене companya.com, и сервером-репликой, размещенным в Базе данных Azure для MySQL. Эта хранимая процедура выполняется на реплике.
-
-
Настройте фильтрацию.
Если вы хотите пропустить репликацию некоторых таблиц из главной таблицы, измените параметр на сервере реплики. Вы можете указать несколько шаблонов таблиц в списке с разделителями-запятыми.
Чтобы узнать больше об этом параметре, ознакомьтесь с документацией по .
Для изменения этого параметра используйте портал Azure или Azure CLI.
-
Запустите репликацию.
Вызовите хранимую процедуру , чтобы запустить репликацию.
-
Проверьте состояние репликации.
Вызовите команду на сервере-реплике, чтобы просмотреть состояние репликации.
Если и имеют состояние «yes» (да), а значение равно «0», репликация выполняется правильно. указывает величину задержки на реплике. Если значение не равно «0», это означает, что реплика обрабатывает обновления.
-
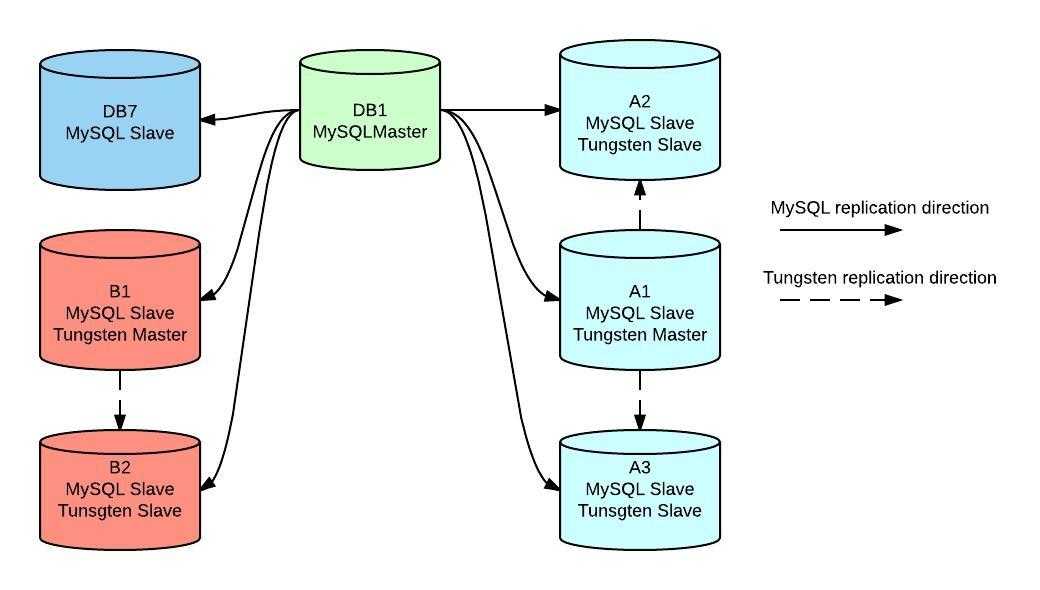







Создание резервной копии и восстановление исходного сервера
-
Определите, какие базы данных и таблицы необходимо реплицировать в Базу данных Azure для MySQL, и создайте дамп с исходного сервера.
Для выгрузки баз данных с основного сервера можно использовать программу mysqldump. Подробные сведения см. в статье о дампе и восстановлении. Создавать резервную копию библиотеки MySQL и тестовой библиотеки нет необходимости.
-
Необязательно: если вы хотите использовать репликацию на основе GTID, вам потребуется определить GTID последней транзакции, выполненной на основном сервере. Чтобы найти GTID последней транзакции на главном сервере, можно использовать указанную ниже команду.
-
Настройте для исходного сервера режим для чтения и записи.
После выгрузки базы данных переведите исходный сервер MySQL обратно в режим чтения и записи.
-
Восстановите файл дампа на новом сервере.
Восстановите файл дампа на сервере, созданном в Базе данных Azure для MySQL. Чтобы узнать, как восстановить файл дампа на сервере MySQL, см. статью о дампе и восстановлении. Если файл дампа имеет большой размер, отправьте его на виртуальную машину в Azure в том же регионе, где располагается сервер-реплика. Восстановите его на сервере Базы данных Azure для MySQL с виртуальной машины.
-
Необязательно: найдите GTID восстановленного сервера в Базе данных Azure для MySQL, чтобы убедиться, что он совпадает с этим значением на исходном сервере. Чтобы найти очищенное значение GTID (gtid_purged) на сервере реплики Базы данных Azure для MySQL, можно использовать указанную ниже команду. Чтобы репликация на основе GTID работала, значение gtid_purged должно быть таким же, как и gtid_executed на главном сервере, которое вы нашли на шаге 2.
