7 ответов
Я думал, что у меня та же проблема, но на самом деле у меня есть небольшое различие, которое облегчает решение проблемы. Для других, смотрящих на этот вопрос, стоит проверить формат вашего списка ввода. В моем случае числа изначально плавающие, а не строки, как в вопросе:
Но слишком долго обрабатывая список перед созданием информационного кадра, я теряю типы, и все становится строкой.
Создание фрейма данных через массив NumPy
Дает тот же кадр данных, что и в вопросе, где записи в столбцах 1 и 2 рассматриваются как строки. Однако делать
Действительно дает фрейм данных со столбцами в правильном формате
1
SarahD
1 Фев 2019 в 09:49
Как насчет создания двух фреймов данных, каждый с разными типами данных для своих столбцов, а затем их объединения?
Результаты
После создания информационного кадра вы можете заполнить его переменными с плавающей запятой в 1-м столбце и строками (или любым другим типом данных) во 2-м столбце.
7
MikeyE
11 Июл 2017 в 05:56
Когда мне нужно было только указать конкретные столбцы, и я хочу быть явным, я использовал (per МЕСТО НАХОЖДЕНИЯ):
Итак, используя оригинальный вопрос, но предоставив ему имена столбцов …
14
Thom Ives
12 Окт 2018 в 21:02
Этот код ниже изменит тип данных столбца.
Вместо типа данных вы можете указать тип данных. Что вы хотите, например, str, float, int и т. д.
37
Akash Nayak
15 Ноя 2017 в 09:38
Как насчет этого?
442
JayQuerie.com
19 Июн 2013 в 13:39
Вот функция, которая принимает в качестве аргументов объект DataFrame и список столбцов и приводит все данные в столбцах к числам.
Итак, для вашего примера:
15
Harry Stevens
14 Июн 2017 в 05:42
Панды> = 1,0
Вот диаграмма, которая суммирует некоторые из наиболее важных преобразований в пандах.
![]()
Преобразование в строку тривиально и не показано на рисунке.
«Жесткие» и «мягкие» преобразования
Обратите внимание, что «преобразования» в этом контексте могут относиться либо к преобразованию текстовых данных в их фактический тип данных (жесткое преобразование), либо к выводу более подходящих типов данных для данных в столбцах объекта (мягкое преобразование). Чтобы проиллюстрировать разницу, взгляните на. 1
