
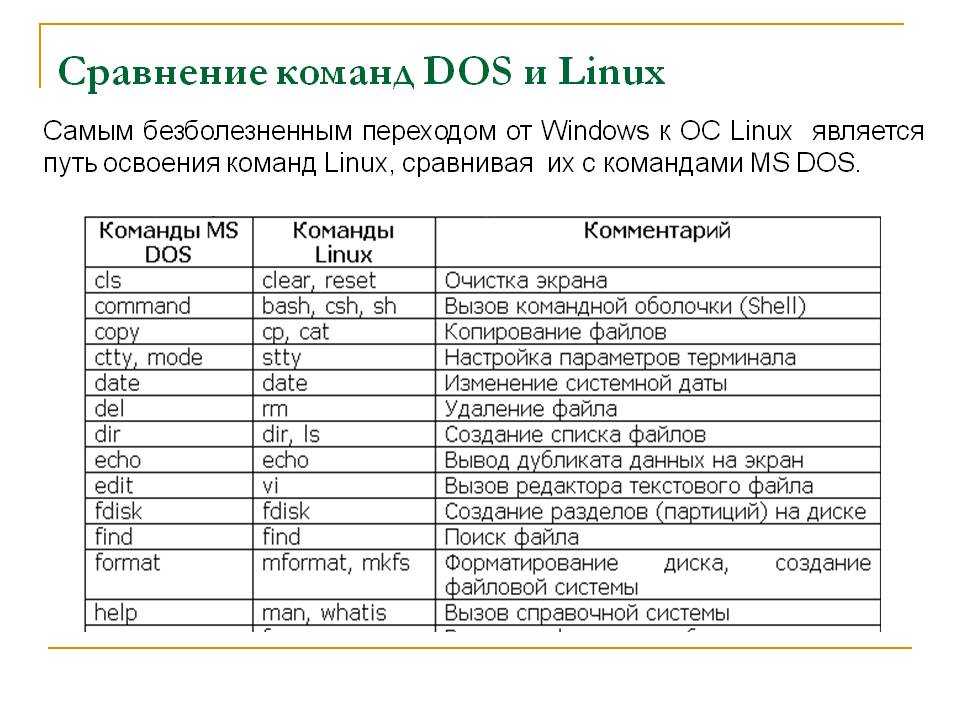
Образцы
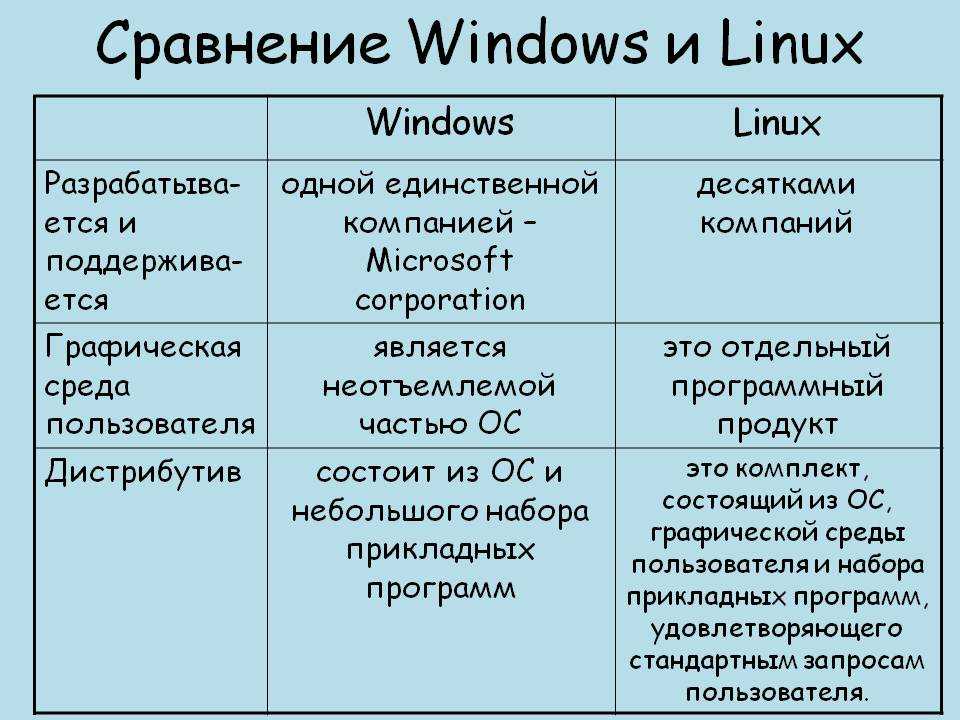
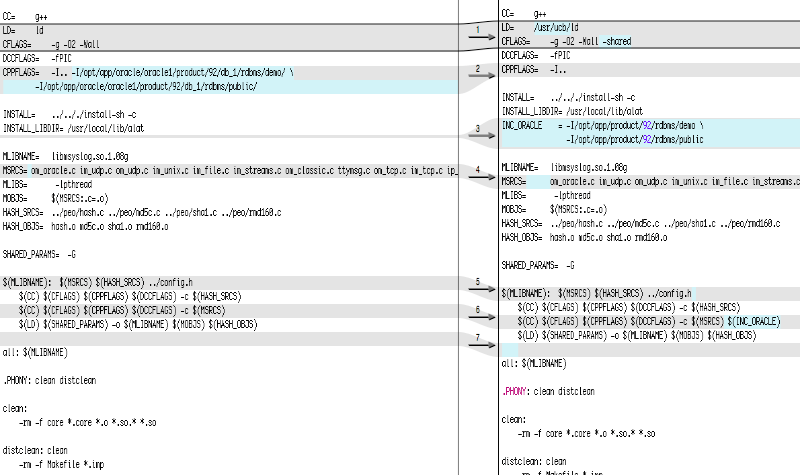
0123456789ABCDEF /* ********************************************** */ Table with TABs (09) 1 2 3 3.14 6.28 9.42
как показано Unix :
0000000 30 31 32 33 34 35 36 37 38 39 41 42 43 44 45 46 0000010 0a 2f 2a 20 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 0000020 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a * 0000040 2a 2a 20 2a 2f 0a 09 54 61 62 6c 65 20 77 69 74 0000050 68 20 54 41 42 73 20 28 30 39 29 0a 09 31 09 09 0000060 32 09 09 33 0a 09 33 2e 31 34 09 36 2e 32 38 09 0000070 39 2e 34 32 0a 0000075
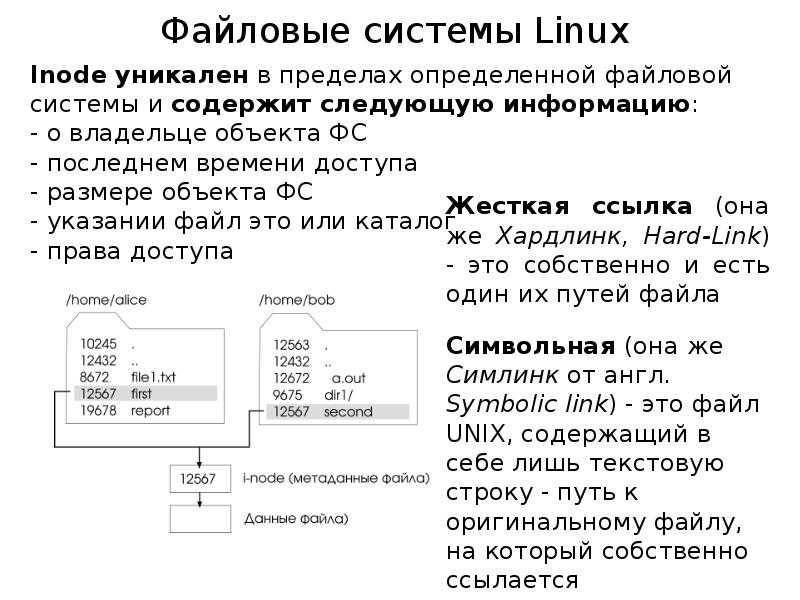
Самый левый столбец — это шестнадцатеричное смещение (или адрес) для значений следующих столбцов. Каждая строка отображает 16 байтов, за исключением строки, содержащей один *. Знак * используется для обозначения того, что несколько экземпляров одного и того же дисплея были пропущены. В последней строке отображается количество байтов, взятых из ввода.
В дополнительном столбце отображается соответствующий перевод символов ASCII с помощью или :
00000000 30 31 32 33 34 35 36 37 38 39 41 42 43 44 45 46 |0123456789ABCDEF| 00000010 0a 2f 2a 20 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |./* ************| 00000020 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |****************| * 00000040 2a 2a 20 2a 2f 0a 09 54 61 62 6c 65 20 77 69 74 |** */..Table wit| 00000050 68 20 54 41 42 73 20 28 30 39 29 0a 09 31 09 09 |h TABs (09)..1..| 00000060 32 09 09 33 0a 09 33 2e 31 34 09 36 2e 32 38 09 |2..3..3.14.6.28.| 00000070 39 2e 34 32 0a |9.42.| 00000075
Это полезно при попытке найти символы TAB в файле, который, как ожидается, будет содержать несколько пробелов.