Настройка slave
Настройка slave или, как сейчас стало модно писать, stand by сервера
начинается также с определения директории с настройками.
su — postgres -c «psql -c ‘SHOW data_directory;'»
Password:
data_directory
———————
/var/lib/pgsql/data
(1 row)
Или
echo $PGDATA
/var/lib/pgsql/data
-bash-4.2$ su — postgres -c «psql -c ‘SHOW config_file;'»
Password:
config_file
————————————-
/var/lib/pgsql/data/postgresql.conf
(1 row)
Залогиньтесь под обычным пользователем (не postgres)
Остановите сервис postgresql:
sudo systemctl stop postgresql
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Multiple identities can be used for authentication:
1. andrei
2. tester
Choose identity to authenticate as (1-2): 1
Password:
==== AUTHENTICATION COMPLETE ===
Залогиньетсь под postgres и на всякий случай, создайте архив базы:
sudo su — postgres
tar -czvf /tmp/data_pgsql.tar.gz /var/lib/pgsql/data
В данном примере мы сохраним всё содержимое каталога
/var/lib/pgsql/data
в виде архива
/tmp/data_pgsql.tar.gz.
ls /tmp | grep pgsql
data_pgsql.tar.gz
Либо просто скопируете в другую папку
sudo su — postgres
bash-4.2$ mv /var/lib/pgsql/data/ /var/lib/pgsql/data.old
Удаляем содержимое каталога с данными:
rm -rf /var/lib/pgsql/data/*
ls /var/lib/pgsql/data
Теперь нужно распаковать архив, который получен с мастера
tar xvfP /tmp/db_file_backup.tar
Удалите
postmaster.pid
чтобы слейв не видел pid мастера как свой
rm -f /var/lib/pgsql/data/postmaster.pid
В файле
postgresql.conf
Укажите listen_addresses и включите hot_standby
vi /var/lib/pgsql/data/postgresql.conf
Настройка репликации MySQL
В этой инструкции мы будем использовать для примера Ubuntu 16.04 и MariaDB версии 10.1. Перед тем, как начать полностью обновите систему:
Поскольку мы будем развертывать нашу конфигурацию на нескольких узлах, нужно выполнить операции обновления на всех них. Если сервер баз данных MariaDB еще не установлен, его нужно установить. Сначала добавьте репозиторий и его ключ:
![]()
Когда обновление списка пакетов завершено, установите MariaDB командой:
![]()
Пакет rsync нам понадобится для выполнения непосредственно синхронизации. Когда установка будет завершена, вам необходимо защитить базу данных с помощью скрипта mysql_secure_installation:
![]()
По умолчанию разрешен гостевой вход, есть тестовая база данных, а для пользователя root не задан пароль. Все это надо исправить. Читайте подробнее в статье установка MariaDB в Ubuntu. Если кратко, то вам нужно будет ответить на несколько вопросов:
Когда все будет готово, можно переходить к настройке нод, между которыми будет выполняться репликация баз данных mysql. Сначала рассмотрим настройку первой ноды. Можно поместить все настройки в my.cnf, но лучше будет создать отдельный файл для этих целей в папке /etc/mysql/conf.d/.
Добавьте такие строки:
![]()
Здесь адрес 192.168.56.101 — это адрес текущей ноды. Дальше перейдите на другой сервер и создайте там такой же файл:
![]()
Аналогично тут адрес ноды — 192.168.0.103. Остановимся на примере с двумя серверами, так как этого достаточно чтобы продемонстрировать работу системы, а добавить еще один сервер вы можете, прописав дополнительный IP адрес в поле wsrep_cluster_address. Теперь рассмотрим что означают значения основных параметров и перейдем к запуску:
- binlog_format — формат лога, в котором будут сохраняться запросы, значение row сообщает, что там будут храниться двоичные данные;
- default-storage-engine — движок SQL таблиц, который мы будем использовать;
- innodb_autoinc_lock_mode — режим работы генератора значений AUTO_INCREMENT;
- bind-address — ip адрес, на котором программа будет слушать соединения, в нашем случае все ip адреса;
- wsrep_on — включает репликацию;
- wsrep_provider — библиотека, с помощью которой будет выполняться репликация;
- wsrep_cluster_name — имя кластера, должно соответствовать на всех нодах;
- wsrep_cluster_address — список адресов серверов, между которыми будет выполняться репликация баз данных mysql, через запятую;
- wsrep_sst_method — транспорт, который будет использоваться для передачи данных;
- wsrep_node_address — ip адрес текущей ноды;
- wsrep_node_name — имя текущей ноды.
Настройка репликации MySQL почти завершена. Остался последний штрих перед запуском — это настройка брандмауэра. Сначала включите инструмент управления правилами iptables в Ubuntu — UFW:
![]()
Затем откройте такие порты:
![]()
7 ответов
74
Чтобы полностью отключить репликацию с помощью мастер-мастер-установки, вы должны сделать следующее на каждом подчиненном устройстве:
- (используйте для MySQL 5.5.16 и более поздних версий)
- Отредактируйте my.cnf и удалите любую информацию (если она есть), которая ссылается на опции «master -…» или «replicate -…». У вас может не быть ничего в my.cnf, так как репликация также может быть настроена динамически.
- Перезапустить mysqld.
17
Я знаю, что это старый вопрос, но я обнаружил, что мне также нужно сбросить ведомые переменные. Если вы используете «бла», как предлагалось, сервер будет пытаться запустить, чтобы найти сервер «бла».
Вы можете проверить, что машина больше не является подчиненным
10
На ведомом сервере (серверах):
- Запустите «stop slave», чтобы остановить репликацию.
- Запустите «reset slave», чтобы сообщить подчиненному серверу забыть его положение в двоичном журнале, полученном с главного сервера.