cs95
19 Фев 2020 в 06:27
1
cs95
19 Фев 2020 в 06:27
понижающее приведение
По умолчанию преобразование с помощью даст вам или dtype (или любая целочисленная ширина, присущая вашей платформе).
Обычно это то, что вам нужно, но что, если вы хотите сэкономить память и использовать более компактный тип dtype, например или
дает вам возможность понижать до целых чисел, со знаком, без знака, с плавающей точкой. Вот пример для простой серии целочисленного типа:
При понижении до целочисленного значения используется наименьшее возможное целое число, которое может содержать значения:
Понижение до ‘float’ аналогично выбирает плавающий тип меньше обычного:
2.
позволяет вам четко указать тип d, который вы хотите иметь в своем DataFrame или Series. Он очень универсален в том, что вы можете попробовать перейти от одного типа к другому.
Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция df.sum(axis=0) , которая позволяет получать суммы значений из различных строк.
Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
Похожий механизм применим и для расчёта средних значений. Например — df.mean(axis=0) .
Моя шпаргалка по pandas
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.
Нельзя сказать, что это — исчерпывающий список возможностей pandas , но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.
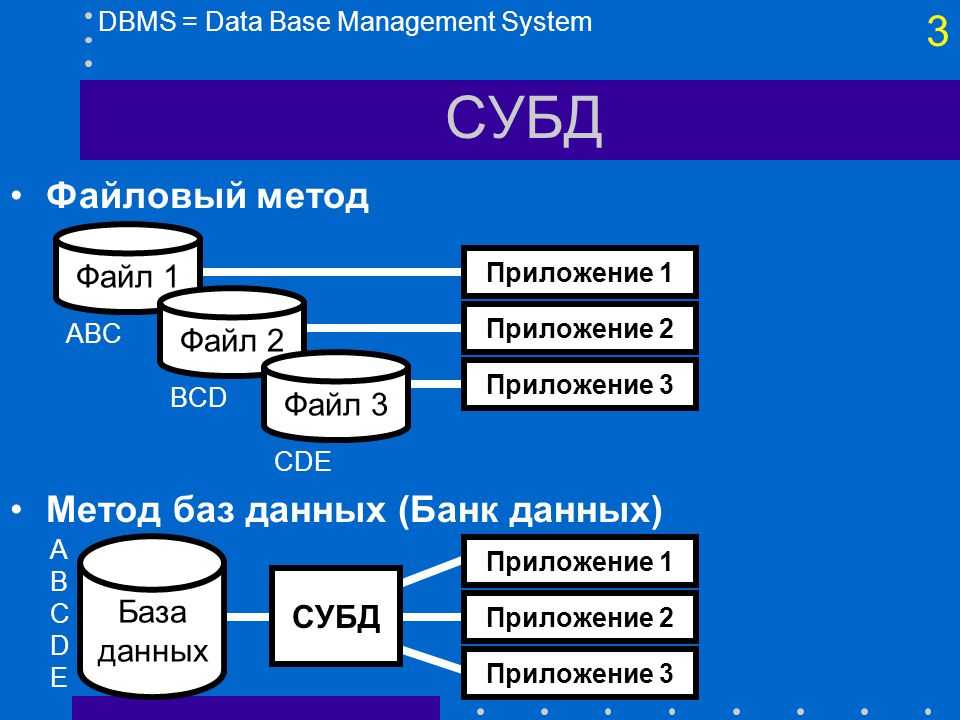
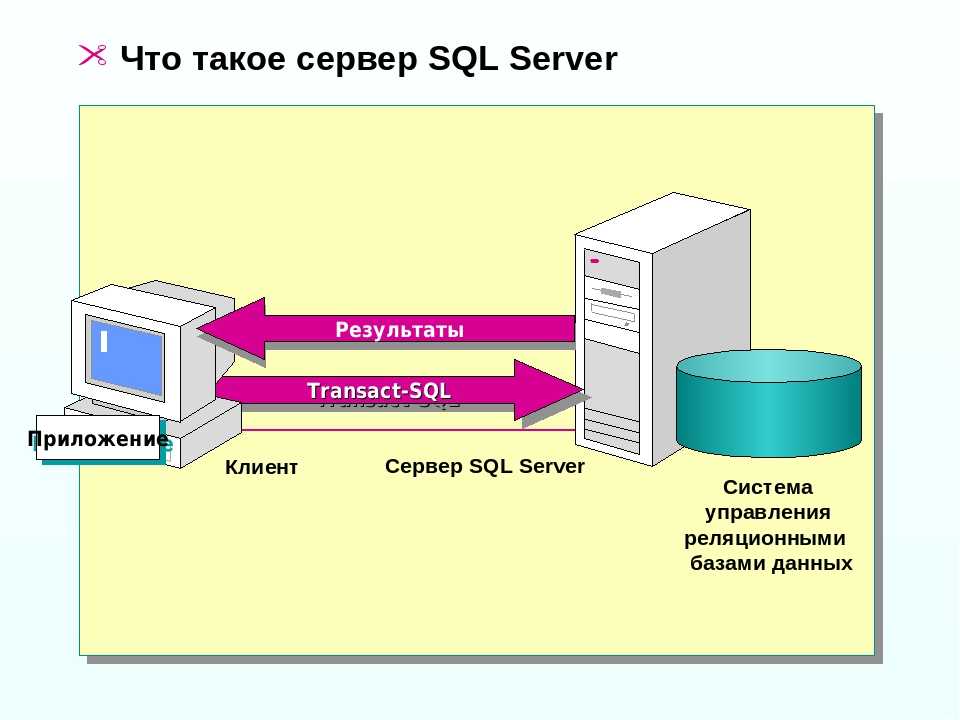
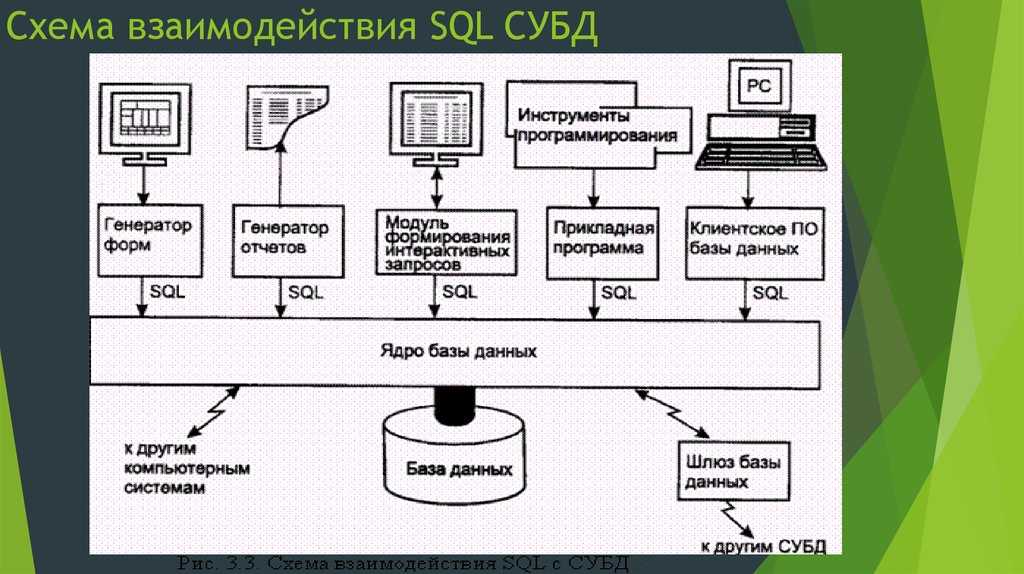
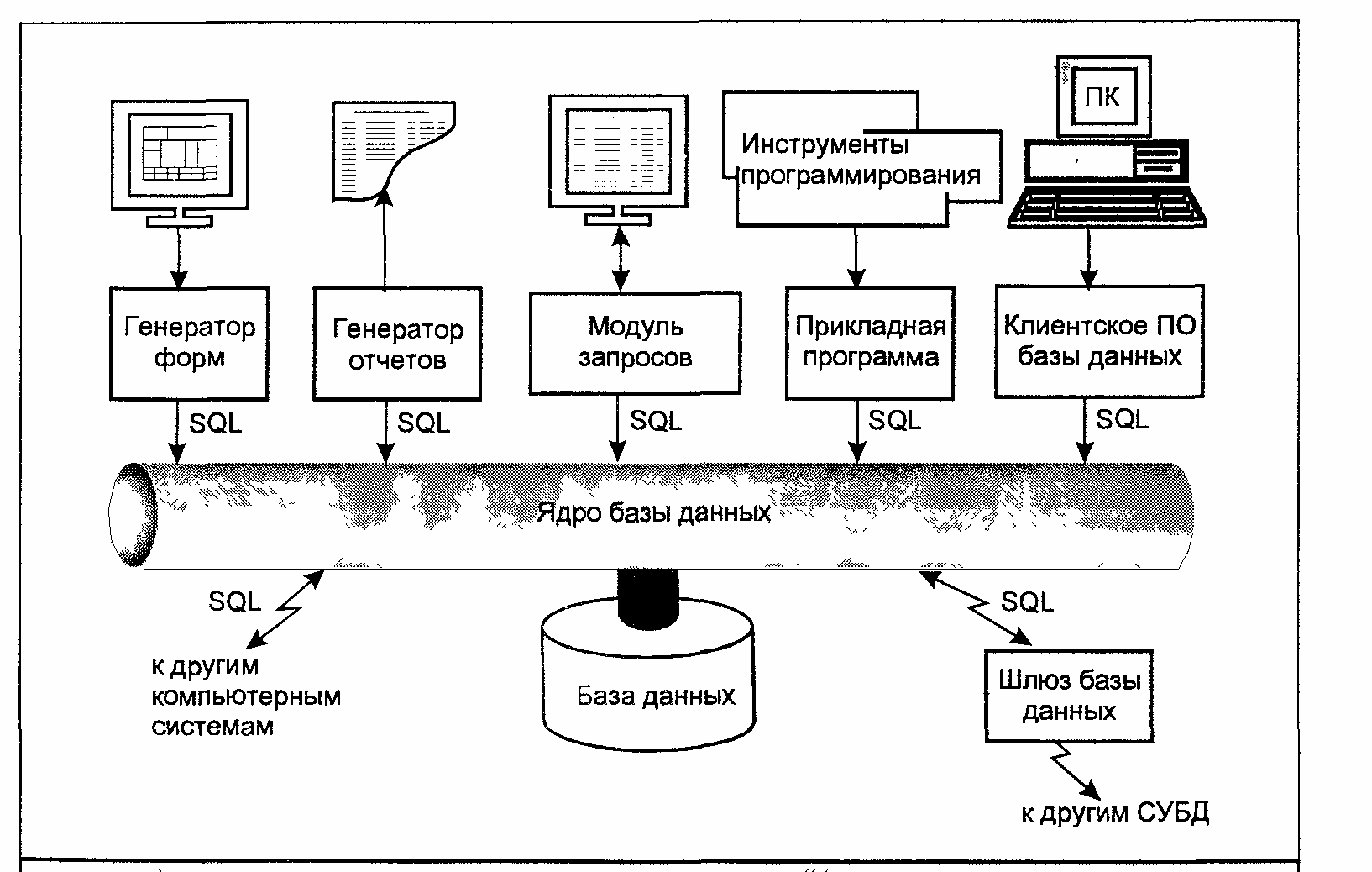
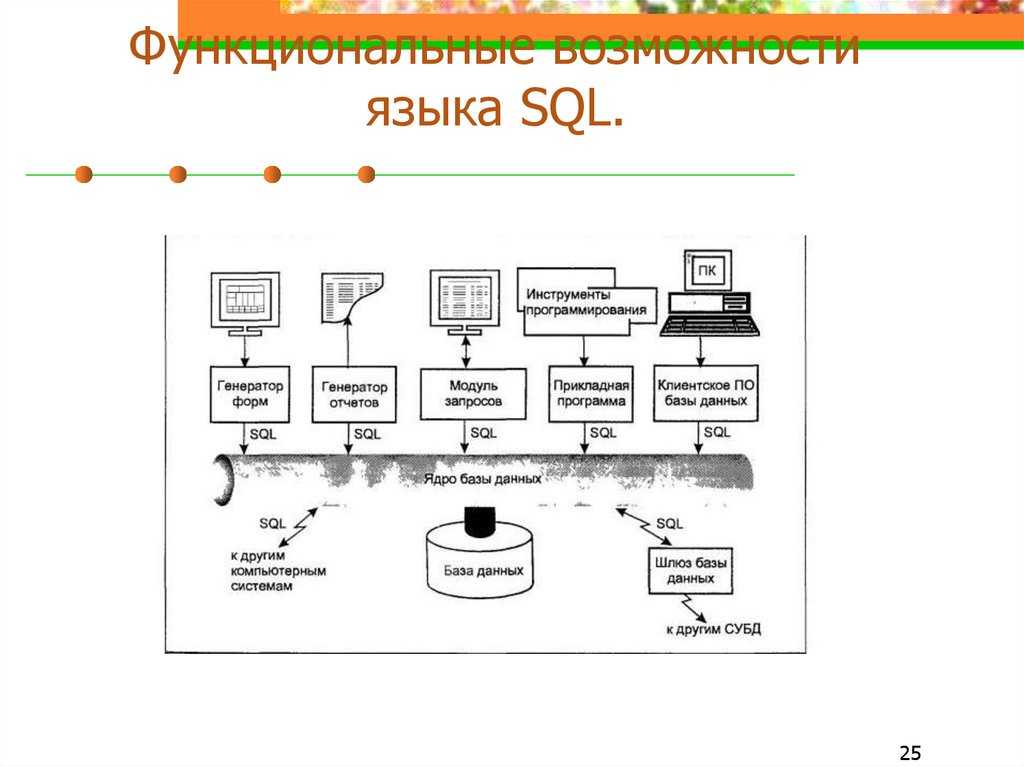
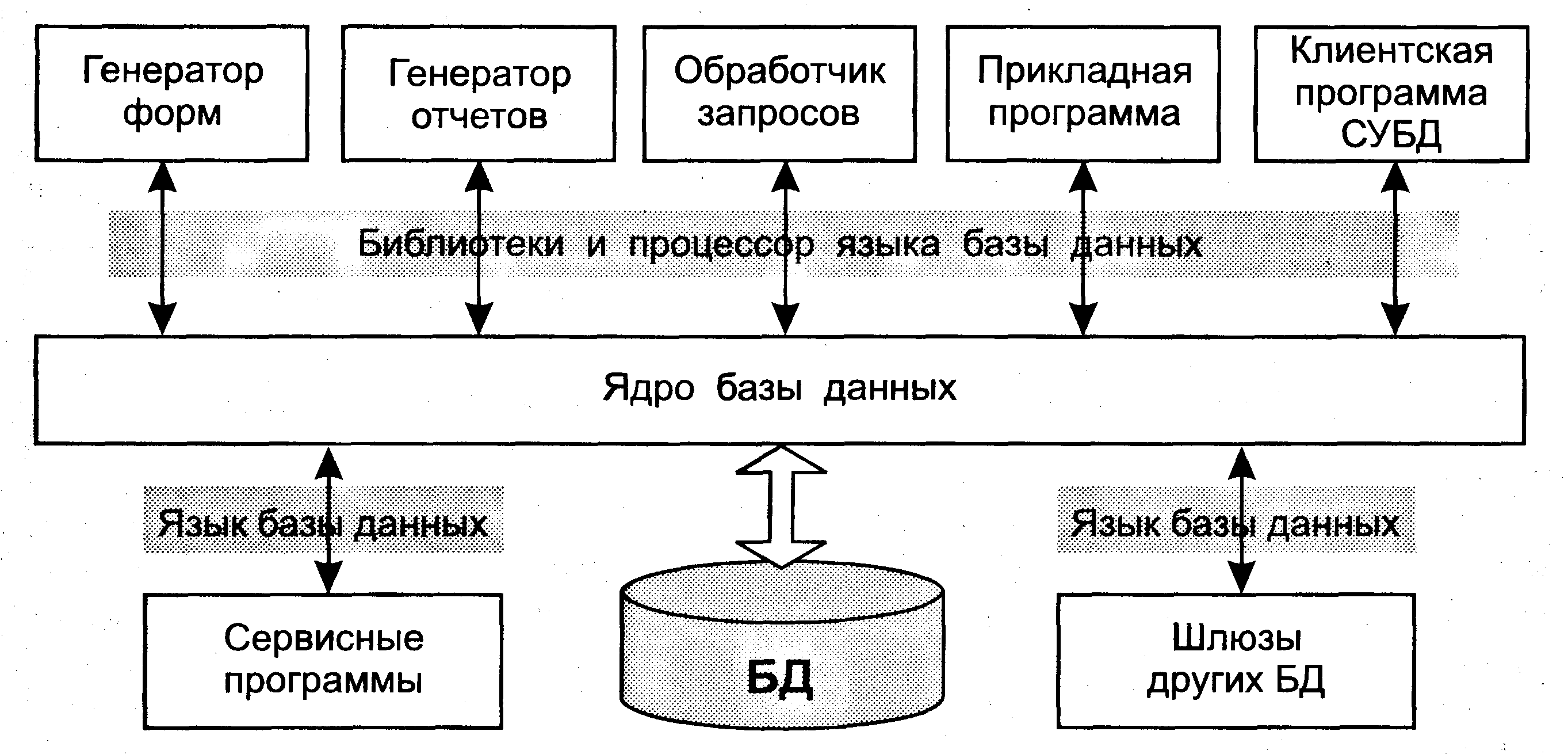
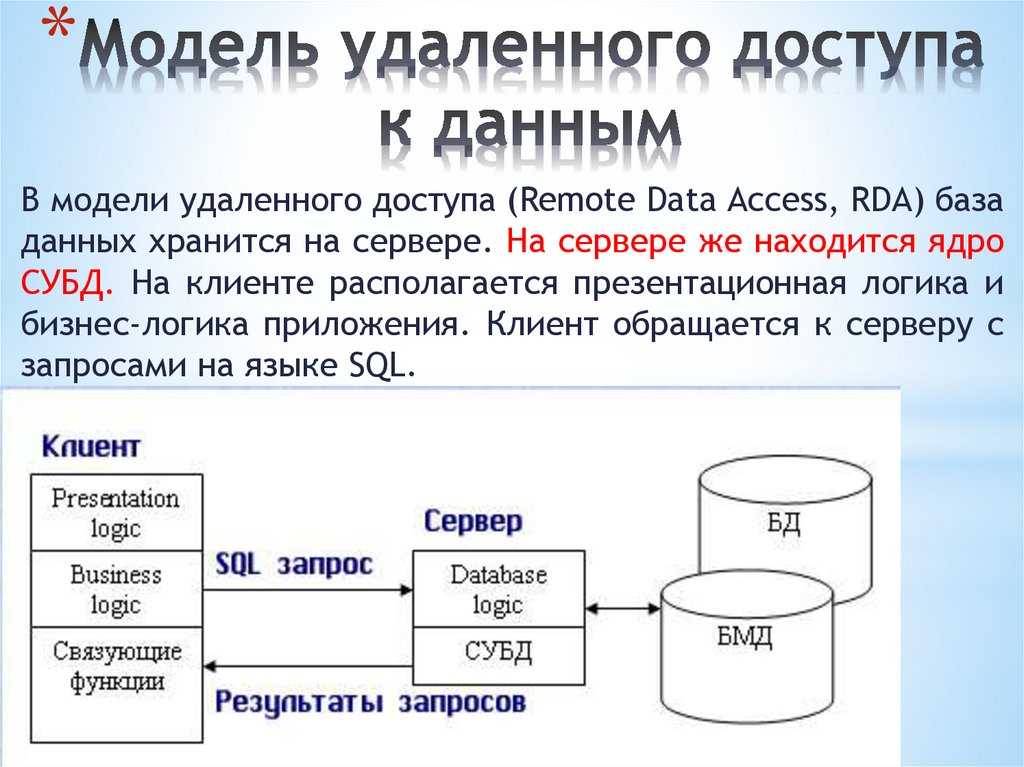
Основы работы с ODBC API
Прежде чем перейти к проблеме организации эффективного ввода-вывода, давайте рассмотрим основные этапы работы с ODBC API. Для доступа к данным при помощи ODBC любая программа вызывает API-функции, причем в определённой последовательности:
- подключение к источнику данных;
- инициализация и настройка параметров SQL-запроса/оператора;
- формирование и выполнение запроса/оператора;
- получение результатов;
- отключение от источника данных.