Эта опция заставляет hexdump отображать все данные подробно:
00000000 30 31 32 33 34 35 36 37 38 39 41 42 43 44 45 46 |0123456789ABCDEF| 00000010 0a 2f 2a 20 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |./* ************| 00000020 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |****************| 00000030 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a 2a |****************| 00000040 2a 2a 20 2a 2f 0a 09 54 61 62 6c 65 20 77 69 74 |** */..Table wit| 00000050 68 20 54 41 42 73 20 28 30 39 29 0a 09 31 09 09 |h TABs (09)..1..| 00000060 32 09 09 33 0a 09 33 2e 31 34 09 36 2e 32 38 09 |2..3..3.14.6.28.| 00000070 39 2e 34 32 0a |9.42.| 00000075
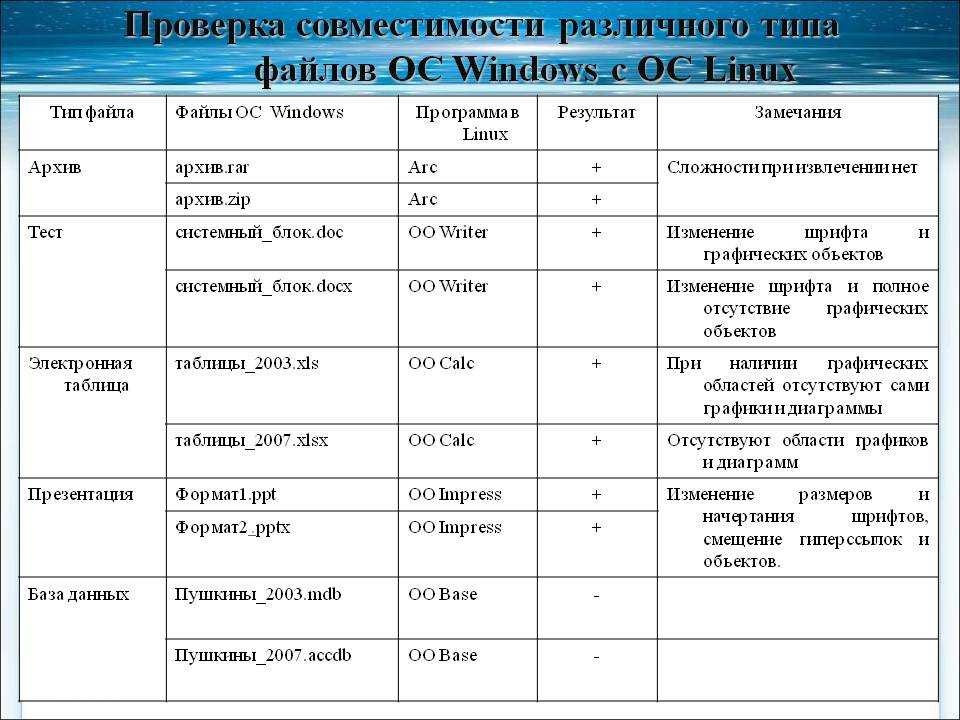
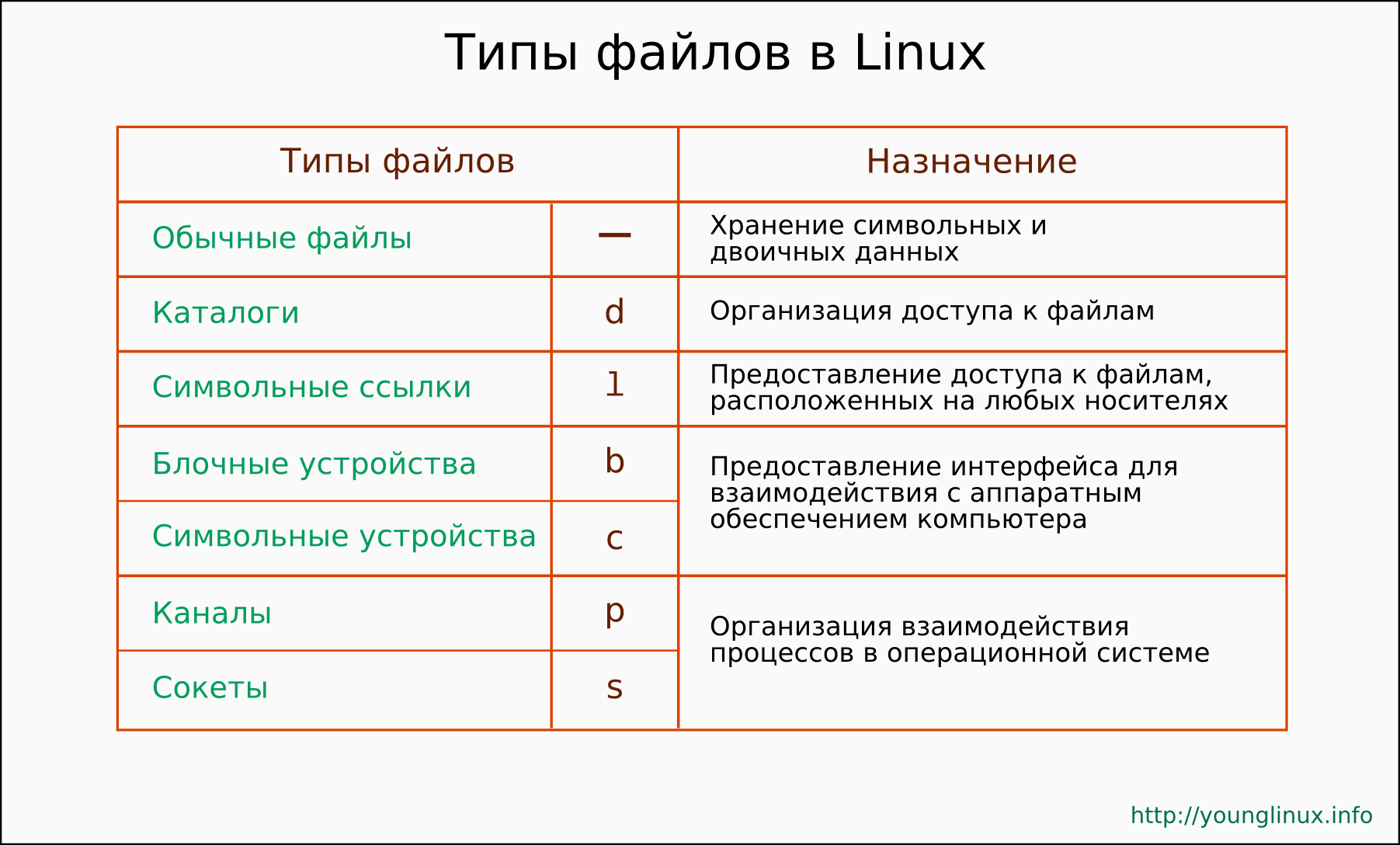
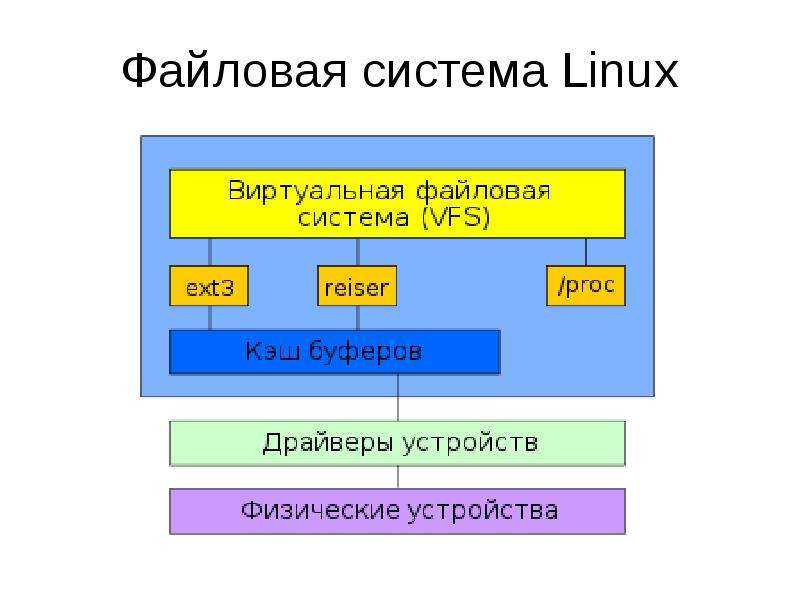
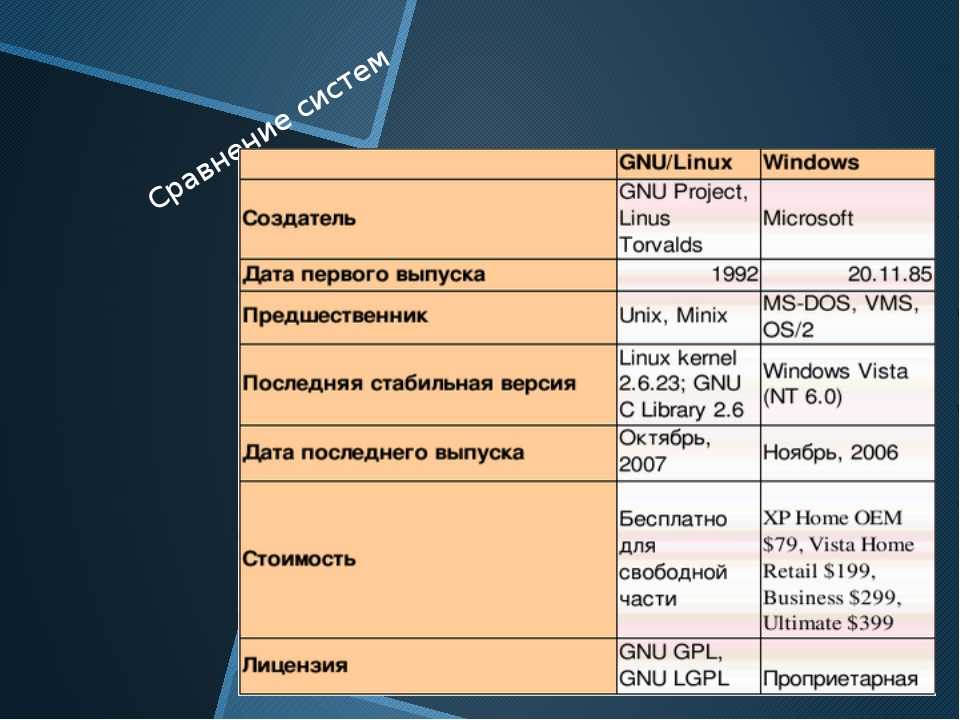
Бинарные файлы
Текстовые файлы хранят данные в виде текста (sic!). Это значит, что если, например, мы записываем целое число 12345678 в файл, то
записывается 8 символов, а это 8 байт данных, несмотря на то, что число помещается в целый тип. Кроме того, вывод и ввод данных является форматированным, то
есть каждый раз, когда мы считываем число из файла или записываем в файл происходит трансформация числа в строку или обратно. Это затратные операции, которых можно избежать.
Текстовые файлы позволяют хранить информацию в виде, понятном для человека. Можно, однако, хранить данные непосредственно в бинарном виде. Для этих целей используются
бинарные файлы.
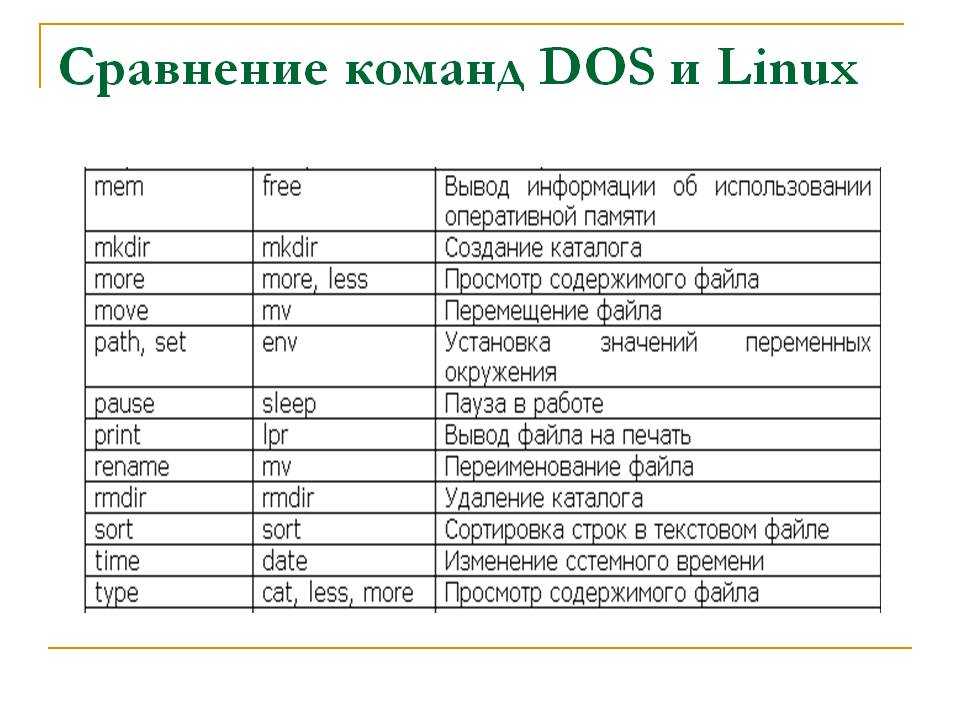
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
#define ERROR_FILE_OPEN -3
void main() {
FILE *output = NULL;
int number;
output = fopen("D:/c/output.bin", "wb");
if (output == NULL) {
printf("Error opening file");
getch();
exit(ERROR_FILE_OPEN);
}
scanf("%d", &number);
fwrite(&number, sizeof(int), 1, output);
fclose(output);
_getch();
}
Выполните программу и посмотрите содержимое файла output.bin. Число, которое ввёл пользователь записывается в файл непосредственно в бинарном виде. Можете
открыть файл в любом редакторе, поддерживающем представление в шестнадцатеричном виде (Total Commander, Far) и убедиться в этом.