- Добавьте «skip-slave-start» в my.cnf, чтобы предотвратить запуск репликации при перезагрузке MySQL.
Нет необходимости перезапускать MySQL на главном или подчиненном сервере. Полную документацию можно найти в разделе 19 справочного руководства MySQL.
Я бы рекомендовал оставить остальные настройки репликации на месте, если вы решите вернуться к своей предыдущей конфигурации. Таким образом, вам просто нужно будет перетащить данные и сбросить рабочую позицию (не забудьте удалить запуск с slave-slave-start), а не воссоздать настройку цельной ткани.
6
Независимо от версии MySQL, самый полный способ сделать это:
Это должно работать для его последней версии, поскольку параметр репликации все еще задерживается в ОЗУ для MySQL 5.5.
Я просто ответил на аналогичный вопрос по этому вопросу:
5
Редактирование только файла my.cnf недостаточно для отключения репликации. Фактически, это уже не рекомендуемый способ его включения. Ввод записей в файл my.cnf эффективен только для следующего запуска и ведет себя так, как если бы вы ввели команду в клиент mysql:


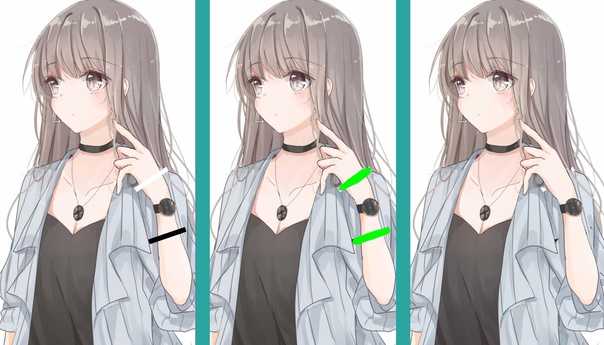


MySQL > изменить мастер на master_host = ‘blah’, master_user = ‘blah’, master_password = ‘blah’ …;
Оба этих метода создадут файл в каталоге данных master.info . Пока этот файл существует, сервер будет пытаться реплицироваться, используя данные там. «СБРОС СЛАВЫ»; команда, указанная в первом ответе, избавится от файла master.info (а также файла relay-log.info ). Как уже упоминалось в первом ответе, вы также хотите удостовериться, что у вас нет этой информации о конфигурации в файле my.cnf, иначе при следующем перезапуске сервера регистрация снова будет включена.
4
Один ответ здесь:
* Отредактируйте конфигурационный файл MySQL: /etc/my.cnf и удалите следующие 7 строк в раздел под названием :
Перезагрузите MySQL.
2
Я добавляю это к ответу Харрисона Фиск:
Если вы использовали , то перезагрузка не требуется.
Кроме того, вы можете включить события, которые были отключены на подчиненном устройстве:
Для каждого из них:
Распространенные ошибки
Ошибка: ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
Решение:
mysql> reset slave; Query OK, 0 rows affected (0.00 sec) mysql> CHANGE MASTER TO MASTER_HOST='192.168.1.1', MASTER_USER='rep_user', MASTER_PASSWORD='rep_user', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000005', MASTER_LOG_POS=120, MASTER_CONNECT_RETRY=10; Query OK, 0 rows affected, 2 warnings (0.05 sec) mysql> start slave;
Ошибки:
- Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND for deleting row
- Can’t drop database ‘********’: database doesn’t exist’
- Error ‘Duplicate entry’
- Could not execute Write_rows event on table ***********: Duplicate entry ‘XXXXXXXX’ for key ‘ххххххх’, Error_code: 1062
Решение: Эти ошибки можно просто скипнуть, но посмотреть их причины сначала.
mysql -uroot -p -e 'STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1; START SLAVE;'
Ошибка: Relay log read failure (#1594): Could not parse relay log event entry.
