
Примеры драйверов virtio
Исходный код различных front-end драйверов вы можете найти в поддиректории ./drivers ядра Linux. Сетевой драйвер расположен в файле ./drivers/net/virtio_net.c, а драйвер блочного устройства находится в файле ./drivers/block/virtio_blk.c. В поддиректории ./drivers/virtio есть реализация интерфейсов (устройство , драйвер, очередь и кольцевая структура). Фрейворк также используется в исследованиях высокопроизводительных вычислительных систем для разработки средств взаимодействия виртуальных машин через совместно используемую память. В частности этот фреймворк был использован для реализации виртуализированного интерфейса шины PCI, для чего был использован драйвер . Более подробную информацию вы можете получить в разделе Ресурсы оригинала статьи.
Примеры использования инфраструктуры паравиртуализации сегодня можно найти в ядре Linux. Все, что вам нужно, это ядро, которое действует как гипервизор, гостевое ядро и QEMU для эмуляции устройств. Вы можете использовать либо KVM (модуль, который существует в хостовом ядра), либо , разработанный Расти Расселлом (модифицированное гостевое ядро Linux). Оба эти решения виртуализации поддерживают фреймворк (вместе с QEMU, используемом для эмуляции, и , используемом для управления виртуализацией).
Результатом работы Расти Расселла является более простой код драйверов паравиртуализации и более быстрая эмуляция виртуальных устройств
Но даже более важно то, что, как было обнаружено, фреймворк обеспечивает большую производительность (в 2-3 раза выше для сетевого ввода/вывода), чем имеющиеся в настоящий момент коммерческие решения. Это повышение производительности требует определенных затрат, но они окупаются, если в качестве гипервизора и гостевых систем используется Linux
4.2. Имена файлов устройств
4.2.1. Имена файлов устройств ATA (IDE)
Пути к файлам всех устройств в вашей системе будут начинаться с с последующим буквенным символом. Ведущий жесткий диск, подключенный к первому будет представлен в системе с помощью файла устройства /dev/hda, ведомый — с помощью файла устройства /dev/hdb. Именами файлов устройств, подключенных ко второму контроллеру, будут /dev/hdc и /dev/hdd.
Таблица 4.1. Имена файлов устройств IDE
| Контроллер | Роль устройства | Имя файла устройства |
|---|---|---|
| IDE 0 | Ведущее | /dev/hda |
| Ведомое | /dev/hdb | |
| IDE 1 | Ведущее | /dev/hdc |
| Ведомое | /dev/hdd |
Вполне вероятна ситуация, в которой в вашей системе будут созданы только файлы устройств и . Первый файл будет представлять единственный жесткий диск, а второй — привод для чтения дисков CDROM (по умолчанию настроенный как ведомое устройство).
4.2.2. Имена файлов устройств SCSI
Для файлов устройств используется аналогичная схема, но все пути к этим файлам начинаются с . В том случае, если для представления устройств, используемых в вашей системе, не хватит букв английского алфавита (устройство, представленное файлом /dev/sdz, не будет являться последним), в именах файлов устройств будет использоваться более одной буквы: /dev/sdaa, /dev/sdab и так далее. (Также позднее мы увидим, что тома обычно представлены файлами устройств /dev/md0, /dev/md1, и.т.д.).
Ниже приведен распределения имен файлов устройств в Linux между устройствами SCSI. Добавление диска SCSI или RAID-контроллера с меньшим значением идентификатора scsi id приведет к изменению схемы распределения имен устройств (сдвигу вперед на одну букву из алфавита для устройств с большими значениями идентификаторов scsi id).
Таблица 4.2. Имена файлов устройств SCSI
| Устройство | Идентификатор scsi id | Имя файла устройства |
|---|---|---|
| диск 0 | /dev/sda | |
| диск 1 | 1 | /dev/sdb |
| RAID-контроллер 0 | 5 | /dev/sdc |
| RAID-контроллер 1 | 6 | /dev/sdd |
В современной системе Linux файлы устройств будут использоваться для представления устройств SCSI и SATA, а также карт памяти SD, накопителей с интерфейсом USB, устройств ATA/IDE (устаревших) и твердотельных накопителей.
Каким образом решить проблему через BIOS, если функция не поддерживается хостом
Если аппаратная виртуализация включена, но ваш хост ее не поддерживает, поменяйте настройки БИОС. Чтобы это сделать, переведите на «Disabled» параметр «Intel Virtual Technology». В результате функция виртуализации в BIOS отключится. Рассмотрим, как именно это делается.
Чтобы зайти в настройки БИОС на устройстве с ОС Windows 7 и 8, во время загрузки системы нажимайте ответственную за это кнопку. На разных моделях компьютера за переход в BIOS могут отвечать клавиши ESC, Delete, F1, F2, F3, F4 или F8. В результате вместо обычной загрузки Виндовз вас перебросит в Биос. Что же делать в таком случае? Давайте разбираться.
В Windows 10 откройте «Настройки»:
- Нажмите кнопку «Пуск».
-
На боковой панели вы увидите иконку с изображением шестерни. Щелкните по ней.
Настройки Windows 10
-
В открывшемся окне выберите пункт «Обновление и безопасность».
Где искать раздел Обновление и безопасность
-
На левой панели будет отображаться список доступных опций. Нажмите на кнопку «Восстановление».
Где находится кнопка Recovery
-
В разделе «Расширенный запуск» кликните по клавише «Перезагрузить сейчас».
Где найти кнопку Restart
-
Выберите опцию «Устранение неисправностей».