Для соединения с источником данных с помощью функции SQLAllocHandle следует создать «хэндлы» для среды (environment) и соединения (connection).
|
ПРИМЕЧАНИЕ
Объявления ODBC-функций и констант находятся в файлах sql.h и sqlext.h, библиотечный файл – odbc32.lib. |
Необходимо также указать, что работать мы будем с третьей версией ODBC API. Затем можно подключиться к источнику данных функцией SQLConnect. Этой функции передаются имя источника данных (Data Source Name, DSN), имя пользователя (login), пароль (password) и длины этих строк.
|
Для строк языка С, которые заканчиваются нулём, можно передавать константу SQL_NTS (Null-Terminated String). |
DSN – обязательный параметр, без которого дальнейшая работа программы невозможна. Обычно DSN создают при установке приложения. Например, инсталлятор InstallShield легко справляется с этой задачей, также он устанавливает необходимые ODBC-драйверы.
|
В этом месте стоит упомянуть о возможности создания «на лету» имени для источника данных (DSN). Функция SQLConfigDataSource позволяет программным путём создать DSN и избавляет конечного пользователя от процесса настройки DSN. |
Все последующие этапы связаны с подготовкой и выполнением SQL-запросов. Для выполнения запроса требуется хэндл, который можно получить с помощью функции SQLAllocHandle. Далее может следовать так называемый прямой запрос, который выполняет функция SQLExecDirect, а может – сложный. В последнем случае запрос сначала подготавливается с помощью SQLPrepare, затем для передачи исходных данных или установки связи между переменными и параметрами SQL-оператора применяется функция SQLBindParameter. Когда всё готово для выполнения запроса, вызывают функцию SQLExecute. Для чтения данных обычно используют пару функций SQLFetch и SQLGetData, хотя существуют и другие способы. Например, для быстрого чтения данных из таблиц используют SQLBindCol. По окончании работы с запросом ресурсы следует освободить функцией SQLFreeHandle. Нужно не забыть отключиться от источника данных (функция SQLDisconnect) и освободить все ресурсы (функция SQLFreeHandle).
Всегда следует проверять значения, которые возвращают функции ODBC API. Функции в случае успешного выполнения возвращают значения SQL_SUCCESS или SQL_SUCCESS_WITH_INFO. Для того чтобы не выполнять две операции сравнения, существует удобный макрос SQL_SUCCEEDED.
Рисунок 1. Таблица users в базе данных
Проиллюстрируем работу с ODBC API на примере добавления записи в таблицу. Пусть у нас имеется таблица users. Эту таблицу мы будем использовать и для других примеров. В таблице три поля – идентификатор (номер) пользователя, его имя (name) и величина зарплаты (salary). В таблице используются поля трёх наиболее часто используемых типов – целое число, строка символов и число с плавающей точкой.
SQLHANDLE hEnv, hDbc;
SQLRETURN res;
// --== ИНИЦИАЛИЗАЦИЯ СОЕДИНЕНИЯ С БД ЧЕРЕЗ ODBC ==--
// Получаем хэндл ODBC-среды.
res = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &hEnv);
if( !SQL_SUCCEEDED(res) ) return -1;
// Запрашиваем третью версию.
SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION, (void*)SQL_OV_ODBC3, 0);
// Получаем хэндл для соединения.
SQLAllocHandle(SQL_HANDLE_DBC, hEnv, &hDbc);
// Подключаемся к источнику данных.
res = SQLConnect(hDbc, "Sample_DB", SQL_NTS, "", SQL_NTS, "", SQL_NTS);
if( SQL_SUCCEEDED(res) )
{
// --== ВЫПОЛНЕНИЕ SQL-ЗАПРОСА ==--
SQLHSTMT hStmt;
// SQL-оператор для добавления записи в БД.
SQLCHAR szSQL[]="INSERT INTO users (id, name, salary) VALUES (1, 'Bill', 100);";
// Получаем хэндл для SQL-запроса/оператора.
SQLAllocHandle(SQL_HANDLE_STMT, hDbc, &hStmt);
// Простейший прямой SQL-запрос/оператор.
SQLExecDirect(hStmt, szSQL, SQL_NTS);
// Освобождаем ресурсы.
SQLFreeHandle(SQL_HANDLE_DBC, hDbc);
}
// --== ЗАВЕРШЕНИЕ РАБОТЫ С ODBC ==--
// Отключаемся от источника данных.
SQLDisconnect(hDbc);
// Освобождаем ресурсы.
SQLFreeHandle(SQL_HANDLE_DBC, hDbc);
SQLFreeHandle(SQL_HANDLE_ENV, hEnv);
|
Панды 0.21+ Ответ
Произошли некоторые существенные обновления переименования столбцов в версии 0.21.
- В добавлен параметр , для которого можно задать значение или . Это обновление приводит к тому, что этот метод соответствует остальному API pandas. Он по-прежнему имеет параметры и , но вы больше не обязаны их использовать.
- с , установленным в , позволяет вам переименовывать все метки индекса или столбца со списком.
Использование с или
или же
Оба приводят к следующему:
Еще можно использовать сигнатуру старого метода:
Функция также принимает функции, которые будут применяться к каждому имени столбца.
или же
Использование со списком и
Вы можете предоставить список методу , длина которого равна числу столбцов (или индекса). В настоящее время по умолчанию , но будет по умолчанию в будущих выпусках.
или же
Почему бы не использовать ?
Нет ничего плохого в том, чтобы напрямую присваивать столбцы. Это совершенно хорошее решение.
Преимущество использования состоит в том, что он может использоваться как часть цепочки методов и возвращает новую копию DataFrame. Без этого вам пришлось бы сохранять промежуточные шаги цепочки в другой переменной перед переназначением столбцов.
Обработка ошибок
Но что, если некоторые значения не могут быть преобразованы в числовой тип?
также принимает Аргумент ключевого слова, который позволяет принудительно указывать нечисловые значения как или просто игнорировать столбцы, содержащие эти значения.