Запись в файл осуществляется с помощью функции
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
Функция возвращает число удачно записанных элементов. В качестве аргументов принимает указатель на массив, размер одного элемента, число элементов и указатель на файловый поток.
Вместо массив, конечно, может быть передан любой объект.
Запись в бинарный файл объекта похожа на его отображение: берутся данные из оперативной памяти и пишутся как есть. Для считывания используется функция fread
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
Функция возвращает число удачно прочитанных элементов, которые помещаются по адресу ptr. Всего считывается count элементов по size байт. Давайте теперь считаем наше число
обратно в переменную.
#include <conio.h>
#include <stdio.h>
#include <stdlib.h>
#define ERROR_FILE_OPEN -3
void main() {
FILE *input = NULL;
int number;
input = fopen("D:/c/output.bin", "rb");
if (input == NULL) {
printf("Error opening file");
getch();
exit(ERROR_FILE_OPEN);
}
fread(&number, sizeof(int), 1, input);
printf("%d", number);
fclose(input);
_getch();
}
Хакерский редактор Hacker Viewer (Hiew) .
Для визуального восприятия шестнадцатеричного кода воспользуемся замечательным простым, но достаточно функциональным DOS редактором Hacker Viewer (Hiew). Вы найдёте его в папке D:\UTILS\HIEW\ (я надеюсь, что наш архив программ DOS-1.rar уже скачан и DOSBox установлен и запущен).
![]() Запускаем HIEW (Hacker Viewer).
Запускаем HIEW (Hacker Viewer).
Инструкцию по пользованию Hiew для хакеров от Криса Касперского вы найдёте в папочке readme. Пользоваться редактором просто и удобно.
Откроем с помощью Hiew нашу программу PRG.COM (выбор файлов — F9). При помощи F4 выбираем режим отображения информации HEX (как вы уже знаете, шестнадцатеричный режим). Можете с помощью F4 или Enter по переключаться между режимами отображения.
![]() Переключение режимов отображения в Hacker Viewer.
Переключение режимов отображения в Hacker Viewer.
Обратите внимание на положение Decode (декодирование). Вам это ни о чём не говорит? Да, да, да в Hiew имеется встроенный дизассемблер и даже ассемблер! Можно внести изменения в ассемблерный код, не выходя из редактора и сохранить изменения.
Исполняемый файл останется рабочим — гениальная программа с поразительными возможностями для своего времени!. Подобное отображение HEX системы счисления вы увидите практически во всех отладочных программах и просмотрщиках файлов.
Перемещайте курсор с помощью клавиш стрелок на клавиатуре
Вверху вы заметите изменение цифры указателя (pointer)
Подобное отображение HEX системы счисления вы увидите практически во всех отладочных программах и просмотрщиках файлов.
Перемещайте курсор с помощью клавиш стрелок на клавиатуре. Вверху вы заметите изменение цифры указателя (pointer).
![]() Наша первая программа в шестнадцатеричном виде.
Наша первая программа в шестнадцатеричном виде.
Указатель является одним из основополагающих понятий в системе программирования. Основы понимания работы с указателем рассмотрим попозже.
Шестнадцатеричная система счисления.
В шестнадцатеричной системе счисления одним символом отображаются числа от нуля до шестнадцати. Чтобы не сочинять новых отображений цифр,
решили использовать буквы латинского алфавита: A, B, C, D, E, F.
Для большей понятности — внизу приведена таблица соответствия цифр трём системам счисления.
DEC BIN HEX
Десятичная Двоичная Шестнадцатиричная
0 0 0
1 1 1
2 10 2
3 11 3
4 100 4
5 101 5
6 110 6
7 111 7
8 1000 8
9 1001 9
10 1010 A
11 1011 B
12 1100 C
13 1101 D
14 1110 E
15 1111 F
16 10000 10
17 10001 11
18 10010 12
….
|
1 |
DECBINHEX ДесятичнаяДвоичнаяШестнадцатиричная 111 2102 3113 41004 51015 61106 71117 810008 910019 101010A 111011B 121100C 131101D 141110E 151111F 161000010 171000111 181001012 …. |
Запоминать соответствия цифр нет необходимости. В состав Windows любой версии входит программа «калькулятор» — calc.exe. Запустите её, переключитесь в программистский вид (Вид->Программист или Alt+3) и да пребудет с вами сила!
![]() Калькулятор программиста: HEX, DEC, OCT, BIN.
Калькулятор программиста: HEX, DEC, OCT, BIN.
Модификаторы точности
Модификатор точности следует за модификатором минимальной ширины поля (если таковой имеется). Он состоит из точки и расположенного за ней целого числа. Значение этого модификатора зависит от типа данных, к которым его применяют.
Когда модификатор точности применяется к данным с плавающей точкой, для преобразования которых используются спецификаторы преобразования %f, %e или %E, то он определяет количество выводимых десятичных разрядов. Например, %10.4f означает, что ширина поля вывода будет не менее 10 символов, причем для десятичных разрядов будет отведено четыре позиции.
Если модификатор точности применяется к %g или %G, то он определяет количество значащих цифр.
Примененный к строкам, модификатор точности определяет максимальную длину поля. Например, %5.7s означает, что длина выводимой строки будет составлять минимум пять и максимум семь символов. Если строка окажется длиннее, чем максимальная длина поля, то конечные символы выводиться не будут.
Если модификатор точности применяется к целым типам, то он определяет минимальное количество цифр, которые будут выведены для каждого из чисел. Чтобы получилось требуемое количество цифр, добавляется некоторое количество ведущих нулей.
В следующей программе показано, как можно использовать модификатор точности:
#include <stdio.h>
int main(void)
{
printf("%.4f\n", 123.1234567);
printf("%3.8d\n", 1000);
printf("%10.15s\n", "Это простая проверка.");
return 0;
}
Вот что выводится при выполнении этой программы:
123.1235 00001000 Это простая про
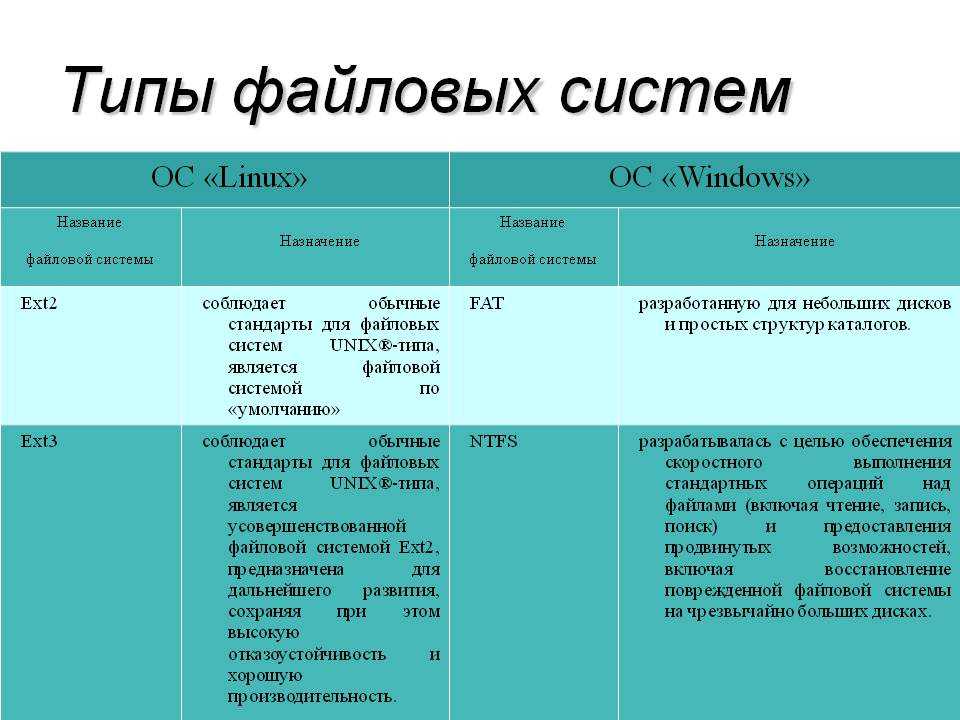
Файловая структура FAT32
Устройства внешней памяти в системе FAT32 имеют не байтовую, а блочную адресацию. Запись информации в устройство внешней памяти осуществляется блоками или секторами. Сектор – минимальная адресуемая единица хранения информации на внешних запоминающих устройствах. Как правило, размер сектора фиксирован и составляет 512 байт. Для увеличения адресного пространства устройств внешней памяти сектора объединяют в группы, называемые кластерами. Кластер – объединение нескольких секторов, которое может рассматриваться как самостоятельная единица, обладающая определёнными свойствами. Основным свойством кластера является его размер, измеряемый в количестве секторов или количестве байт.
Файловая система FAT32 имеет следующую структуру.![]()
Нумерация кластеров, используемых для записи файлов, ведется с 2. Как правило, кластер №2 используется корневым каталогом, а начиная с кластера №3 хранится массив данных. Сектора, используемые для хранения информации, представленной выше корневого каталога, в кластеры не объединяются.
Минимальный размер файла, занимаемый на диске, соответствует 1 кластеру.
Загрузочный сектор начинается следующей информацией:
- EB 58 90 – безусловный переход и сигнатура;
- 4D 53 44 4F 53 35 2E 30 MSDOS5.0;
- 00 02 – количество байт в секторе (обычно 512);
- 1 байт – количество секторов в кластере;
- 2 байта – количество резервных секторов.