Устранение неисправностей
-
Перейдите в «Продвинутые настройки».
Advanced options
-
Нажмите на пункт «Параметры встроенного ПО UEFI».
Параметры UEFI
-
Кликните по клавише «Перезапустить».
Кнопка Restart
После этого система выполнит перезагрузку, и компьютер начнет работу заново в БИОСе под вашим хостом. Если кнопки с параметрами UEFI нет, отключите функцию быстрого запуска в настройках системы. При отсутствии других вышеупомянутых шагов, сверьтесь с технической документацией к своему ПК.
4 ответа
Лучший ответ
В наши дни ядро Linux динамически заполняет / dev / в соответствии с правилами UDEV.
Позвольте мне сначала объяснить, как работают файлы устройств. Каждый файл устройства, обычно файл блочного устройства, имеет старший и младший номер. Эти числа фактически описывают, на какое устройство указывает файл. Имя при этом не играет никакой роли. Давайте посмотрим на наш конкретный случай дисков:
Здесь вы видите, что мой первый диск имеет различные разделы и что я загрузился 22 августа в 15:00, когда ядро создало файлы в соответствии с правилами. Вы также можете видеть, что старший номер — 8, а младшие номера используются для доступа к разделам (0 указывает на весь диск). Буква «b» в начале каждой строки означает, что каждый из них является специальным файлом «блочного устройства».
Как я уже сказал, ядро динамически создает файлы «в наши дни». Так было не всегда и не так в других системах Unix. Там файлы будут создаваться статически, и пользователь будет создавать эти файлы или манипулировать ими.
Вполне возможно создавать собственные файлы устройств с собственным именем и старшими / младшими номерами. См. mknod () для этого. Однако после повторной загрузки ваши пользовательские файлы исчезнут.
Вторая возможность — изменить правила UDEV. Правила обрабатываются во время загрузки системы и гарантируют постоянное согласованное поведение. Хорошее руководство по этим правилам можно найти здесь: http://www.reactivated.net/writing_udev_rules.html
Вы увидите, что можно определить правило, которое создает «sda *» с учетом конкретной информации об оборудовании, которая соответствует вашему устройству. Вам нужно будет заменить исходные правила, которые будут создавать sda, на ваши. Как это работает, зависит от вашего дистрибутива.







Поскольку я считаю, что это опасное дело для новичка, я не буду объяснять вам конкретные шаги; документ, который я указал выше, предоставит вам всю необходимую информацию, и вы действительно должны ее прочитать.
15
ypnos
24 Авг 2013 в 21:20
У меня такая же проблема, чтобы поменять имя диска и . Я попытался написать несколько похожих правил udev с вышеприведенным постом на моих собственных серверах HP. Но я использовал размер диска в
Перед этим правилом я нахожу размер устройств по и , который описан здесь: .
Но когда я пытаюсь проверить правило udev с помощью , я вижу в выводе следующую строку:
У меня ubuntu 18.04, и я обнаружил, что это невозможно (по крайней мере, в ubuntu 18.04) на основе этого сообщения: Есть ли способ изменить имена устройств в каталоге / dev?
1
Majid Hajibaba
1 Авг 2020 в 08:01
Почему бы вам не использовать UUID вместо того, чтобы полагаться на динамическое назначение? SD? всегда динамический, в то время как UUID имеет фиксированное значение и не изменяется, даже если вы измените дистрибутив или если вы установите свой жесткий диск на другой компьютер Linux, UUID будет таким же.
Sudo blkid покажет вам UUID, после чего вы сможете использовать его на fstab для монтирования разделов в любом месте.
-1
Maurice M
18 Мар 2015 в 09:02
Насколько я знаю, это невозможно. Система выберет порт SATA 1 как SDA и так далее. Однако вы можете использовать smartctl для определения серийного номера SDA / B или мигать светодиодами диска, где это возможно.
-2
James
24 Авг 2013 в 19:55
Подключение Яндекс Диска
Статью с настройкой дисков завершу описанием подключения Яндекс.Диска. Я лично давно и интенсивно его использую. У меня есть статья по созданию резервной копии сайта на яндекс.диск. Статья хоть и старая, но актуальная. Я продолжаю использовать предложенные там решения.
Яндекс диск можно подключить как системный диск по webdav. Скажу сразу, что работает это так себе, я давно им не пользуюсь в таком виде. Мне больше нравится работать с ним через консольный клиент linux.
Устанавливаем консольный клиент yandex-disk на Debian.
# echo "deb http://repo.yandex.ru/yandex-disk/deb/ stable main" | tee -a /etc/apt/sources.list.d/yandex-disk.list > /dev/null # apt install gnupg # wget http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | apt-key add - # apt update && apt install yandex-disk
Дальше запускаете начальную настройку.
# yandex-disk setup
После этого яндекс диск подключен к системе и готов к работе. Посмотреть его статус можно командой.
# yandex-disk status
Остановить или запустить Яндекс.Диск можно командами.
# yandex-disk stop # yandex-disk start
Файл конфигурации находится по адресу /root/.config/yandex-disk/config.cfg. Туда, к примеру, можно добавить список папок исключений, которые не нужно синхронизировать.
exclude-dirs="dir1,exclude/dir2,path/to/another/exclude/dir"
Консольный клиент поддерживает символьные ссылки. Я много где использовал его. В основном в скриптах по автоматизации бэкапов. К примеру, я останавливал сервис яндекс диска, готовил бэкапы к отправке. Упаковывал их архиватором с разбивкой архивов по размеру. Потом создавал символьные ссылки в папке яндекс диска и запускал синхронизацию. Когда она заканчивалась, удалял локальные файлы и останавливал синхронизацию.