Вот пример использования ряда строк с объектом dtype:
Поведение по умолчанию — повышение, если оно не может преобразовать значение. В этом случае он не может справиться со строкой ‘pandas’:
Вместо того, чтобы потерпеть неудачу, мы бы хотели, чтобы ‘pandas’ считались отсутствующим /неверным числовым значением. Мы можем привести недопустимые значения к следующим образом, используя Аргумент ключевого слова:
Третий параметр для просто игнорирует операцию, если встречается недопустимое значение:
Этот последний вариант особенно полезен, когда вы хотите преобразовать весь свой DataFrame, но не знаете, какой из наших столбцов можно надежно преобразовать в числовой тип. В этом случае просто напишите:
Функция будет применена к каждому столбцу DataFrame. Столбцы, которые можно преобразовать в числовой тип, будут преобразованы, тогда как столбцы, которые не могут (например, содержат нецифровые строки или даты), будут оставлены в покое.
Группа по
Мы обсуждали в предыдущей статье, но быстрое резюме имеет смысл здесь, особенно в свете стекирования и расстановки стоек, о которых мы поговорим позже. В тех случаях, когда транспонирование и плавление оставляют содержимое DataFrame нетронутым и «только» переупорядочивают группу внешнего вида, и следующие методы объединяют данные в той или иной форме. Группировка приведет к агрегированному DataFrame с новым индексом (значениями столбцов, по которым вы группируете). Если вы группируете по нескольким значениям, результирующий DataFrame будет иметь многоиндексный индекс.
invoices.groupby().agg( {'Meal Price':np.mean})
![]()
групповой результат с мультииндексом
Начиная с версии 0.25.1 для панд, существуют также агрегатные имена, которые делают groupby немного более читабельным.
invoices.groupby().agg( Avg_Price = pd.NamedAgg(column='Meal Price', aggfunc=np.mean))
В результате чего практически так же, как предыдущий расчет. Тем не менее, столбец переименовывается во время процесса.
1.4 Условный оператор
Проверка условий позволяет осуществлять так называемое ветвление в программе. Ветвление означает, что при определенных условиях (значениях переменных) будет выполнен один программный код, а при других условиях — другой. В R для проверки условий используется условный оператор if — else if — else следующего вида:
Сначала проверяется условие в выражении , и если оно истинно, то выполнится вложенный в фигурные скобки программный код , после чего оставшиеся условия не будут проверяться. Если первое условие ложно, программа перейдет к проверке следующего условия . Далее, если оно истинно, то выполнится вложенный код , если нет — проверка переключится на следующее условие и так далее. Заключительный код , следующий за словом , выполнится только если ложными окажутся все предыдущие условия.
Например, сгенерируем случайное число, округлим его до одного знака после запятой и проверим относительно нуля:
Условия можно использовать, в частности, для того чтобы обрабатывать пользовательский ввод в программе. Например, охарактеризуем положение точки относительно Полярного круга:
Пользователь вводит , а мы оцениваем результат:
Изменить тип данных столбцов в Pandas
Я хочу преобразовать таблицу, представленную в виде списка списков, в Pandas DataFrame. В качестве чрезвычайно упрощенного примера:
Каков наилучший способ преобразования столбцов в соответствующие типы, в данном случае столбцы 2 и 3 в числа с плавающей точкой? Есть ли способ указать типы при конвертации в DataFrame? Или лучше сначала создать DataFrame, а затем перебрать столбцы, чтобы изменить тип каждого столбца? В идеале я хотел бы сделать это динамически, потому что может быть сотни столбцов, и я не хочу точно указывать, какие столбцы какого типа. Все, что я могу гарантировать, это то, что каждый столбец содержит значения одного типа.
У вас есть три основных варианта для преобразования типов в пандах.
Индексация строк датафреймов
Допустим у нас есть следующий датафрейм:
| X | Y | Z | |
|---|---|---|---|
| a | 2 | 8 | 5 |
| b | 1 | 7 | 6 |
| c | 4 | 6 | 6 |
| d | 3 | 4 | 5 |
| e | 6 | 7 | 3 |
Что бы обратиться к его строкам по их индексу (меткам) в index перед оператором нужно указать индексатор :
X 4 Y 6 Z 6 Name: c, dtype: int32
А что бы обратиться к той же строке, но по целочисленному индексу, нужен индексатор :
X 4 Y 6 Z 6 Name: c, dtype: int32
Возвращаемые индексаторами, объекты являются сериями:
pandas.core.series.Series
Причем индексы этих серий, совпадают с названиями столбцов датафрейма, что в общем-то более чем логично:
Index(, dtype='object')
Что бы получить доступ к элементу извлеченной строки, нужно принять во внимание, что этот элемент находится на пересечении строки и столбца, поскольку строка уже извлечена, то остается указать просто название нужного столбца в качестве индекса во втором операторе :
6
Индексаторами и можно воспользоваться для выделения срезов (фрагментов таблиц):
| X | Y | Z | |
|---|---|---|---|
| b | 1 | 7 | 6 |
| c | 4 | 6 | 6 |
| d | 3 | 4 | 5 |
| X | Y | Z | |
|---|---|---|---|
| b | 1 | 7 | 6 |
| c | 4 | 6 | 6 |
| d | 3 | 4 | 5 |
Добиться аналогичного результата можно, просто, указав начальный и конечный индекс среза:
| X | Y | Z | |
|---|---|---|---|
| b | 1 | 7 | 6 |
| c | 4 | 6 | 6 |
| d | 3 | 4 | 5 |
Так же как и в NumPy получить датафрейм из нужных строк можно с помощью логических массивов:
| X | Y | Z | |
|---|---|---|---|
| a | 2 | 8 | 5 |
| c | 4 | 6 | 6 |
| e | 6 | 7 | 3 |
понижающее приведение
По умолчанию преобразование с to_numeric() даст вам тип a int64 или float64 dtype (или любую целую ширину, присущую вашей платформе).