Решение:
#Подключаемся к серверу, где возникла проблема и смотрим статус репликации
root@server:~# mysql -uroot -p -e 'show slave status \G;' | grep -E 'Relay_Master_Log_File|Exec_Master_Log_Pos'
Relay_Master_Log_File: mysql-bin.008189
Exec_Master_Log_Pos: 71687831
# Останавливаем репликацию и обновляем бин-лог и позицию
#master_log_file = Relay_Master_Log_File = mysql-bin.008189
#master_log_pos = Exec_Master_Log_Pos = 71687831
root@server:~# mysql -uroot -p -e "STOP SLAVE;"
root@server:~# mysql -uroot -p -e "CHANGE MASTER TO master_log_file='mysql-bin.008189', master_log_pos=71687831;"
#Стартуем слейв
root@server:~# mysql -uroot -p218e5ccb4a834382%FBF87B604F1FE14B -e "START SLAVE;"
Настройка master
Сперва нужно настроить ведущий сервер (master)
Расположение конфигурационного файла
postgresql.conf
можно получить выполнив
-bash-4.2$ su — postgres -c «psql -c ‘SHOW config_file;'»
Password:
config_file
————————————-
/var/lib/pgsql/data/postgresql.conf
(1 row)
vi /var/lib/pgsql/data/postgresql.conf
wal_level = hot_standby
max_wal_senders = 1
wal_keep_segments = 50
- 192.168.56.109 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
-
wal_level
указывает, сколько информации записывается в WAL (Write Ahead Log — журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Перезапустить postgresql от обычного пользователя
$ sudo systemctl restart postgresql
Снова залогиньтесь под postgres
sudo su — postgres
В файле
pg_hba.conf
добавьте
slave_ip
vi /var/lib/pgsql/data/pg_hba.conf
host replication postgres 192.168.56.110/32 trust
Теперь нужно сделать копию данных с мастера и отправить на слейв
Если вы вышли из пользователя postgres — залогиньтесь снова
su — postgres
Бэкап (я делаю с пустой базы, сразу после установки)
psql -c «SELECT pg_start_backup(‘replbackup’);»
pg_start_backup
——————
0/2000020
(1 row)
tar cfP /tmp/db_file_backup.tar /var/lib/pgsql/data
psql -c «SELECT pg_stop_backup();»
Скорее всего появится ошибка
NOTICE: WAL archiving is not enabled; you must ensure that all required WAL segments are copied through other means to complete the backup
pg_stop_backup
—————-
0/20000E0
(1 row)
Так как скопирована будет вся директория, можно сказать, что мы пользуемся other means
Отправьте на слейв
scp /tmp/db_file_backup.tar andrei@192.168.56.110:/tmp/
На рабочей Master-ноде
Блокируем все таблицы всех баз для чтения и записи:
mysql> FLUSH TABLES WITH READ LOCK; SET GLOBAL read_only = ON;
И выводим состояние работы СУРБД:
mysql> show master status\G
Результат будет, примерно, таким:
File: mysql-bin.000015
Position: 6315
Binlog_Do_DB:
Binlog_Ignore_DB: information_schema,mysql
Запомним или запишем значения для File и Position. Они понадобятся при восстановлении вторичной ноды кластера.
Теперь выходим из командной оболочки базы:
mysql> \q
и создаем дамп рабочих баз:
# mysqldump -uroot -p -v —databases db1 db2 > /tmp/mydb_dump.sql
* данная команда сделает дамп баз db1, db2 и сохранит его в файл /tmp/mydb_dump.sql.
Теперь снова подключаемся к MySQL:
# mysql -uroot -p
и снимаем ранее установленные блокировки:
mysql> SET GLOBAL read_only = OFF;
Отключаемся:
mysql> \q
Полученный ранее файл с резервной копией переносим на второй сервер при помощи такой команды:
# scp /tmp/mydb_dump.sql dmosk@192.168.166.156:/tmp
* в данном примере, мы скопируем созданный нами дамп /tmp/mydb_dump.sql в каталог /tmp сервера 192.168.166.156 подключившись под учетной записью dmosk.
Мотивация
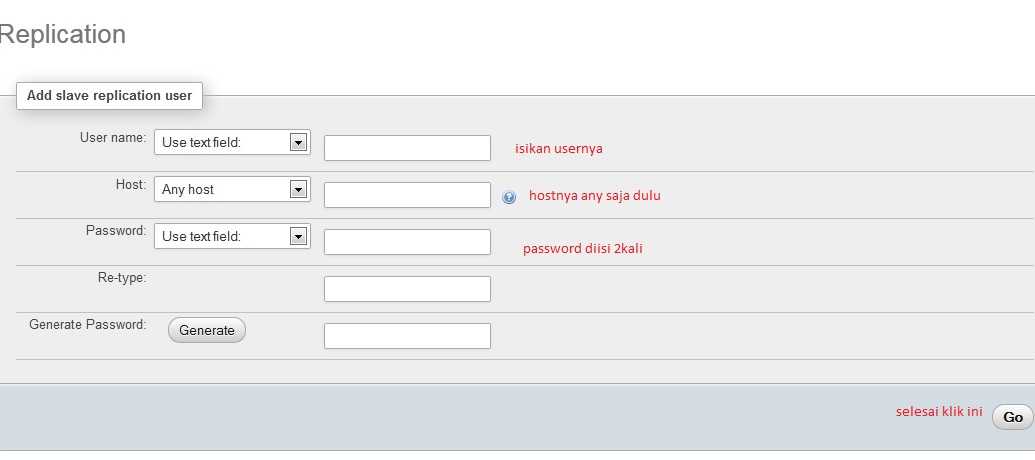
Репликация – это очень просто. Репликация означает копирование состояние одного сервера на другой. То есть – любые изменения, примененные на основной сервер (master) будут скопированы на его “заместителя” (slave). Для чего это нужно:
- Для распределения нагрузки. Slave не может записывать данные, но с него можно эти данные читать. По личному опыту, более 80% нагрузки на базу данных – это именно чтение в том или ином виде. Slave (или несколько) позволяют разгрузить мастер. Установка нескольких дешевых серверов чаще всего обходится дешевле, чем обновления одного, но дорогого (горизонтальное масштабирование дешевле вертикального. В некоторых случаях мешает закон Амдаля, но у нас не тот случай).
- Для построения отказоустойчивых систем. В случае, если с мастером что-то случилось – превратить slave в master можно буквально за секунды, это снижает время простоя. Восстановление из резервной копии займет много больше времени. Кроме того, состояние slave-а будет максимально приближено к состоянию master-а на момент отказа. Бэкапы обычно делаются по расписанию. То есть – все данные, записанные после создания резервной копии и до отказа мастера можно считать потерянными безвозвратно.