Яндекс диск сильно тормозит и падает, если у вас много мелких файлов. Мне доводилось хранить в нем бэкапы с сотнями тысяч файлов. Передать их в облако напрямую было невозможно. Я паковал их в архивы по 2-10 Гб и заливал через консольный клиент. Сразу могу сказать, что это решение в пользу бедных. Этот облачный диск хорош для домашних нужд пользователей и хранения семейных фоток и видео. Когда у вас большие потоки данных, которые нужно постоянно обновлять, работа с яндекс диском становится сложной.
Во-первых, трудно мониторить такие бэкапы. Во-вторых, тяжело убедиться в том, что то, что ты залил в облако, потом нормально скачается и распакуется из бэкапа. Как запасной вариант для архивов, куда они будут складываться раз в неделю или месяц, подойдет. Но как основное резервное хранилище точно нет. Какие только костыли я не придумывал для Яндекс.Диска в процессе промышленной эксплуатации. В итоге все равно почти везде отказался. Да, это очень дешево, но одновременно и очень ненадежно. Он иногда падает. Это хорошо, что упал, можно отследить и поднять. Так же он может зависнуть и просто ничего не синхронизировать, при этом служба будет работать. Все это я наблюдал, когда пытался синхронизировать сотни гигабайт данных. Иногда у меня это получалось ![]()
Работа в debian с lvm
LVM тема обширная и раскрыть ее у меня задача не стоит. В сети все это есть, я сам постоянно пользуюсь поиском. Приведу только несколько команд из своей шпаргалки, которыми я регулярно пользуюсь для создания, подключения и изменения lvm дисков. Команды актуальны для любых дистрибутивов, где есть lvm, не только в Debian.
Допустим, вы подключили 2 новых диска или raid массива к серверу и хотите их объединить в единое адресное пространство. Я расскажу, как это сделать
Только сразу обращаю внимание, что подключать одиночные диски так не следует, если там будут храниться важные данные. Выход из строя любого из дисков объединенного раздела приведет к потере всех данных
Это в общем случае. Возможно их можно будет как-то вытащить, но это уже не тривиальная задача.
В системе у меня один диск /dev/sda, я добавил еще 2 — sdb и sdc.
# lsblk -a NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT fd0 2:0 1 4K 0 disk sda 8:0 0 20G 0 disk ├─sda1 8:1 0 243M 0 part /boot ├─sda2 8:2 0 1K 0 part └─sda5 8:5 0 19.8G 0 part └─debian10--vg-root 254:0 0 19.8G 0 lvm / sdb 8:16 0 10G 0 disk sdc 8:32 0 10G 0 disk
Инициализируем диски в качестве физического тома lvm.
# pvcreate /dev/sdb /dev/sdc Physical volume "/dev/sdb" successfully created. Physical volume "/dev/sdc" successfully created.
Теперь создадим группу томов, в которую будут входить оба диска.
# vgcreate vgbackup /dev/sdb /dev/sdc Volume group "vgbackup" successfully created
В данном случае vgbackup — название созданной группы. Теперь в этой группе томов мы можем создавать разделы. Они в чем-то похожи на разделы обычных дисков. Мы можем как создать один раздел на всю группу томов, так и нарезать эту группу на несколько разделов. Создадим один раздел на всем пространстве группы томов. Фактически, этот раздел будет занимать оба жестких диска, которые мы добавили.
# lvcreate -l100%FREE vgbackup -n lv_full
lv_full название логического раздела. Теперь с ним можно работать, как с обычным разделом. Создавать файловую систему и монтировать к серверу. Сделаем это.
# mkfs -t ext4 /dev/vgbackup/lv_full # mkdir /mnt/backup # mount /dev/vgbackup/lv_full /mnt/backup
Проверяем, что получилось.
# df -h | grep /mnt/backup /dev/mapper/vgbackup-lv_full 20G 45M 19G 1% /mnt/backup
Мы подключили lvm раздел, который расположен на двух жестких дисках. Повторю еще раз — обычные жесткие диски так не собирайте, используйте только raid тома для этого.
![Обозначения дисков и дисковых разделов в системах linux.