Кроме того, загрузочный сектор содержит следующую важную информацию:
- 0x10 (1 байт) – количество таблиц FAT (обычно 2);
- 0x20 (4 байта) – количество секторов на диске;
- 0x2С (4 байта) – номер кластера корневого каталога;
- 0x47 (11 байт) – метка тома;
- 0x1FE (2 байта) – сигнатура загрузочного сектора (55 AA).
Сектор информации файловой системы содержит:
- 0x00 (4 байта) – сигнатура (52 52 61 41);
- 0x1E4 (4 байта) – сигнатура (72 72 41 61);
- 0x1E8 (4 байта) – количество свободных кластеров, -1 если не известно;
- 0x1EС (4 байта) – номер последнего записанного кластера;
- 0x1FE (2 байта) – сигнатура (55 AA).
Таблица FAT содержит информацию о состоянии каждого кластера на диске. Младшие 2 байт таблицы FAT хранят F8 FF FF 0F FF FF FF FF (что соответствует состоянию кластеров 0 и 1, физически отсутствующих). Далее состояние каждого кластера содержит номер кластера, в котором продолжается текущий файл или следующую информацию:





- 00 00 00 00 – кластер свободен;
- FF FF FF 0F – конец текущего файла.
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
- 8 байт – имя файла;
- 3 байта – расширение файла;
Корневой каталог содержит набор 32-битных записей информации о каждом файле, содержащих следующую информацию:
- 8 байт – имя файла;
- 3 байта – расширение файла;
- 1 байт – атрибут файла:
- 1 байт – зарезервирован;
- 1 байт – время создания (миллисекунды) (число от 0 до 199);
- 2 байта – время создания (с точностью до 2с):
- 2 байта – дата создания:
- 2 байта – дата последнего доступа;
- 2 байта – старшие 2 байта начального кластера;
- 2 байта – время последней модификации;
- 2 байта – дата последней модификации;
- 2 байта – младшие 2 байта начального кластера;
- 4 байта – размер файла (в байтах).
В случае работы с длинными именами файлов (включая русские имена) кодировка имени файла производится в системе кодировки UTF-16. При этого для кодирования каждого символа отводится 2 байта. При этом имя файла записывается в виде следующей структуры:
- 1 байт последовательности;
- 10 байт содержат младшие 5 символов имени файла;
- 1 байт атрибут;
- 1 байт резервный;
- 1 байт – контрольная сумма имени DOS;
- 12 байт содержат младшие 3 символа имени файла;
- 2 байта – номер первого кластера;
- остальные символы длинного имени.
Далее следует запись, включающая имя файла в формате 8.3 в обычном формате.
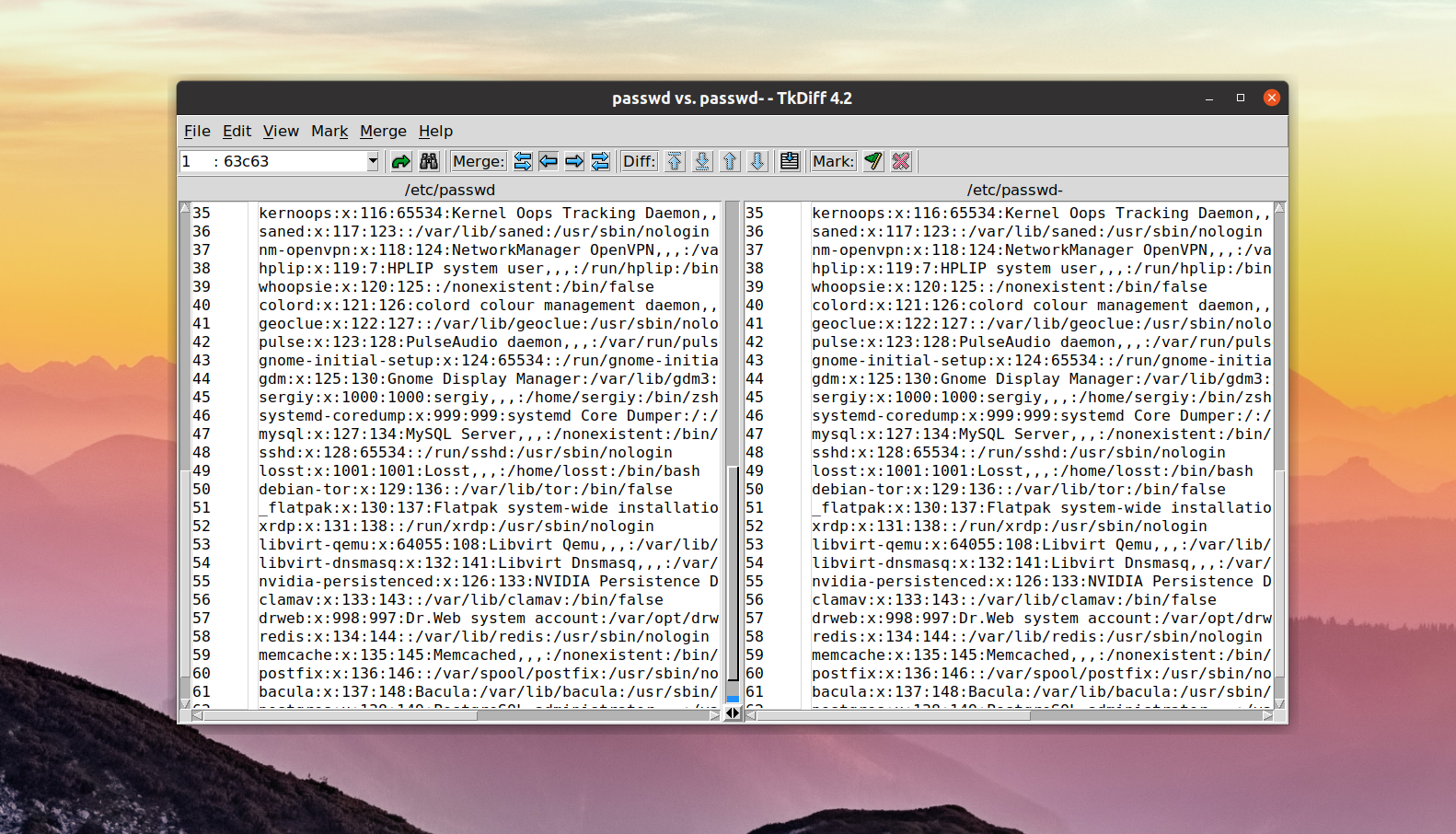
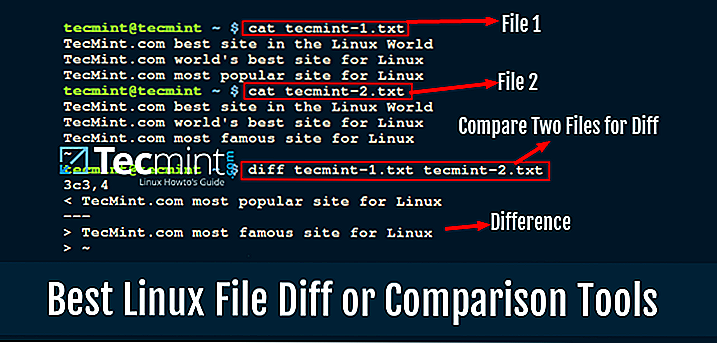
Сравнение файлов diff
Утилита diff linux — это программа, которая работает в консольном режиме. Ее синтаксис очень прост. Вызовите утилиту, передайте нужные файлы, а также задайте опции, если это необходимо:
$ diff опции файл1 файл2
Можно передать больше двух файлов, если это нужно. Перед тем как перейти к примерам, давайте рассмотрим опции утилиты:
- -q — выводить только отличия файлов;
- -s — выводить только совпадающие части;
- -с — выводить нужное количество строк после совпадений;
- -u — выводить только нужное количество строк после отличий;
- -y — выводить в две колонки;
- -e — вывод в формате ed скрипта;
- -n — вывод в формате RCS;
- -a — сравнивать файлы как текстовые, даже если они не текстовые;
- -t — заменить табуляции на пробелы в выводе;
- -l — разделить на страницы и добавить поддержку листания;
- -r — рекурсивное сравнение папок;
- -i — игнорировать регистр;
- -E — игнорировать изменения в табуляциях;
- -Z — не учитывать пробелы в конце строки;
- -b — не учитывать пробелы;
- -B — не учитывать пустые строки.
Это были основные опции утилиты, теперь давайте рассмотрим как сравнить файлы Linux. В выводе утилиты кроме, непосредственно, отображения изменений, выводит строку в которой указывается в какой строчке и что было сделано. Для этого используются такие символы:
- a — добавлена;
- d — удалена;
- c — изменена.
К тому же, линии, которые отличаются, будут обозначаться символом <, а те, которые совпадают — символом >.
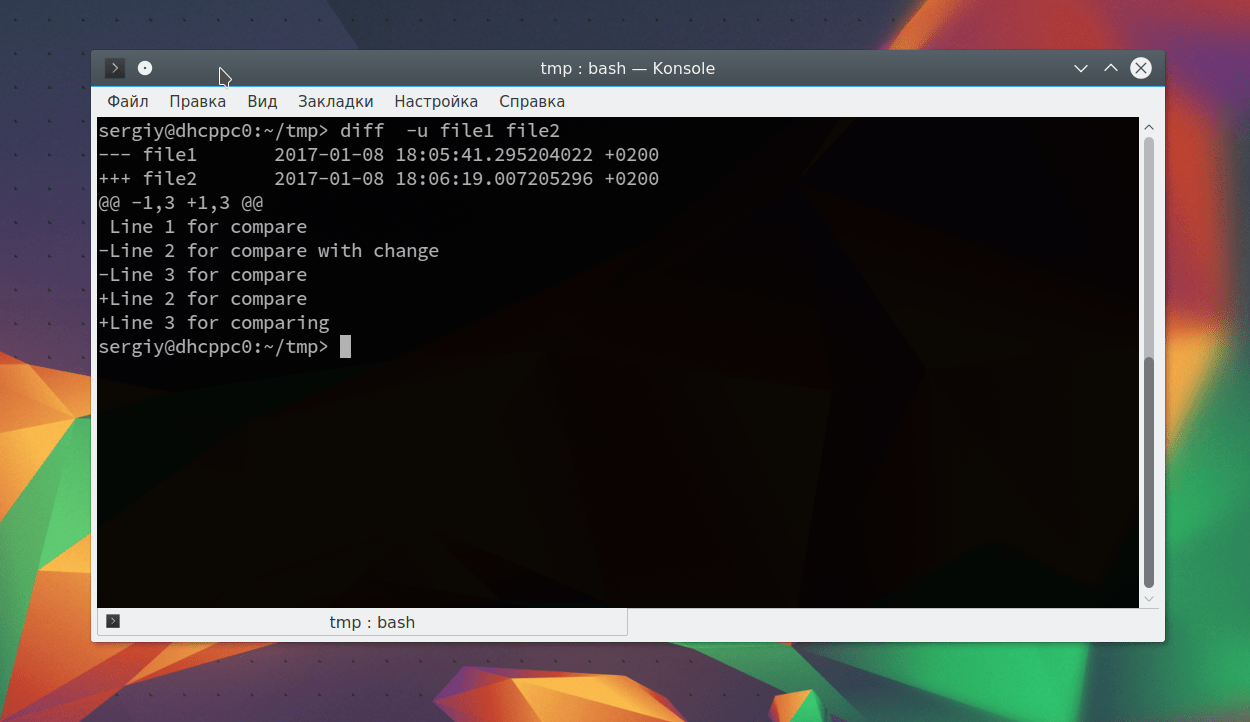
Вот содержимое наших тестовых файлов:
Теперь давайте выполним сравнение файлов diff:
В результате мы получим строчку: 2,3c2,4. Она означает, что строки 2 и 3 были изменены. Вы можете использовать опции для игнорирования регистра:
Можно сделать вывод в две колонки:
А с помощью опции -u вы можете создать патч, который потом может быть наложен на такой же файл другим пользователем:
Чтобы обработать несколько файлов в папке удобно использовать опцию -r:
Для удобства, вы можете перенаправить вывод утилиты сразу в файл:
Как видите, все очень просто. Но не очень удобно. Более приятно использовать графические инструменты.