Как и у всякой технологии, у репликации есть ограничения:
- Репликация в PostgreSQL – исключительно однонаправленная (master -> slave). PostgreSQL не поддерживает мультимастер (есть внешние решения, но они выходят за рамки этой статьи)
- Репликация дополняет бэкап, но не заменяет его. Реплика спасет данные, если с мастер-сервером что-то случилось: отказ электричества, сервер сгорел, жесткие диски умерли, пожар в ЦОД, правоохранительные органы изъяли оборудование и т.д. Репликация никак не поможет при логической ошибке (код запорол данные) или ошибке оператора (“призрак человека с консолью”).
- Особенность именно PostgreSQL — репликация возможна только всего сервера целиком, нельзя выбрать базы, которые будут реплицироваться (или не будут).
- По умолчанию репликация — асинхронная. Это значит, что мастер пишет данные постоянно, а slave вытаскивает изменения и применяет их у себя по мере возможности. Вообще, в норме это не вызывает проблем. Но, если вдруг у slave возникли с этим проблемы (мастер несравнимо мощнее и slave не успевает применять изменения, или проблемы с сетью между мастером и slave) – master “убежит” вперед. Данные при этом потеряны не будут, и slave догонит мастер, как только сможет. Такую ситуацию несложно отслеживать (дальше покажу, как), просто нужно иметь это ввиду. Репликацию можно сделать синхронной, чтобы гарантировать абсолютную консистентность данных между серверами, но это удорожает транзакции – производительность записи упадет, а нагрузка – вырастет.
- Репликация использует отдачу WAL-сегментов с мастера на slave-ы. Эти сегменты надо на мастере где-то хранить, то есть нужно запланировать дополнительное место для них.
- Репликация возможна только между серверами с общей мажорной версией (то есть реплицироваться 9.5 -> 9.5 можно, а с 9.4 -> 10.0 – нельзя). На всякий случай напомню, что до версии 10.0 обновления 9.4 -> 9.5 считались мажорными, а не минорными. У разных версий разный формат хранения данных.
- потоковая репликация возможна только в PostgreSQL 9 и выше. Она не работает в 7 и 8 версиях.
How to Configure MySQL Master-Slave Replication on CentOS 7
4 Января 2020
|