[avreg]](https://fuzeservers.ru/wp-content/uploads/0/1/6/016e3b772d4f3bf64387ac612d239cc3.png)




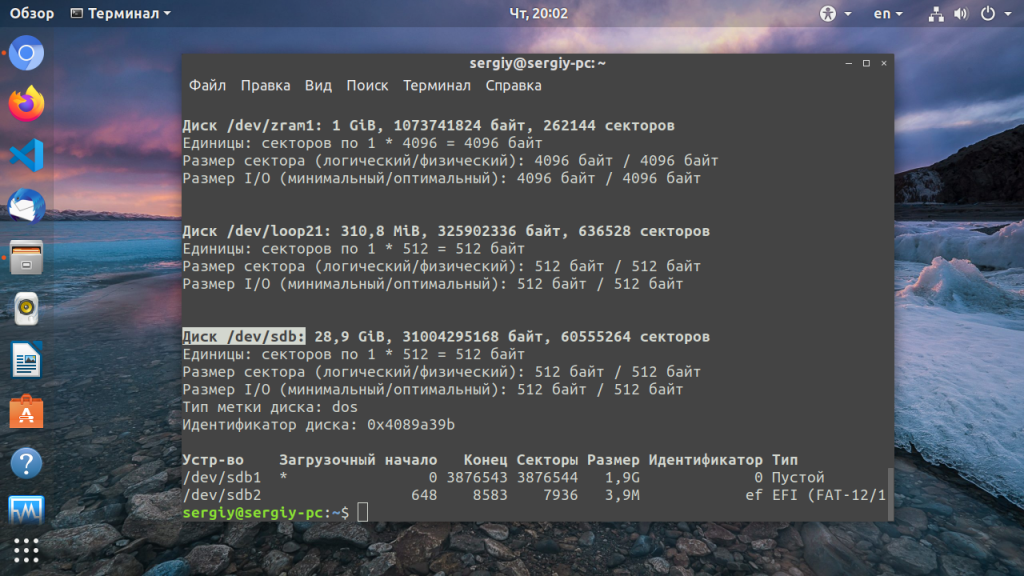
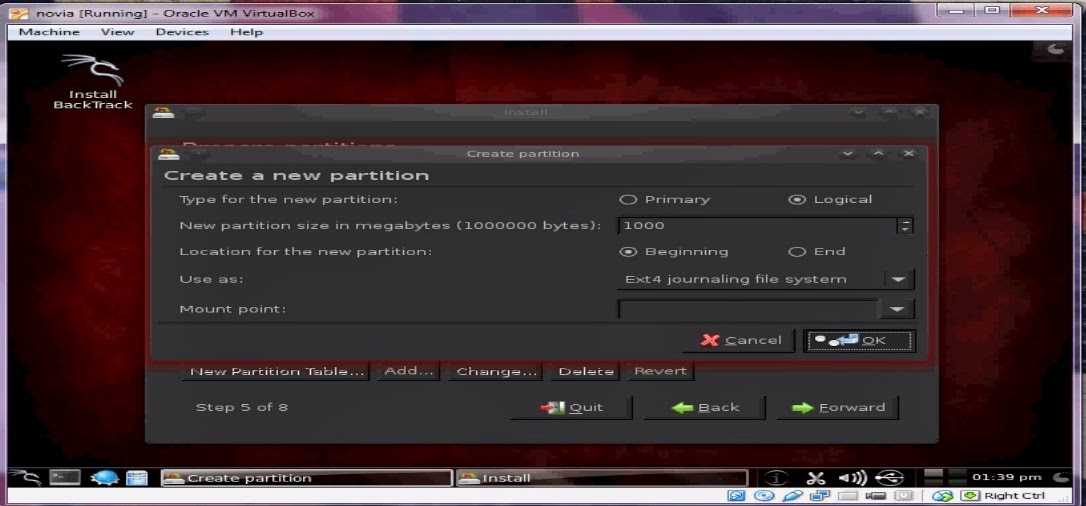
Теперь для примера давайте удалим этот раздел и создадим 2 новых, один на 14 Гб, другой на 5 Гб и так же их подключим к системе. Для начала удаляем раздел lv_full, предварительно отмонтировав его.
# umount /mnt/backup # lvremove /dev/vgbackup/lv_full
Проверяем, что раздела нет.
# lvs
![]()
Остался только один — системный. Создаем 2 новых раздела:
# lvcreate -L14G vgbackup -n lv01 # lvcreate -L4G vgbackup -n lv02 # lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root debian10-vg -wi-ao---- <19.76g lv01 vgbackup -wi-a----- 14.00g lv02 vgbackup -wi-a----- 4.00g
Дальше так же создаем файловые системы и монтируем новые разделы к серверу. Надеюсь, на конкретных примерах я сумел показать удобство и особенность работы с lvm томами и разделами. Дальше мы продолжим эту тему. При автомонтировании через fstab томов lvm можно использовать их имена вида /dev/mapper/vgbackup-lv_full, а не метки. Эти имена не меняются.
Вот наглядный пример, где можно использовать lvm тома размазанные на несколько дисков. Есть небольшой файловый сервер с 4-мя sata дисками по 4 tb. Нужно было сделать максимально объемное файловое хранилище. Были собраны 2 mdadm raid1. Немного объема ушло на служебные разделы, а потом все, что осталось объединили в единый lvm том и получили шару объемом 6.4 Tb.
![]()
Сразу могу сказать, что производительность такой штуки не очень высокая, но зато есть защита от отказа одного из дисков, плюс файловое хранилище нужного объема. Можно было сразу все собрать в raid10, но я сейчас уже не помню, почему от этого отказались. Были какие-то объективные причины, а привел эту ситуацию я просто для примера. Таким образом можно объединять различные разнородные массивы для увеличения суммарного объема одного раздела.
Сравнение полной виртуализации и паравиртуализации
Давайте начнем с краткого обсуждения двух различныхвидов схем виртуализации: полной виртуализации и паравиртуализации. В случае , гостевая операционная система работает поверх гипервизора, который установлен на голом аппаратном обеспечении. Гостевая система не знает, что она в данный момент виртуализирована, и в этой конфигурации не требуется никаких изменений в ее работе. Напротив, при , гостевая операционная система не только знает, что она запущена на гипервизоре, но и содержит код, который повышает эффективность взаимодействия гостевой системы и гипервизора (см. рис. 1)
При полной виртуализации гипервизор должен эмулировать аппаратное обеспечение устройства, что происходит на самом низком уровне обмена данными (например, для сетевого драйвера). Хотя благодаря абстракции понятно, как выполнять эмуляцию, она в большинстве случаев неэффективна и очень сложна. В случае паравиртуализации гостевая система и гипервизор могут работать совместно с целью сделать эту эмуляцию эффективной. Недостатком подхода с использованием паравиртуализации является то, что операционная система знает, что она виртуализирована и в ее работу требуется вносить изменения.