Куда пойти отсюда?
Достаточно теории, давайте познакомимся!
Чтобы стать успешным в кодировке, вам нужно выйти туда и решать реальные проблемы для реальных людей. Вот как вы можете легко стать шестифункциональным тренером. И вот как вы польские навыки, которые вам действительно нужны на практике. В конце концов, что такое использование теории обучения, что никто никогда не нуждается?
Практические проекты – это то, как вы обостряете вашу пилу в кодировке!
Вы хотите стать мастером кода, сосредоточившись на практических кодовых проектах, которые фактически зарабатывают вам деньги и решают проблемы для людей?
Затем станьте питоном независимым разработчиком! Это лучший способ приближения к задаче улучшения ваших навыков Python – даже если вы являетесь полным новичком.
Присоединяйтесь к моему бесплатным вебинаре «Как создать свой навык высокого дохода Python» и посмотреть, как я вырос на моем кодированном бизнесе в Интернете и как вы можете, слишком от комфорта вашего собственного дома.
Присоединяйтесь к свободному вебинару сейчас!
Работая в качестве исследователя в распределенных системах, доктор Кристиан Майер нашел свою любовь к учению студентов компьютерных наук.
Чтобы помочь студентам достичь более высоких уровней успеха Python, он основал сайт программирования образования Finxter.com Отказ Он автор популярной книги программирования Python One-listers (Nostarch 2020), Coauthor of Кофе-брейк Python Серия самооставленных книг, энтузиаста компьютерных наук, Фрилансера и владелец одного из лучших 10 крупнейших Питон блоги по всему миру.
Его страсти пишут, чтение и кодирование. Но его величайшая страсть состоит в том, чтобы служить стремлению кодер через Finxter и помогать им повысить свои навыки. Вы можете присоединиться к его бесплатной академии электронной почты здесь.
Заголовок ELF
Мы можем изучить и расшифровать заголовок ELF с использованием утилита и (заголовок файла) опция:
readelf -h hello
![]()
Заголовок интерпретируется для нас.
![]()
Первый байт всех двоичных файлов ELF установлен в шестнадцатеричное значение 0x7F. Следующие три байта установлены в 0x45, 0x4C и 0x46. Первый байт — это флаг, который идентифицирует файл как двоичный файл ELF. Чтобы сделать этот кристалл прозрачным, следующие три байта обозначают «ELF» в ASCII:
- Учебный класс: Указывает, является ли двоичный файл 32- или 64-разрядным исполняемым файлом (1 = 32, 2 = 64).
- Данные: Указывает на порядок байт в использовании. Кодировка Endian определяет способ хранения многобайтовых чисел. В кодировании с прямым порядком байтов число сохраняется первым с его старшими значащими битами. При кодировании с прямым порядком байтов число сохраняется первым с его младшими значащими битами.
- Версия: Версия ELF (в настоящее время это 1).
- OS / ABI: Представляет тип двоичный интерфейс приложения в использовании. Это определяет интерфейс между двумя двоичными модулями, такими как программа и разделяемая библиотека.
- Версия ABI: Версия ABI.
- Тип: Тип двоичного файла ELF. Общие значения для перемещаемого ресурса (такого как объектный файл), для исполняемого файла, скомпилированного с флаг и для исполняемого файла с поддержкой ASMR.
- Машина: архитектура набора команд, Это указывает целевую платформу, для которой был создан двоичный файл.
- Версия: Всегда установлен на 1, для этой версии ELF.
- Адрес пункта въезда: Адрес памяти в двоичном файле, с которого начинается выполнение.
Другие записи — это размеры и количество областей и разделов в двоичном файле, чтобы можно было рассчитать их местоположение.
Быстрый взгляд на первые восемь байтов двоичного файла с покажет сигнатурный байт и строку «ELF» в первых четырех байтах файла. (каноническая) опция дает нам представление ASCII байтов вместе с их шестнадцатеричными значениями, и Параметр (число) позволяет нам указать, сколько байтов мы хотим видеть:
hexdump -C -n 8 hello
![]()
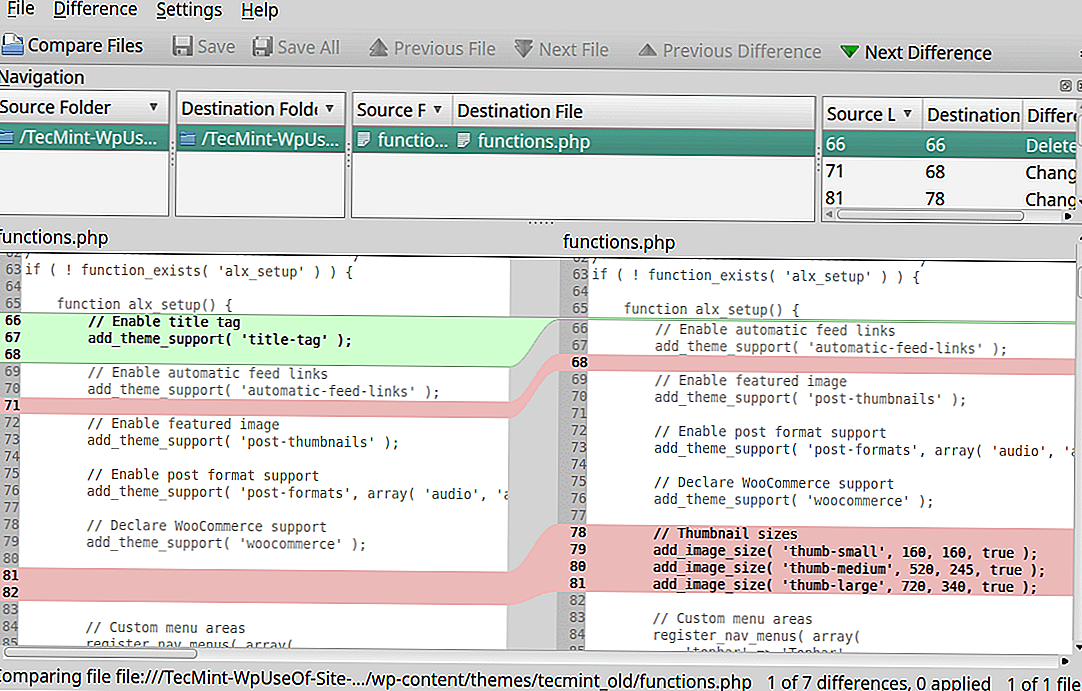
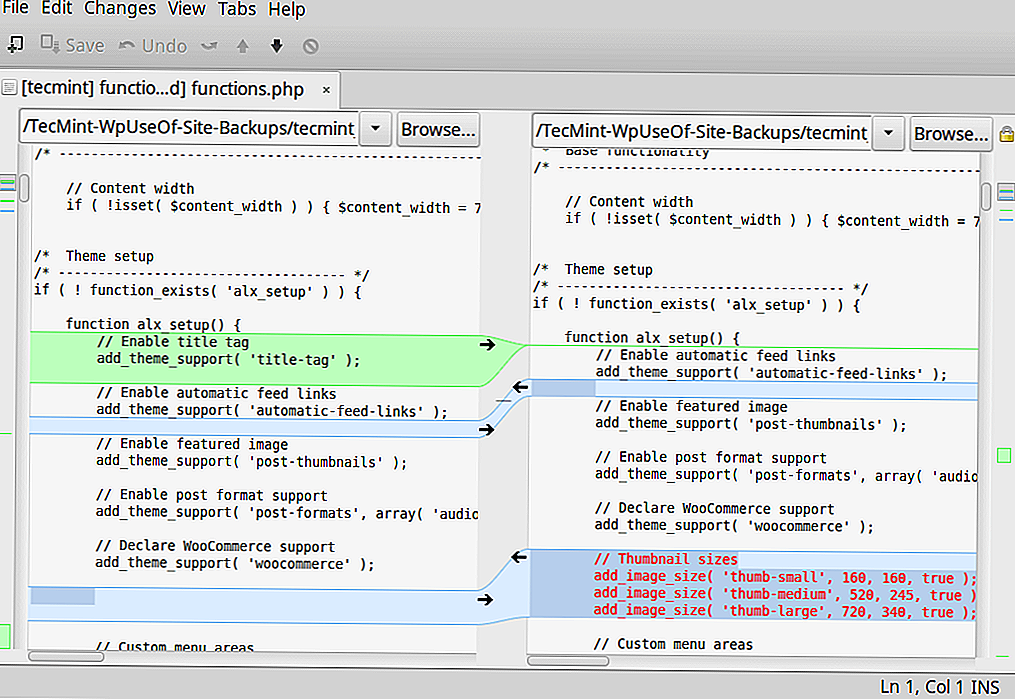
Способ 5. Сравнение файлов в программе Total Commander
В Total Commander существует инструмент сравнения файлов по содержимому, где можно не только сравнить содержимое, но и редактировать его и копировать из одного файла в другой.
После запуска Total Commander – в одной из панелей выбираете (клавиша Insert) первый файл для сравнения – во второй панели открываете папку со вторым файлом и ставим на него курсор. Вызываем программу для сравнения: «Файлы→Сравнить по содержимому».
![]()
Для внесения изменений в файл достаточно нажать на кнопку «Редактировать». В программе доступны функции копирования и отката, поиска и изменение кодировки. Если вы внесли изменения в файл, то после закрытия окна сравнения, будет предложено сохранить изменения.