CentOS
![]()
Репликация MySQL — это процесс, который позволяет автоматически копировать данные с одного сервера базы данных на один или несколько серверов.
MySQL поддерживает ряд типов репликации, при этом тип Master / Slave является одной из наиболее известных, в которой один сервер базы данных выступает в качестве главного, а один или несколько серверов действуют в качестве ведомых. По умолчанию репликация выполняется асинхронно, когда ведущий отправляет события, описывающие изменения базы данных, в свой двоичный журнал, а ведомые запрашивают события, когда они готовы.
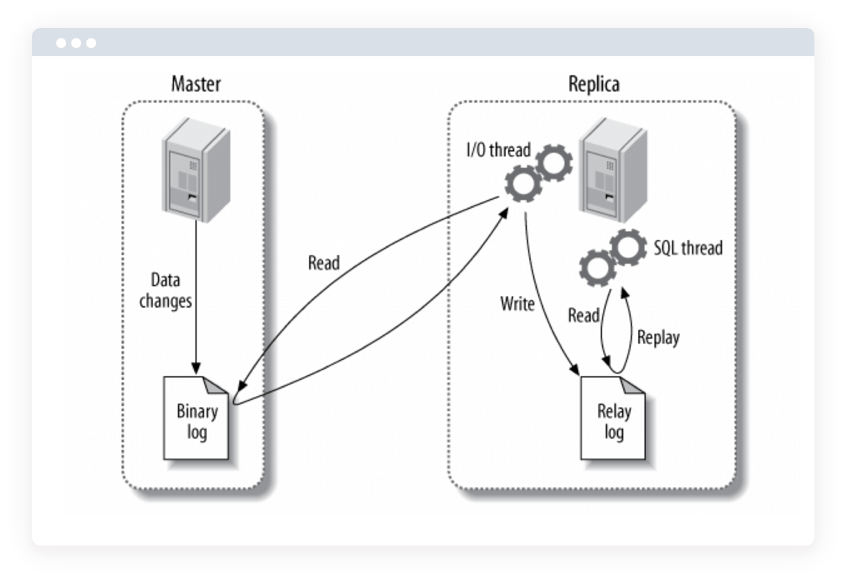
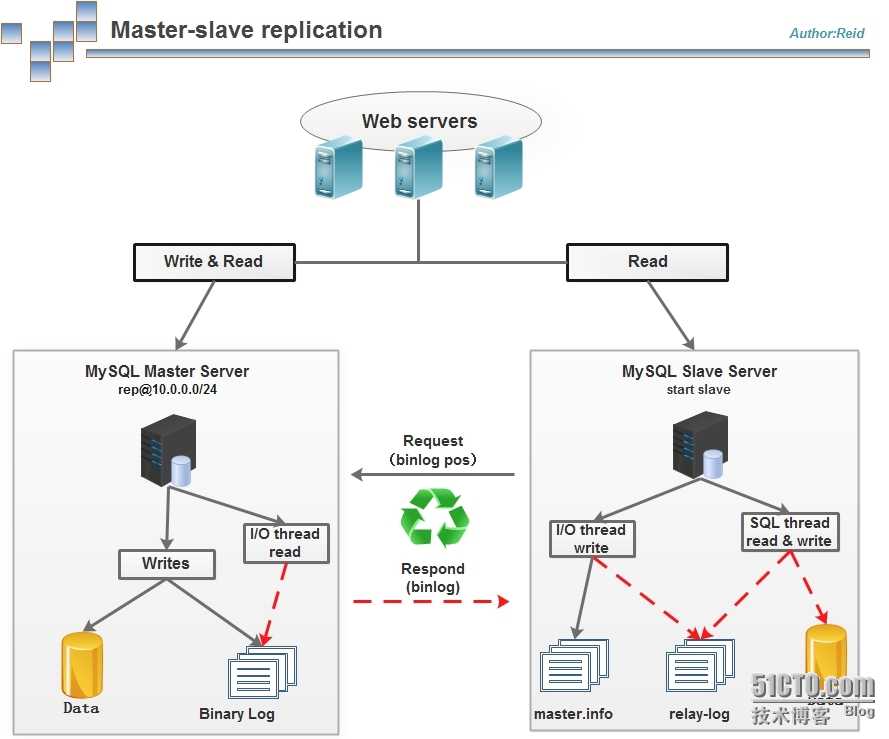
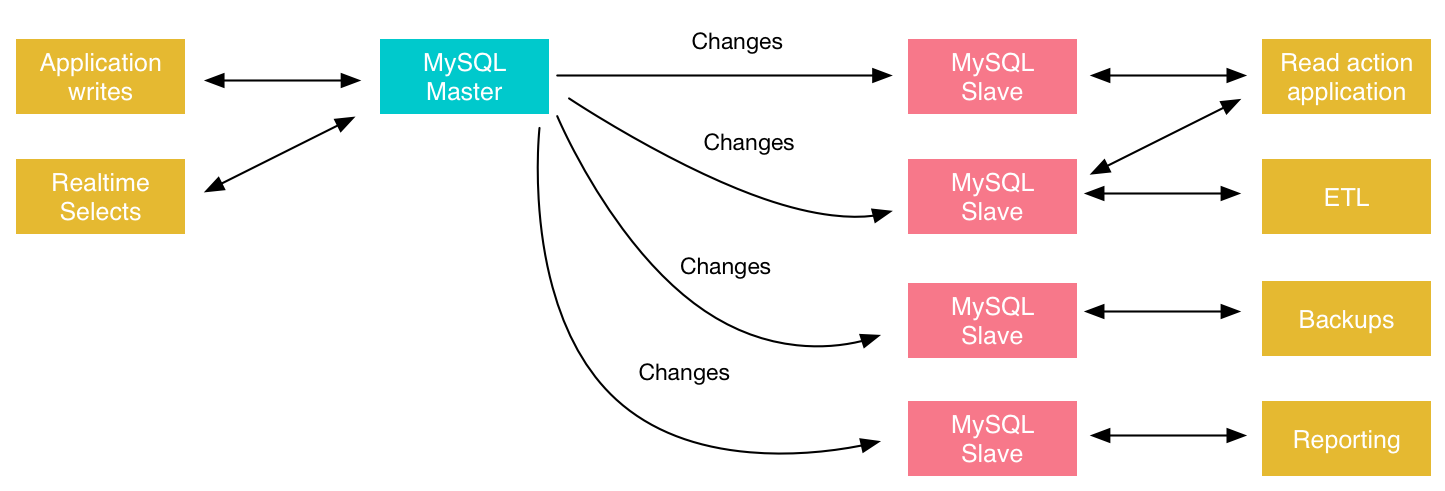
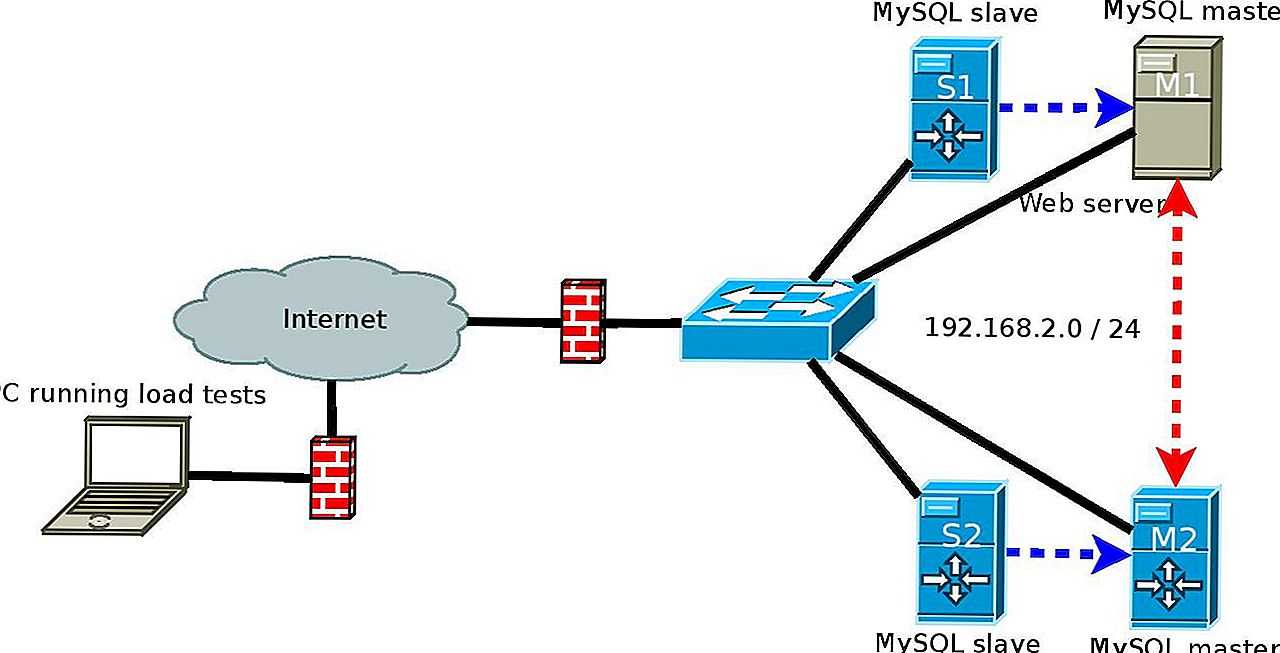
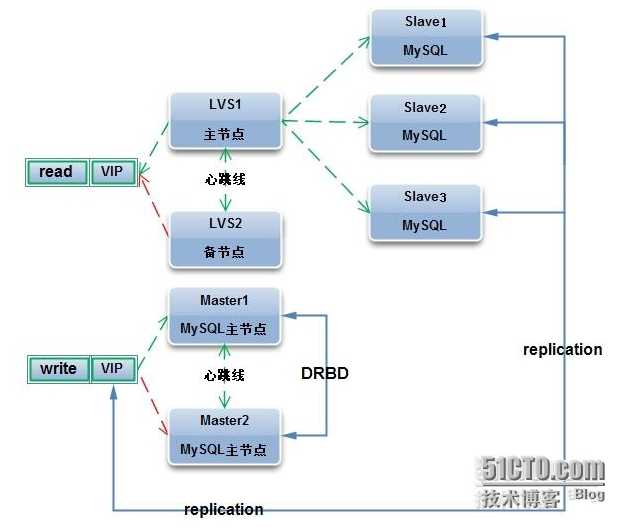
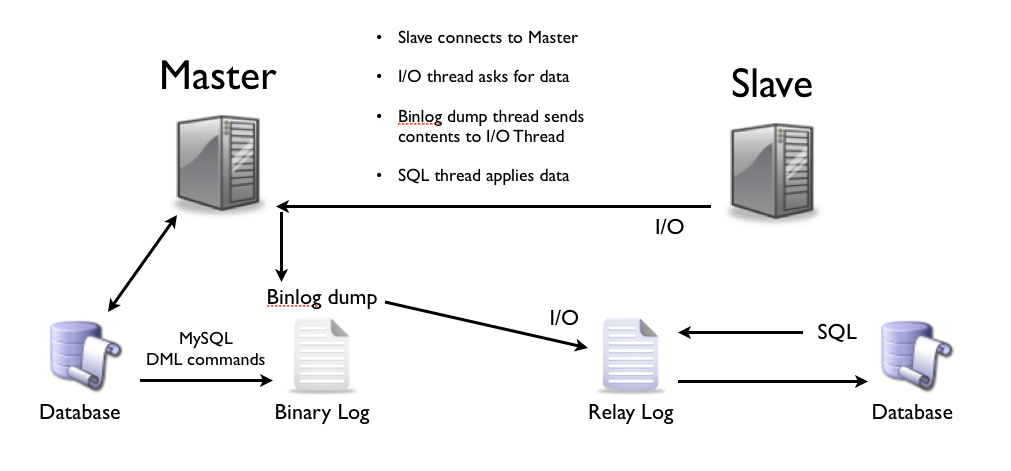
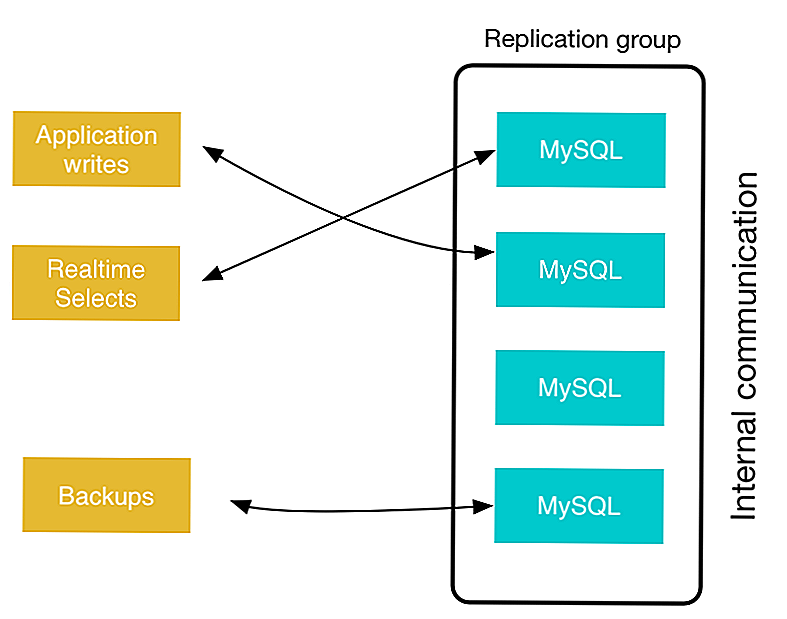
Этот тип репликации лучше всего подходит для развертывания реплик чтения для масштабирования чтения, оперативного резервного копирования баз данных для аварийного восстановления и аналитических заданий.