![]()
Рис.1: Эмуляция устройства в случае полной виртуализации и в случае паравиртуализации
Для того, чтобы поддерживать виртуализацию, продолжает совершенствоваться аппаратное обеспечение. В новые процессоры добавляются современные инструкции, которые повышают эффективность переключения между гостевыми операционными системами и гипервизором. Аппаратное обеспечение также продолжает совершенствоваться и для поддержки виртуализации ввода/вывода (I/O) (смотрите раздел Ресурсы в оригинале статьи, где изучается сквозной доступ к шине PCI и виртуализация ввода/вывода с одной или несколькими корневыми системами).
В традиционной среде полной виртуализации гипервизор должен отлавливать запросы ввода/вывода, а затем эмулировать поведение реального аппаратного обеспечения. Хотя в результате и обеспечивается максимальная гибкость (в частности, работа с немодифицированной операционной системой), такой подход приводит к неэффективности (см. левую часть рис.1). В правой части рис.1 показан вариант для случая паравиртуализации. Здесь гостевой операционной системы известно, что она работает на гипервизоре и в ней есть драйвера, которые работают как внешний интерфейс гипервизора (front-end драйвера) В гипервизоре реализованы внутренние драйвера (back-end драйвера), которые собственно и выполняют эмуляцию конкретного устройства. Эти front-end и back-end драйвера являются именно тем местом, куда встраивается фреймворк , обеспечивающий стандартизованный интерфейс для разработки доступа к эмулируемым устройствам, что ведет к повторному использованию кода и увеличивает эффективность.
Общая информация
Паравиртуализация — это популярный метод, имеющий сходство с полной виртуализацией. Гостевые ОС подготовливаются для исполнения в виртуализированной среде, для чего интегрируется код виртуализации в саму операционную систему. Этот подход позволяет избежать любой перекомпиляции или перехвата команд, поскольку операционная система сама участвует в процессе виртуализации. Цель изменения интерфейса — сокращение доли времени выполнения операций гостя, которые являются существенно более трудными для запуска в виртуальной среде. Подобно полной виртуализации множество различных операционных систем могут поддерживаться одновременно.
Паравиртуализацию используют SCSI, USB, VGA и PCI устройства.
Метод паравиртуализации позволяет добиться более высокой производительности чем метод динамической трансляции.
Паравиртуализация не требует расширения виртуализации от хост-процессора, и это обеспечивает виртуализацию аппаратных архитектур, которые не поддерживают аппаратную виртуализацию. Как бы то ни было, пользователи и управляющие домены требуют поддержки ядра и драйверов, которые в прошлом требовали специальной сборки ядра, но сейчас являются частью ядра Linux как и других ОС.
Монтирование файловой системы
Как правило, прежде чем использовать диск, его нужно разделить, отформатировать и смонтировать устройство или разделы. Разделение и форматирование обычно выполняется всего однажды, чего нельзя сказать о монтировании – как правило, эту процедуру нужно выполнять часто. Монтирование файловой системы позволяет получить к ней доступ на сервере в выбранной точке монтирования.
Точка монтирования – это просто каталог, в котором будет смонтирована файловая система.
Обычно для управления монтированием используются команды mount и umount. Команда mount прикрепляет файловую систему к текущему дереву файлов, а umount отсоединяет её.
Примечание: Не путайте эту команду с командой unmount.
Команда findmnt собирает информацию о текущем состоянии подключенных файловых систем.
Команда mount
Команде mount нужно передать отформатированное устройство или раздел и точку монтирования:
Точка монтирования (последний параметр) задаёт каталог, в котором будет смонтирована файловая система; как правило, такой каталог должен быть пуст.
Иногда для монтирования нужно указать более конкретные параметры. Команда mount может попытаться угадать тип файловой системы, однако лучше указать его самостоятельно. Для этого существует опция –t. Например, чтобы задать Ext4, нужно ввести:
Есть ещё много других опций, которые могут повлиять на монтирование. Существуют общие параметры монтирования, которые можно найти в разделе мануала FILESYSTEM INDEPENDENT MOUNT OPTIONS. Больше о файловых системах можно узнать в разделе FILESYSTEM SPECIFIC MOUNT OPTIONS. Чтобы открыть мануал, используйте:
Передайте другие параметры с помощью флага –о. Например, чтобы смонтировать раздел со стандартными параметрами (rw,suid,dev,exec,auto,nouser,async), можно использовать просто -o defaults. Чтобы изменить права доступа и оставить только право на чтение, в конце команды укажите опцию ro, которая переопределит rw параметра defaults:
Чтобы смонтировать все системы, указанные в файле /etc/fstab, передайте флаг –а.
Листинг опций монтирования файловых систем
Чтобы отобразить параметры монтирования, использованные для конкретного монтирования, используйте команду findmnt. Например:
Эта команда очень полезна, так как позволяет узнать все использованные ранее опции и параметры и определить набор наиболее полезных опций для каждого конкретного случая монтирования. Затем эти опции можно добавить в файл /etc/fstab.
Демонтирование файловой системы
Команда umount позволяет демонтировать файловую систему.
Команде нужно передать точку монтирования или устройство смонтированной в настоящее время файловой системы. Убедитесь, что вы не используете какие-либо смонтированные файлы, и что в точке монтирования нет запущенных приложений.
У этой команды есть дополнительные опции, но они очень редко используются.