Обычно это то, что вы хотите, но что, если вы хотите сэкономить память и использовать более компактный dtype, например float32 , или int8 ?
to_numeric() дает вам возможность понижать до «целое число», «подписано», «без знака», «с плавающей точкой». Вот пример для простой серии s целочисленного типа:
Понижение до «целого» использует наименьшее возможное целое число, которое может содержать значения:
Даункастинг до ‘float’ аналогично выбирает плавающий тип меньше обычного:
Обработка ошибок
Но что, если некоторые значения нельзя преобразовать в числовой тип?
также занимает аргумент ключевого слова, который позволяет вам принудительно использовать нечисловые значения или просто игнорируйте столбцы, содержащие эти значения.
Вот пример использования серии строк который имеет объект dtype:
Поведение по умолчанию — поднять, если не удается преобразовать значение. В этом случае он не может справиться со строкой pandas:
Вместо того, чтобы терпеть неудачу, мы могли бы захотеть, чтобы «панды» считались недостающим / неверным числовым значением. Мы можем заставить недопустимые значения следующим образом, используя аргумент ключевого слова:
Третий вариант для просто игнорировать операцию, если обнаружено недопустимое значение:
Этот последний вариант особенно полезен, когда вы хотите преобразовать весь свой DataFrame, но не знаете, какие из наших столбцов можно надежно преобразовать в числовой тип. В таком случае просто напишите:
Функция будет применена к каждому столбцу DataFrame. Столбцы, которые можно преобразовать в числовой тип, будут преобразованы, в то время как столбцы, которые не могут (например, содержат нецифровые строки или даты), останутся без изменений.
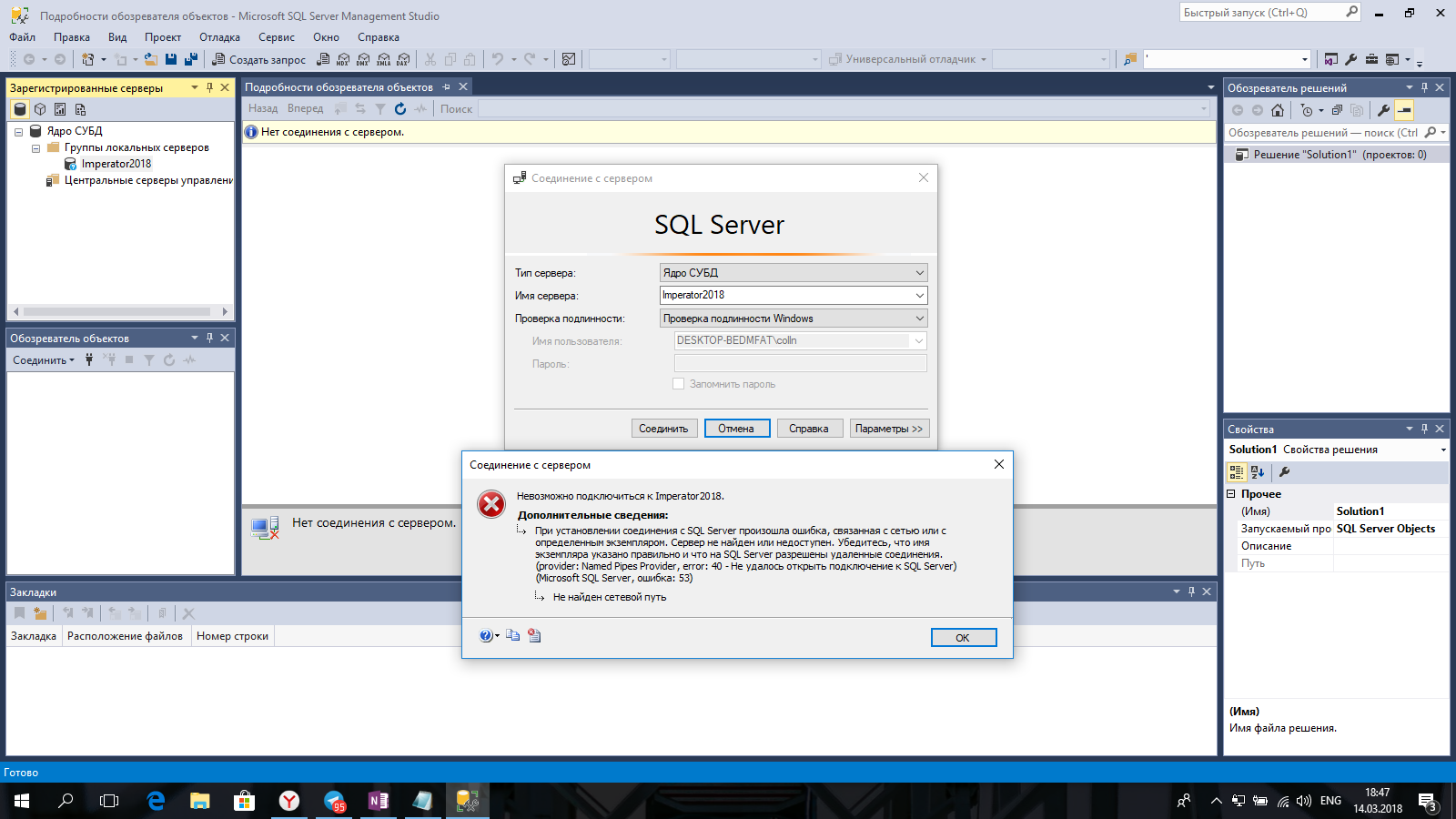
Будь осторожен
является мощным средством, но иногда оно будет преобразовывать значения «неправильно». Например:
Это маленькие целые числа, так как насчет преобразования в 8-битный тип без знака для экономии памяти?
Преобразование сработало, но значение -7 было округлено до 249 (то есть 2 8 — 7)!