Сравнение файлов Linux с помощью GUI
Существует несколько отличных инструментов для сравнения файлов в linux в графическом интерфейсе. Вы без труда разберетесь как их использовать. Давайте рассмотрим несколько из них:
1. Kompare
Kompare — это графическая утилита для работы с diff, которая позволяет находить отличия в файлах, а также объединять их. Написана на Qt и рассчитана в первую очередь на KDE. Вот ее основные особенности:
![7 способов сравнения файлов по содержимому в windows или linux [айти бубен]](https://fuzeservers.ru/wp-content/uploads/b/4/e/b4ec2b6863944dfb7a1b95a8e477a35c.jpeg)
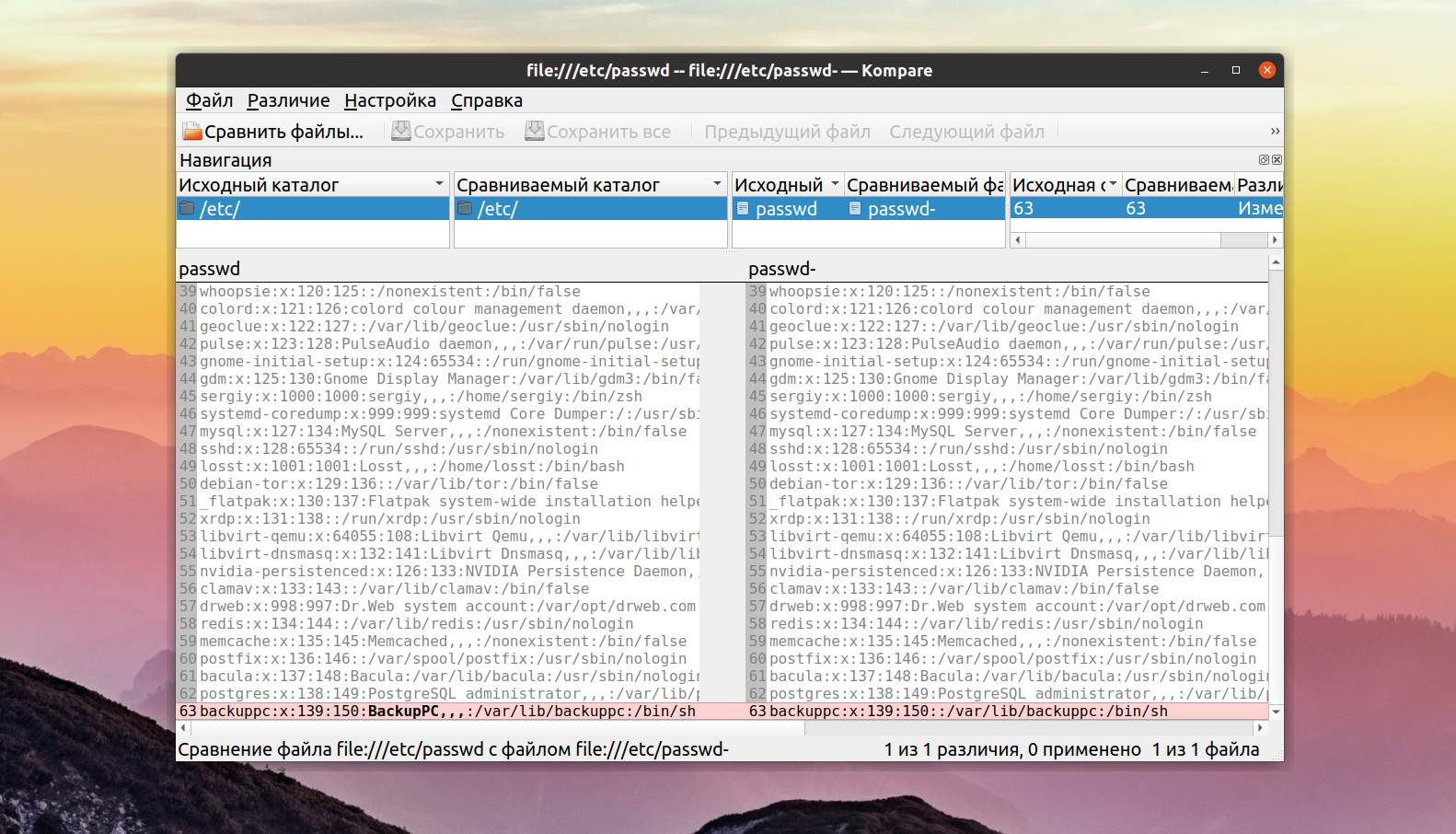
- Поддержка нескольких форматов diff;
- Поддержка сравнение файла linux и каталогов;
- Поддержка просмотра файлов diff;
- Настраиваемый интерфейс;
- Создание и применение патчей к файлам.
2. DiffMerge
DiffMerge — это кроссплатформенная программ для сравнения и объединения файлов. Позволяет сравнивать два или три файла. Поддерживается редактирование строк на лету.
Особенности:
- Поддержка сравнения каталогов;
- Интеграция с просмотрщиком файлов;
- Настраиваемая.
3. Meld
Это легкий инструмент для сравнения и объединения файлов. Он позволяет сравнивать файлы, каталоги, а также выполнять функции системы контроля версий. Программа создана для разработчиков и имеет такие особенности:
- Сравнение двух и трех файлов;
- Использование пользовательских типов и слов;
- Режим автоматического слияния и действия с боками текста;
- Поддержка Git, Mercurial, Subversion, Bazar и многое другое.
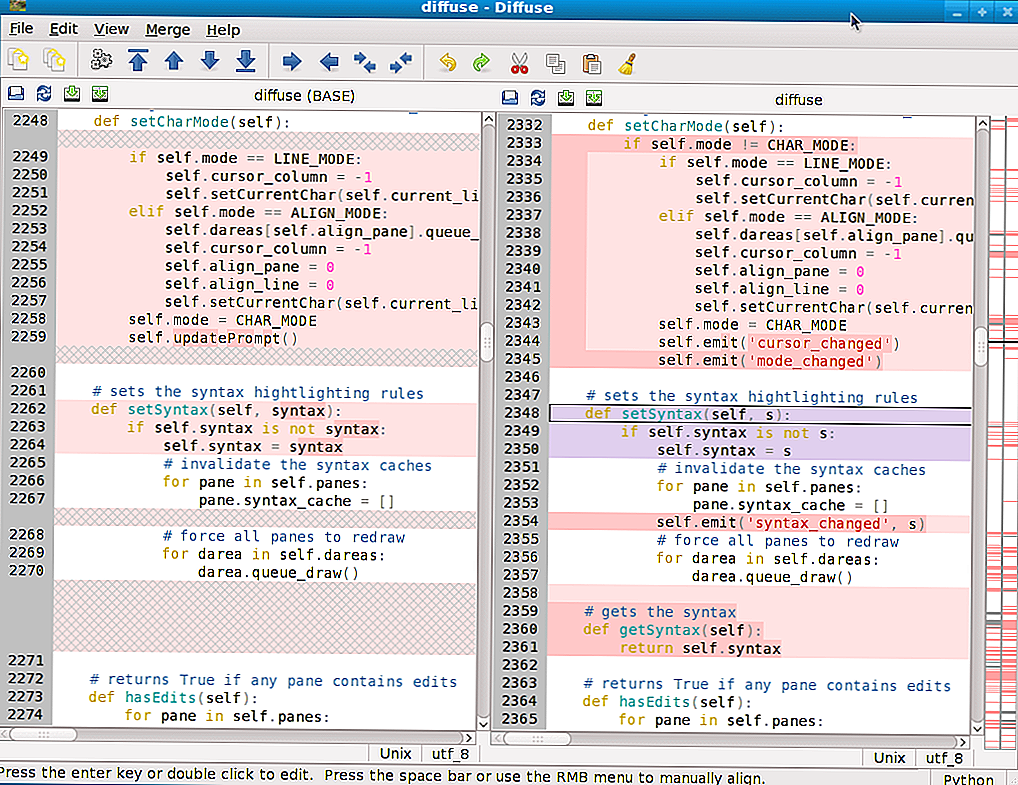
4. Diffuse
Diffuse — еще один популярный и достаточно простой инструмент для сравнения и слияния файлов. Он написан на Python. Поддерживается две основные возможности — сравнение файлов и управление версиями. Вы можете редактировать файлы прямо во время просмотра. Основные функции:
- Подсветка синтаксиса;
- Сочетания клавиш для удобной навигации;
- Поддержка неограниченного числа отмен;
- Поддержка Unicode;
- Поддержка Git, CVS, Darcs, Mercurial, RCS, Subversion, SVK и Monotone.
5. XXdiff
XXdiff — это свободный и очень мощный инструмент для сравнения и слияния файлов. Но у программы есть несколько минусов. Это отсутствие поддержки Unicode и редактирования файлов.
Особенности:
- Поверхностное или рекурсивное сравнение одного или двух файлов и каталогов;
- Подсветка отличий;
- Интерактивное объединение;
- Поддержка внешних инструментов сравнения, такие как GNU Diff, SIG Diff, Cleareddiff и многое другое;
- Расширяемость с помощью сценариев;
- Настраиваемость.