Расширение диска
Теперь представим ситуацию, что у вас используется какой-то lvm раздел и вы хотите его увеличить. В общем случае я не рекомендую это делать без особой нужды. Увеличивать можно даже системный диск с / , но на практике я получал неожиданные проблемы от такого расширения. Пример такой проблемы — Booting from Hard Disk error, Entering rescue mode. В общем случае все должно расширяться без проблем, но когда я разбирался с ошибкой, я находил в интернете информацию о том, что люди сталкивались с тем же самым именно после расширения системного lvm раздела.
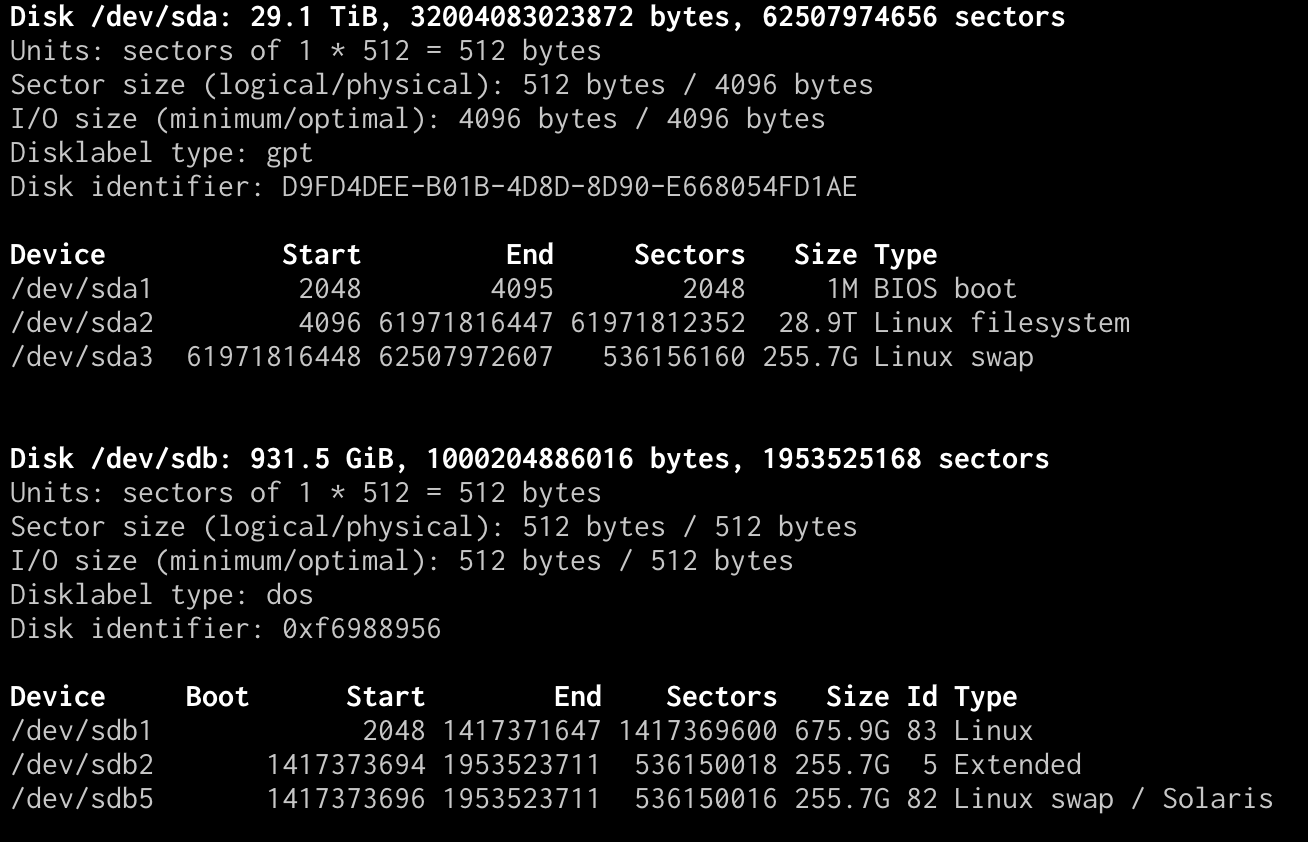

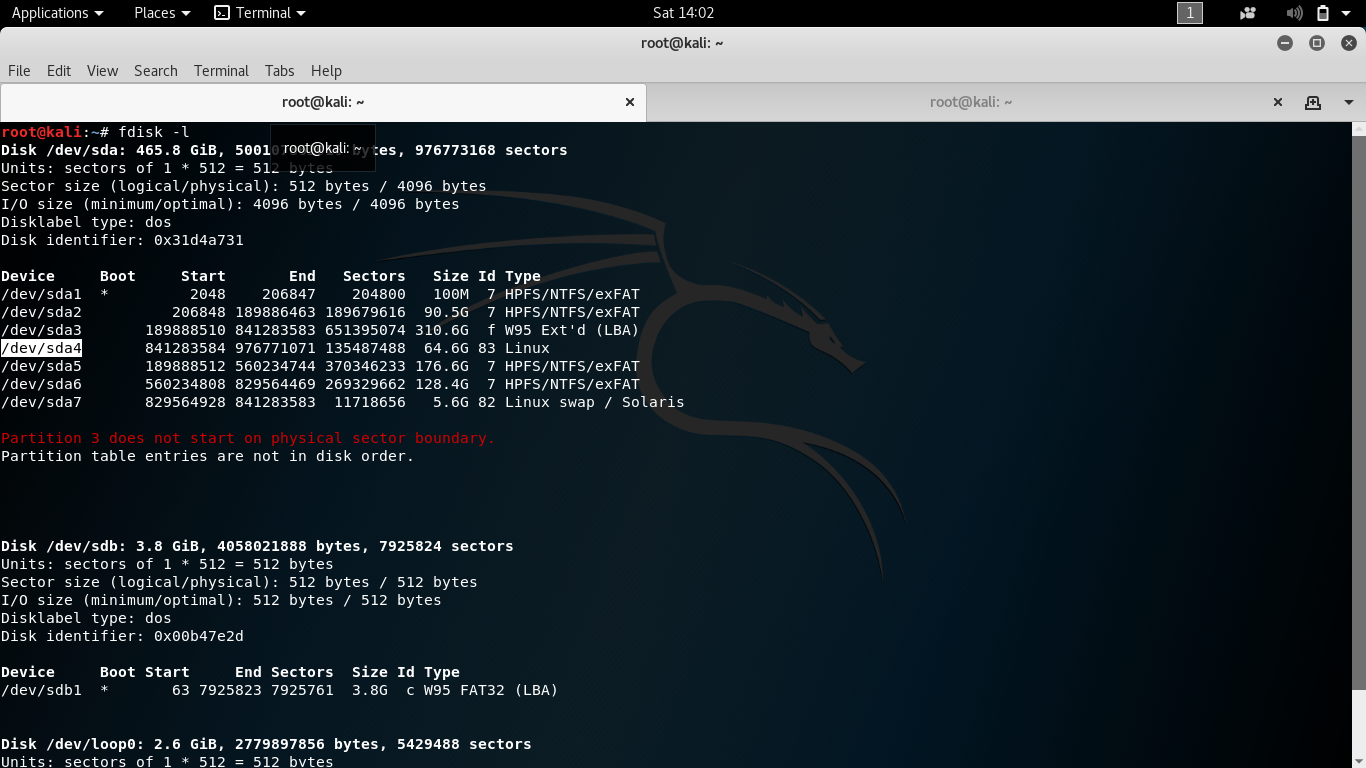
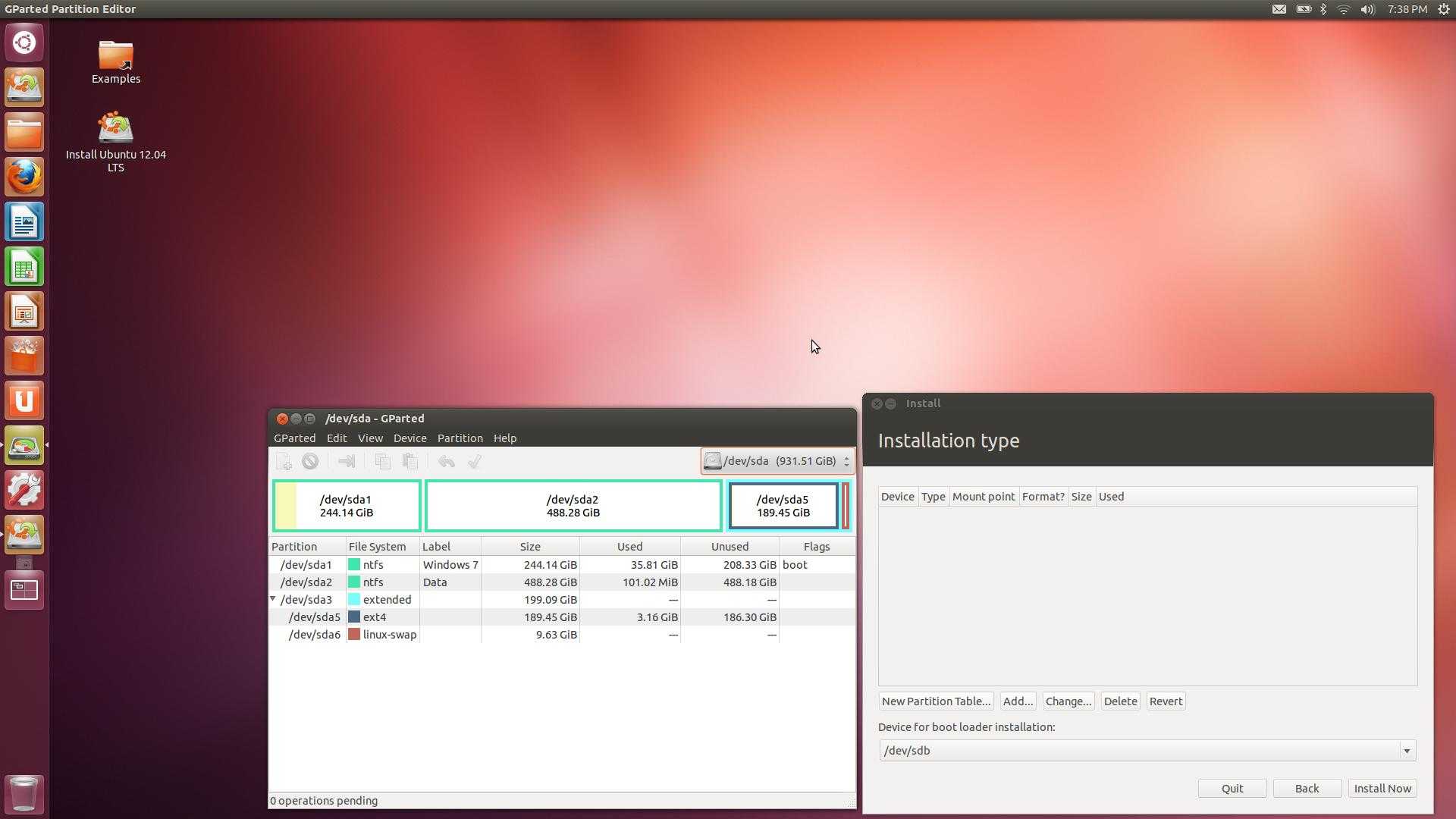
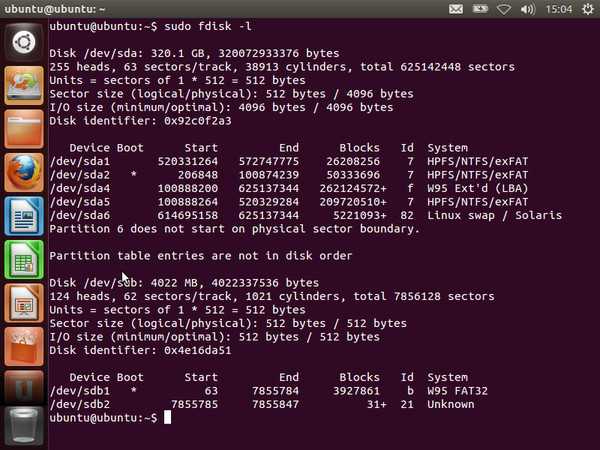



Если раздел не системный, то проблем быть не должно. Последовательность действий следующая при расширении lvm раздела:
- Добавляем новый диск в систему.