В этом примере мы предполагаем, что у вас есть два сервера под управлением CentOS 7, которые могут взаимодействовать друг с другом через частную сеть. Если ваш хостинг-провайдер не предоставляет частные IP-адреса, вы можете использовать публичные IP-адреса и настроить брандмауэр так, чтобы трафик на порт 3306 передавался только из надежных источников.
Серверы в этом примере имеют следующие IP-адреса:
Установите MySQL
По умолчанию репозитории CentOS 7 не содержат пакетов MySQL, поэтому мы установим MySQL из их официального репозитория Yum. Чтобы избежать каких-либо проблем, мы установим одну и ту же версию MySQL 5.7 на оба сервера.
Установите MySQL на главный и подчиненный серверы:
После завершения установки запустите службу MySQL и включите ее автоматический запуск при загрузке с помощью:
Когда сервер MySQL запускается в первый раз, для корневого пользователя MySQL генерируется временный пароль. Чтобы найти пароль, используйте следующую команду grep :
Запустите команду, чтобы установить новый пароль root и повысить безопасность экземпляра MySQL:
Введите временный пароль root и ответьте (да) на все вопросы.
Новый пароль должен содержать не менее 8 символов и содержать как минимум одну заглавную букву, одну строчную букву, одну цифру и один специальный символ.
Настройте главный сервер
Сначала мы настроим главный сервер MySQL и внесем следующие изменения:
- Настройте сервер MySQL для прослушивания частного IP .
- Установите уникальный идентификатор сервера.
- Включите двоичное ведение журнала.
Для этого откройте файл конфигурации MySQL и добавьте в раздел следующие строки :
Master: /etc/my.cnf
После этого перезапустите службу MySQL, чтобы изменения вступили в силу.
Следующим шагом является создание нового пользователя репликации. Войдите на сервер MySQL от имени пользователя root:
В командной строке MySQL выполните следующие SQL-запросы, которые создадут пользователя и предоставят пользователю привилегию:
Убедитесь, что вы изменили IP-адрес с вашего ведомого IP-адреса. Вы можете назвать пользователя, как вы хотите.
Находясь в приглашении MySQL, выполните следующую команду, которая выведет двоичное имя файла и положение.
Обратите внимание на имя файла «mysql-bin.000001» и «1427». Эти значения понадобятся вам при настройке подчиненного сервера
Эти значения, вероятно, будут отличаться на вашем сервере.
Настройте подчиненный сервер
Как и в случае с главным сервером, мы внесем следующие изменения в подчиненный сервер:
- Настройте сервер MySQL для прослушивания частного IP
- Установите уникальный идентификатор сервера
- Включить бинарное ведение журнала
Откройте файл конфигурации MySQL и отредактируйте следующие строки:
Slave: /etc/my.cnf
Перезапустите службу MySQL:
Следующим шагом является настройка параметров, которые подчиненный сервер будет использовать для подключения к главному серверу. Войдите в оболочку MySQL:
Сначала остановите подчиненные устройства:
Выполните следующий запрос, который настроит подчиненное устройство для репликации мастера:
Убедитесь, что вы используете правильный IP-адрес, имя пользователя и пароль. Имя и позиция файла журнала должны совпадать со значениями, которые вы получили от главного сервера.
После этого запустите подчиненные устройства.
Проверьте конфигурацию
На этом этапе у вас должна быть работающая настройка репликации Master / Slave.
Чтобы убедиться, что все работает должным образом, мы создадим новую базу данных на главном сервере:
Войдите в подчиненную оболочку MySQL:
Выполните следующую команду, чтобы получить список всех баз данных :
Вы заметите, что база данных, которую вы создали на главном сервере, реплицируется на ведомое устройство:
В этом руководстве мы показали, как создать репликацию MySQL Master / Slave в CentOS 7.
Проверка статуса рабочей резьбы в ПРОЦЕССЛИСТЕ ПОСЕЩЕНИЯ
Рабочие потоки будут указаны как «системные пользователи» в SHOW PROCESSLIST . В их состоянии будет отображаться запрос, над которым они сейчас работают, или может отображаться одно из следующих значений:
- «Ожидание работы от основных потоков SQL». Это означает, что рабочий поток простаивает, в данный момент для него нет работы.
- «Ожидание начала фиксации предыдущей транзакции перед началом следующей транзакции». Это означает, что предыдущий пакет транзакций, зафиксированных вместе на главном сервере, должен быть завершен первым. Этот рабочий поток ожидает этого, прежде чем он сможет начать работу со следующим пакетом.
- «Ожидание фиксации предыдущей транзакции». Это означает, что транзакция была выполнена рабочим потоком. Чтобы гарантировать фиксацию по порядку, рабочий поток ожидает фиксации, пока предыдущая транзакция не будет готова к фиксации перед ней.