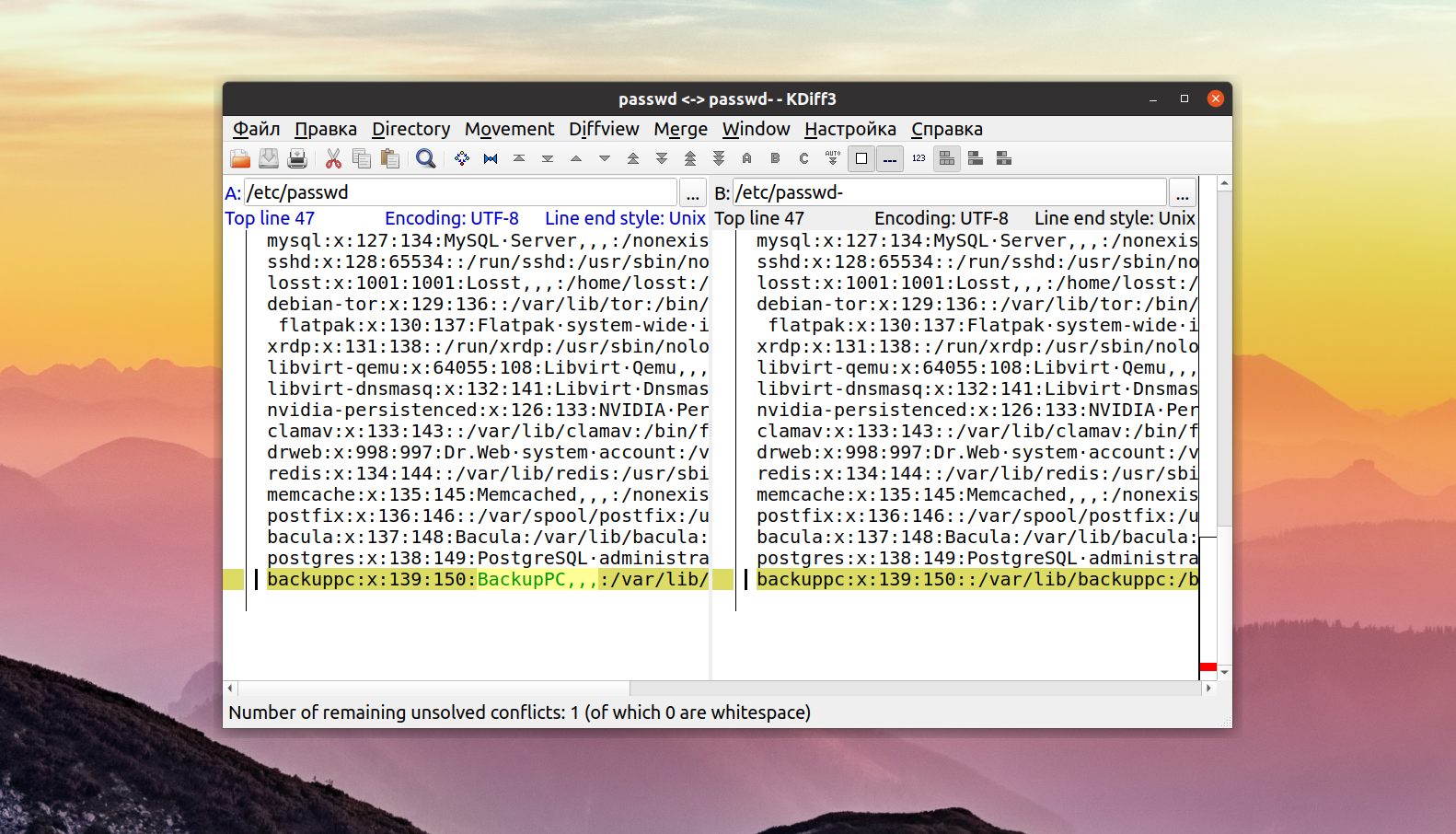
6. KDiff3
KDiff3 — еще один отличный, свободный инструмент для сравнения файлов в окружении рабочего стола KDE. Он входит в набор программ KDevelop и работает на всех платформах, включая Windows и MacOS. Можно выполнить сравнение двух файлов linux для двух или трех, или даже сравнить каталоги. Вот основные особенности:
- Отображение различий построчно и посимвольно;
- Поддержка автослияния;
- Обработка конфликтов при слиянии;
- Поддержка Unicode;
- Отображение отличий;
- Поддержка ручного выравнивания.
Использование файла Command
У нас есть коллекция файлов разных типов в нашем текущем каталоге. Это смесь документа, исходного кода, исполняемых и текстовых файлов.
Команда покажет нам, что находится в каталоге, и Опция (удобочитаемые размеры, длинный список) покажет нам размер каждого файла:
ls -hl
![]()
Давай попробуем на несколько из них и посмотрим, что мы получим:
file build_instructions.odt
file build_instructions.pdf
file COBOL_Report_Apr60.djvu
![]()
Три формата файла определены правильно. Где возможно, дает нам немного больше информации. Сообщается, что файл PDF находится в формат версии 1.5,
Даже если мы переименуем файл ODT, чтобы иметь расширение с произвольным значением XYZ, файл все равно будет правильно идентифицирован, как в пределах файловый браузер и в командной строке с помощью ,
![]()
В пределах в браузере файлов указан правильный значок. В командной строке игнорирует расширение и просматривает файл, чтобы определить его тип:
file build_instructions.xyz
![]()
С помощью на носителях, таких как графические и музыкальные файлы, обычно выдает информацию относительно их формата, кодировки, разрешения и т. д.
file screenshot.png
file screenshot.jpg
file Pachelbel_Canon_In_D.mp3
![]()
Интересно, что даже с простыми текстовыми файлами, не судит файл по его расширению. Например, если у вас есть файл с расширением «.c», содержащий стандартный текст, но не исходный код, не принимайте это за настоящий C файл исходного кода:
file function+headers.h
file makefile
file hello.c
![]()
правильно идентифицирует заголовочный файл («.h») как часть коллекции файлов исходного кода на C и знает, что make-файл является скриптом.
Нормальный формат
В простейшей форме, когда команда запускается для двух текстовых файлов без каких-либо параметров, она производит вывод в нормальном формате:
Результат будет выглядеть примерно так:
Обычный выходной формат состоит из одного или нескольких разделов, в которых описываются различия. Каждый раздел выглядит так:
, и — это команды изменения. Каждая команда изменения содержит следующее слева направо:
- Номер строки или диапазон строк в первом файле.
- Особый символ изменения.
- Номер строки или диапазон строк во втором файле.
Символ изменения может быть одним из следующих:
- — Добавьте линии.
- — Измените линии.
- — Удалить строки.
За командой изменения следуют полные строки, которые удаляются ( ) и добавляются в файл ( ).
Поясним вывод:
- — добавить строку второго файла в начало file1 (после строки ).
- — Удалить строку в первом файле. после символа означает, что если строку не удалить, она появится на строке второго файла.
- — Заменить (изменить) строку в первом файле на строки из второго файла.
- — строка в первом заменяемом файле.
- — Разделитель.
- и — Строки из второго файла, заменяющие строку в первом файле.
Сравнение файлов diff
Утилита diff linux — это программа, которая работает в консольном режиме. Ее синтаксис очень прост. Вызовите утилиту, передайте нужные файлы, а также задайте опции, если это необходимо:
$ diff опции файл1 файл2
Можно передать больше двух файлов, если это нужно. Перед тем как перейти к примерам, давайте рассмотрим опции утилиты:
- -q — выводить только отличия файлов;
- -s — выводить только совпадающие части;
- -с — выводить нужное количество строк после совпадений;
- -u — выводить только нужное количество строк после отличий;
- -y — выводить в две колонки;
- -e — вывод в формате ed скрипта;
- -n — вывод в формате RCS;
- -a — сравнивать файлы как текстовые, даже если они не текстовые;
- -t — заменить табуляции на пробелы в выводе;
- -l — разделить на страницы и добавить поддержку листания;
- -r — рекурсивное сравнение папок;
- -i — игнорировать регистр;
- -E — игнорировать изменения в табуляциях;
- -Z — не учитывать пробелы в конце строки;