- Подключаем диск к группе томов, на которой находится раздел, который будем увеличивать.
- Расширяем lvm раздел за счет свободного места, которое образовалось в группе томов за счет добавления нового диска.
Теперь по пунктам проделаем все это. У нас имеется группа томов из 2-х дисков — sdb и sdc. На этой группе размещен один раздел, который занимает все свободное пространство. Мы его расширим за счет нового диска.
Смотрим, что у нас есть.
Увеличим раздел lv_full до 30 Гб за счет добавления в группу томов нового диска на 10 Гб. Имя этого диска — sdd. Добавим его в существующую группу томов.
# vgextend vgbackup /dev/sdd Physical volume "/dev/sdd" successfully created. Volume group "vgbackup" successfully extended
Смотрим информацию по томам.
# pvs PV VG Fmt Attr PSize PFree /dev/sda5 debian10-vg lvm2 a-- <19.76g 0 /dev/sdb vgbackup lvm2 a-- <10.00g 0 /dev/sdc vgbackup lvm2 a-- <10.00g 0 /dev/sdd vgbackup lvm2 a-- <10.00g <10.00g
Новый диск добавлен в группу и он пока пуст. Расширяем существующий раздел на 100% свободного места группы томов.
# lvextend -r -l +100%FREE /dev/vgbackup/lv_full
Раздел увеличен. Я его не отключал в процессе расширения. Все сделано, как говорится, на горячую. С lvm это очень просто и я наглядно рассказал, как это сделать. А теперь давайте расширим обычный раздел диска, не lvm. Это тоже реально и не сильно сложнее.
Допустим, у нас есть диск /dev/sdb размером 10 Гб, на нем один раздел sdb1, который занимает все свободное пространство диска. Это диск виртуальной машины, который мы можем увеличить через управление дисками гипервизора. Я расширил диск до 20 Гб. Смотрим, что получилось.
# fdisk -l | grep /dev/sdb GPT PMBR size mismatch (20971519 != 41943039) will be corrected by write. The backup GPT table is not on the end of the device. This problem will be corrected by write. Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors /dev/sdb1 2048 20971486 20969439 10G Linux filesystem Partition 2 does not start on physical sector boundary.
У нас объем диска 20 Гб, на нем только один раздел на 10 Гб. Нам его надо расширить до 20-ти Гб. Диск нужно отмонтировать, прежде чем продолжать.
# umount /dev/sdb1
Открываем диск в fdisk и выполняем там следующую последовательность действий:
- Удаляем существующий раздел sdb1 на 10G.
- Вместо него создаем новый sdb1 на 20G.
- Записываем изменения.
# fdisk /dev/sdb
Проверяем, что получилось:
# fdisk -l | grep /dev/sdb Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors /dev/sdb1 2048 41943006 41940959 20G Linux filesystem
Монтируем раздел обратно в систему и проверяем размер.
# mount /dev/sdb1 /mnt/backup # df -h | grep sdb1 /dev/sdb1 9.8G 37M 9.3G 1% /mnt/backup
Размер файловой системы на разделе не изменился. Расширяем ее отдельной командой.
# resize2fs /dev/sdb1 resize2fs 1.44.5 (15-Dec-2018) Filesystem at /dev/sdb1 is mounted on /mnt/backup; on-line resizing required old_desc_blocks = 2, new_desc_blocks = 3 The filesystem on /dev/sdb1 is now 5242619 (4k) blocks long.
Проверяем, что получилось.
# df -h | grep sdb1 /dev/sdb1 20G 44M 19G 1% /mnt/backup
Раздел ext4 расширился до желаемых 20 Гб. Я не пробовал расширять системный раздел ext4 без размонтирования, не было необходимости. Но если у вас системный раздел на xfs, то вот пример того, как его можно расширить без отмонтирования и без остановки сервера — Расширение (увеличение) xfs корневого раздела / без остановки.