- -b — не учитывать пробелы;
- -B — не учитывать пустые строки.
Это были основные опции утилиты, теперь давайте рассмотрим как сравнить файлы Linux. В выводе утилиты кроме, непосредственно, отображения изменений, выводит строку в которой указывается в какой строчке и что было сделано. Для этого используются такие символы:
- a — добавлена;
- d — удалена;
- c — изменена.
К тому же, линии, которые отличаются, будут обозначаться символом <, а те, которые совпадают — символом >.
Вот содержимое наших тестовых файлов:
Теперь давайте выполним сравнение файлов diff:
В результате мы получим строчку: 2,3c2,4. Она означает, что строки 2 и 3 были изменены. Вы можете использовать опции для игнорирования регистра:
Можно сделать вывод в две колонки:
А с помощью опции -u вы можете создать патч, который потом может быть наложен на такой же файл другим пользователем:
Чтобы обработать несколько файлов в папке удобно использовать опцию -r:
Для удобства, вы можете перенаправить вывод утилиты сразу в файл:
Как видите, все очень просто. Но не очень удобно. Более приятно использовать графические инструменты.
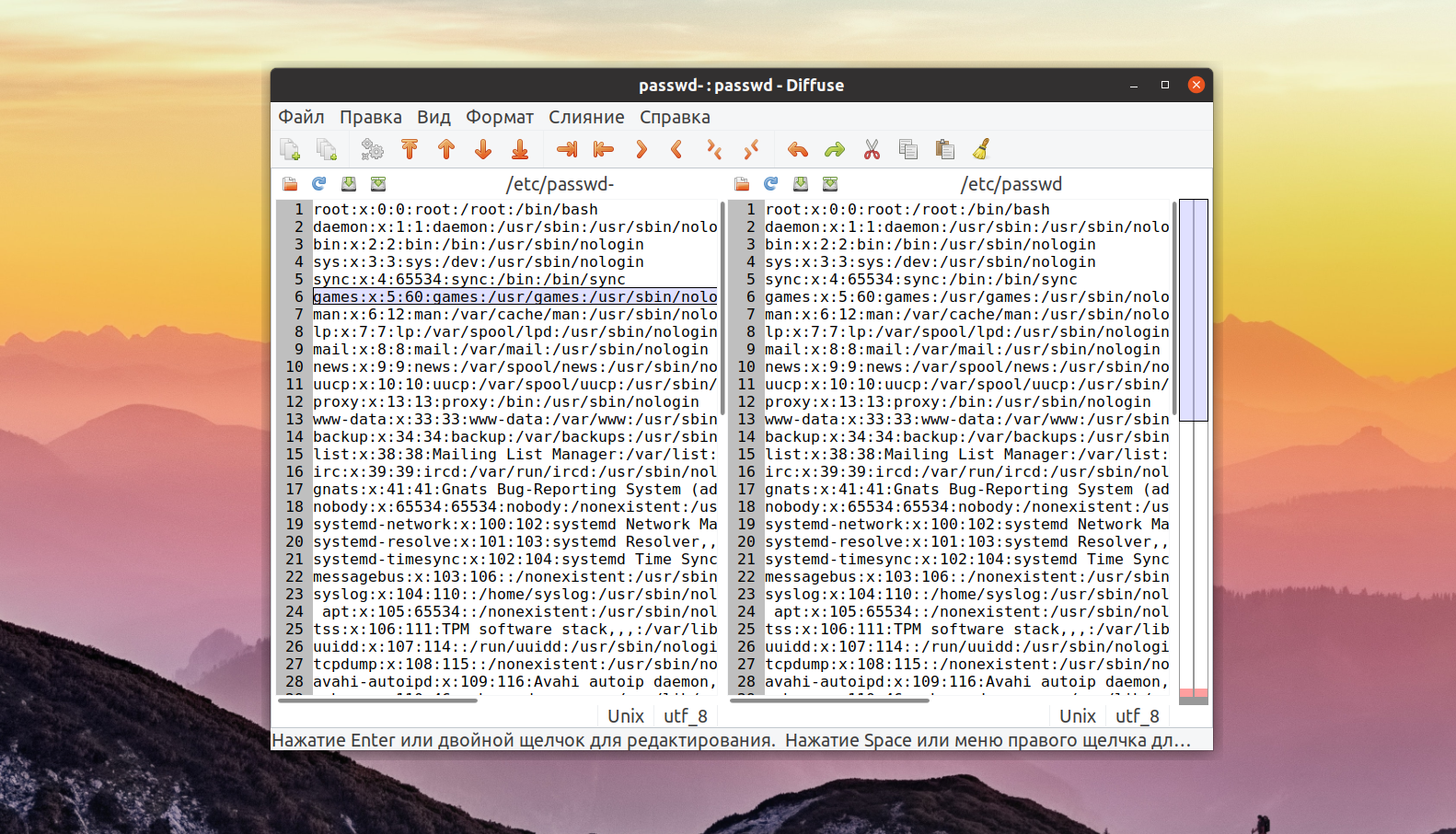
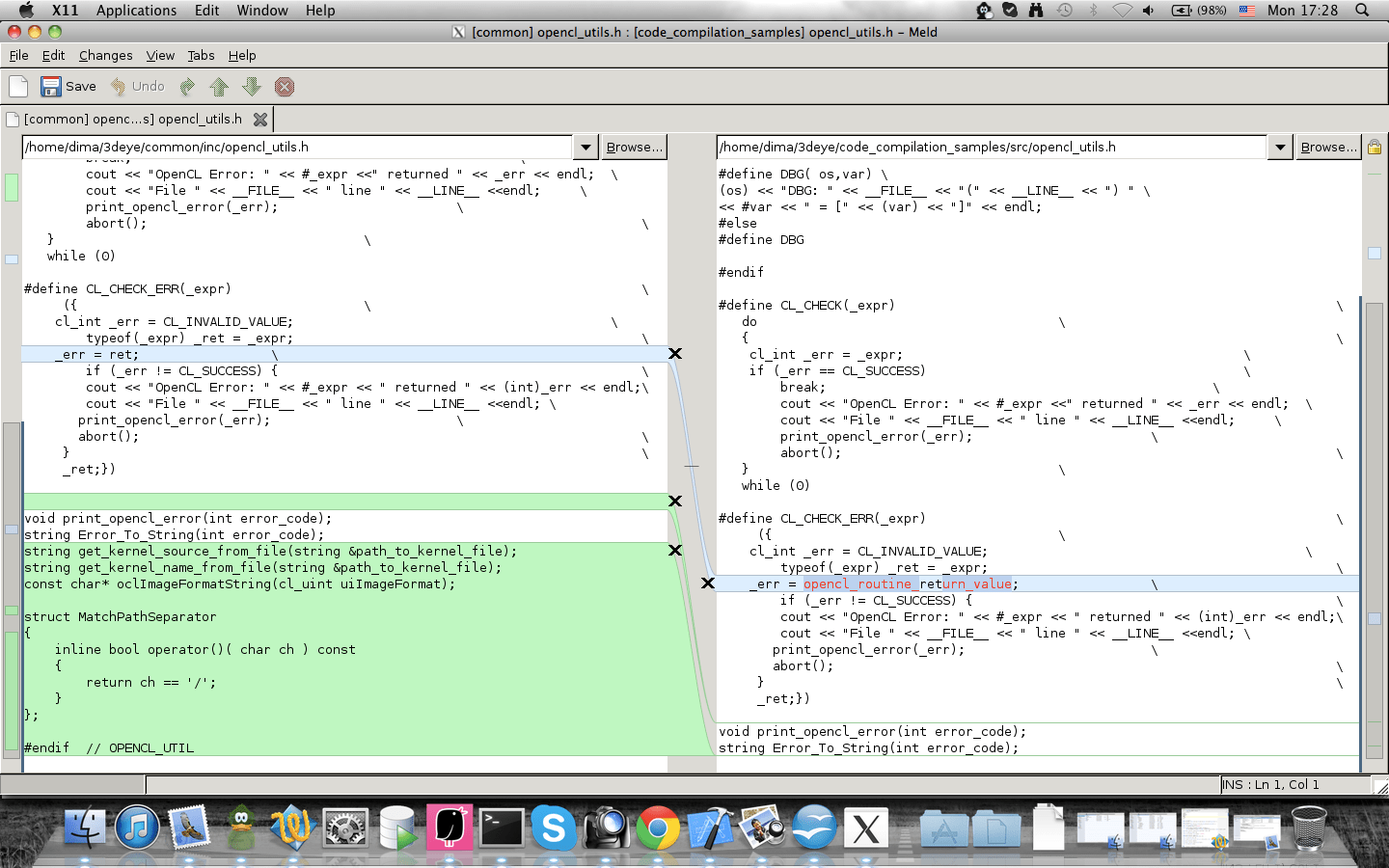
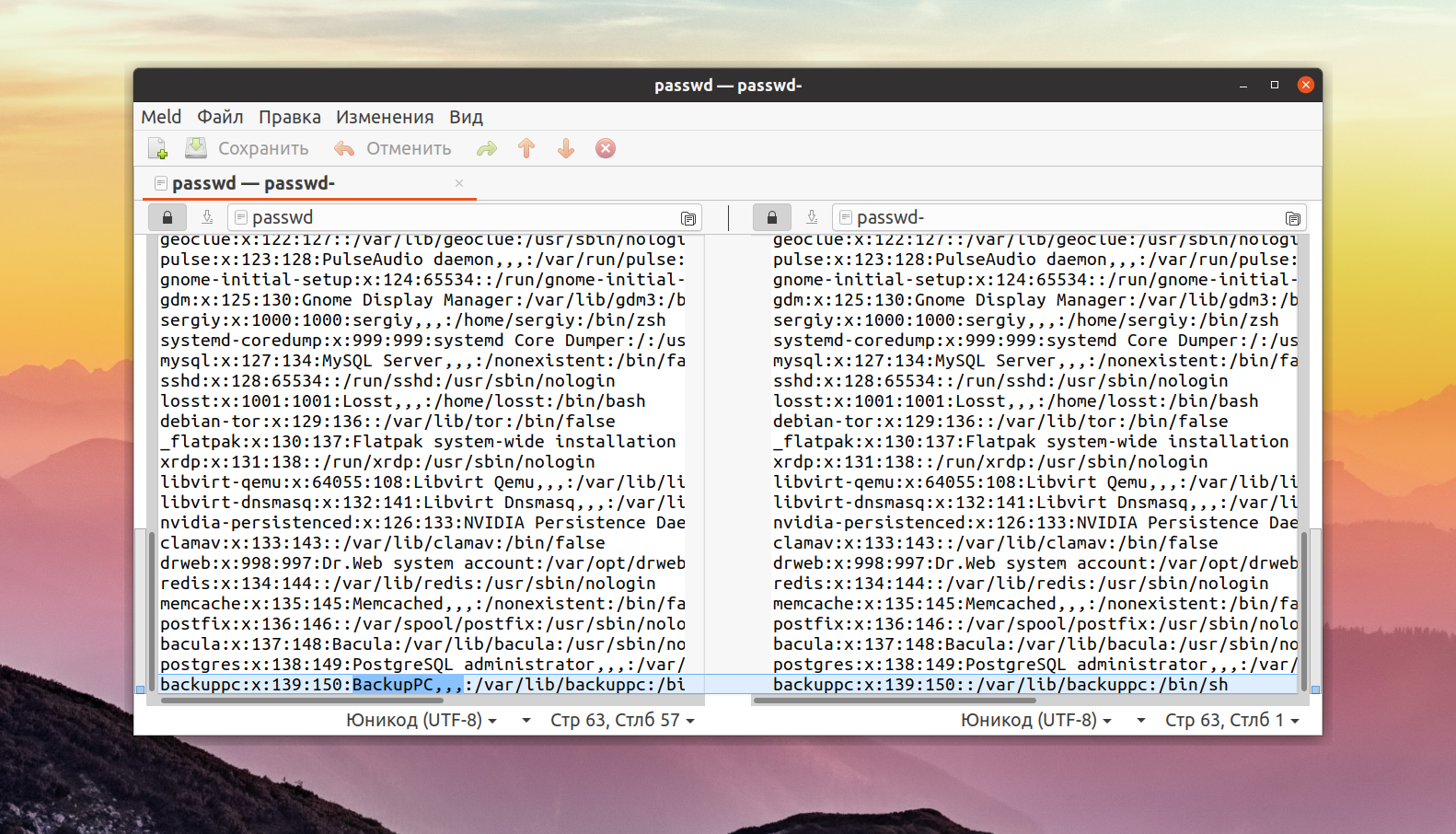
Способ 1. Meld
Meld — графический инструмент для получения различий и слияния двух файлов, двух каталогов. Meld — визуальный инструмент сравнения и объединения файлов и каталогов для Linux. Meld ориентирован, в первую очередь, для разработчиков. Однако он может оказаться полезным любому пользователю, нуждающемуся в хорошем инструменте для сравнения файлов и директорий.
В Meld вы можете сравнивать два или три файла, либо два или три каталога. Вы можете просматривать рабочую копию из популярных систем контроля версий, таких, таких как CVS, Subversion, Bazaar-NG и Mercurial. Meld представлен для большинства linux дистрибутивов (Ubuntu, Suse, Fedora и др.), и присутствует в их основных репозиториях.
# apt install meld
Meld существует и под Windows, но я не рекомендую его использовать в этой операционной системе.
Единый формат
Унифицированный выходной формат — это улучшенная версия контекстного формата, обеспечивающая меньший размер вывода.
Используйте параметр чтобы указать для печати вывода в едином формате:
Вывод начинается с имен и отметок времени файлов и одного или нескольких разделов, описывающих различия. Каждый раздел имеет следующую форму:
- — Номер строки или диапазон строк из первого и второго файлов, включенных в этот раздел.
- — строки, которые отличаются и строки контекста:
- Строки, начинающиеся с двух пробелов, являются строками контекста, одинаковыми в обоих файлах.
- Строки, начинающиеся с символа минуса ( ), — это строки, которые удаляются из первого файла.
- Строки, начинающиеся с символа плюса ( ), — это строки, добавленные из первого файла.
Пример: 3) Вывод команды Diff в едином формате (-u)
Используйте опцию «-u» в команде diff, если вы хотите выводить результат в унифицированном формате, пример показан ниже,
# diff -u aachen.txt sydney.txt
![]()
Вышеупомянутый вывод в некоторой степени похож на контекстный формат, но в унифицированном формате вывод отображается в сжатой форме, здесь первые две строки указывают имена файлов вместе с датой и временем их изменения.
Три дефиса («-») представляют первый файл, а три символа «плюс» («+++») представляют второй файл, после двух знаков @ «-1,7» обозначает строки из 1-го файла, а «+1,7» обозначает строки варьируются от 2-го файла. Кроме того, символ (+ Core OS) указывает, что эту строку необходимо добавить в первый файл, а символ дефиса (-Fedora) указывает, что эту строку необходимо удалить из первого файла, чтобы сделать его идентичным второму файлу.
Табличный вывод
При указании формата можно явным образом указать общее количество знакомест и количество знакомест, занимаемых дробной частью:
12345678
#include <stdio.h>int main(){ float x = 1.2345; printf(«x=%10.5f\n», x); getchar(); return 0;}
![]()
В приведенном примере 10 — общее количество знакомест, отводимое под значение переменной; 5 — количество позиций после разделителя целой и дробной части (после десятичной точки). В указанном примере количество знакомест в выводимом числе меньше 10, поэтому свободные знакоместа слева от числа заполняются пробелами. Такой способ форматирования часто используется для построения таблиц.
![]()