Попытка снизить рейтинг с помощью может помочь предотвратить эту ошибку.
3.
В версии 0.21.0 панды представил метод —- +: = 43 =: + —- для преобразования столбцов DataFrame, имеющих тип данных объекта, в более конкретный тип (мягкие преобразования).
Например, вот DataFrame с двумя столбцами типа объекта. Один содержит действительные целые числа, а другой содержит строки, представляющие целые числа:
Используя , вы можете изменить тип столбца ‘a’ на int64:
Столбец ‘b’ был оставлен в покое, поскольку его значения были строками, а не целыми числами. Если вы хотите попробовать преобразовать оба столбца в целочисленный тип, вместо этого вы можете использовать .
Метод 1: использование astype()
DataFrame.astype() приводит этот DataFrame к указанному типу данных. Ниже приводится синтаксис метода.
Нас интересует только первый аргумент dtype – это тип данных или dict имени столбца.
Итак, давайте использовать метод astype() с аргументом dtype, чтобы изменить тип данных одного или нескольких столбцов DataFrame.
Как изменить тип данных одного столбца?
Давайте сначала начнем с изменения типа данных только для одного столбца.
В следующей программе мы изменим тип данных столбца a на float.
Как изменить тип данных нескольких столбцов?
Теперь давайте изменим тип данных более чем для одного столбца. Все, что нам нужно сделать, это предоставить больше пар column_name: datatype key:value в аргументе метода astype().
В следующей программе мы изменим тип данных столбца a на float, а b на int8.
Как изменить тип данных всех столбцов?
Если вы хотите изменить тип данных всех столбцов DataFrame, вы можете просто передать этот тип данных в качестве аргумента методу astype() без словаря.
В следующей программе мы изменим тип данных всех столбцов на float.
Слияние — на / суффиксы
Если мы предоставим явноПараметр this переопределит поведение по умолчанию и попытается найти предоставленный столбец в обоих DataFrames. Оставшиеся дублированные столбцы, которые не используются для объединения, будут добавлены к суффиксу.
В следующем примере мы объединяем только, Тем не менее, так кака такжестолбцы также присутствуют в обоих DataFrames. Этих столбцов будет достаточно, чтобы указать, из какого источника DataFrame они происходят, как можно видеть в следующем примере.
Бег:
Объединить в один общий столбец, суффиксы по умолчанию
Мы также можем указать пользовательские суффиксы как это:
Объединение в одном общем столбце пользовательских суффиксов (_base и _join)
понижающее приведение
По умолчанию преобразование с помощью даст вам либо либо тип (или любую целую ширину, присущую вашей платформе).
Обычно это то, что вы хотите, но что, если вы хотите сэкономить память и использовать более компактный dtype, такой как или ?
дает вам возможность понижать до целых чисел, со , без знака, с плавающей точкой. Вот пример для простой серии целочисленного типа:
При понижении до целочисленного значения используется наименьшее возможное целое число, которое может содержать значения:
При даункинге с плавающей точкой аналогично выбирается плавающий тип меньше обычного:
2.
Метод позволяет вам четко указывать dtype, который вы хотите иметь в своем DataFrame или Series. Он очень универсален в том, что вы можете попробовать перейти от одного типа к другому.
Одна линия или трубопроводные решения
Я сосредоточусь на двух вещах:
-
ОП четко заявляет
Я не хочу решать проблему замены или удаления первого символа заголовка каждого столбца. ОП уже сделал этот шаг. Вместо этого я хочу сосредоточиться на замене существующего объекта новым объектом, содержащим список имен столбцов замены.
-
где — список имен новых столбцов настолько прост, насколько это возможно. Недостаток этого подхода заключается в том, что он требует редактирования атрибута существующего фрейма данных, и он не выполняется встроенным. Я покажу несколько способов сделать это с помощью конвейерной обработки, не редактируя существующий фрейм данных.
Настройка 1 Чтобы сосредоточиться на необходимости переименования заменяемых имен столбцов в уже существующий список, я создам новый примерный фрейм данных с исходными именами столбцов и несвязанными именами новых столбцов.
Решение 1
Уже было сказано, что если у вас есть словарь, сопоставляющий старые имена столбцов с новыми именами столбцов, вы можете использовать .
Однако вы можете легко создать этот словарь и включить его в вызов . Далее используется тот факт, что при переборе мы перебираем каждое имя столбца.
Это прекрасно работает, если ваши оригинальные имена столбцов являются уникальными. Но если они не, то это ломается.
Настройка 2 неуникальные столбцы
Решение 2 используя аргумент
Во-первых, обратите внимание, что происходит, когда мы пытаемся использовать решение 1:
Мы не отображали список как имена столбцов. Мы закончили тем, что повторили . Вместо этого мы можем использовать аргумент функции , перебирая столбцы .
Решение 3 Реконструкц. Это следует использовать, только если у вас есть одно для всех столбцов. В противном случае вы получите для всех столбцов, и для их преобразования требуется больше словарной работы.
Одиночное
Смешанный
Решение 4 Это хитрый трюк с и . позволяет нам устанавливать индекс внутри строки, но соответствующий отсутствует. Таким образом, мы можем транспонировать, затем и транспонировать обратно. Тем не менее, здесь применимо то же единственное против смешанного из решения 3.
Одиночное
Смешанный
Решение 5 Используйте в , который циклически перебирает каждый элемент В этом решении мы передаем лямбду, которая принимает , но затем игнорирует ее. Он также принимает , но не ожидает его. Вместо этого итератор задан в качестве значения по умолчанию, и затем я могу использовать его для циклического перехода по одному за раз, независимо от значения .


И как указали мне в чате sopython , если я добавлю между и , я смогу защитить свою переменную . Хотя в этом контексте я не верю, что это нуждается в защите. Это все еще стоит упомянуть.
Обработка ошибок
Но что, если некоторые значения не могут быть преобразованы в числовой тип?
to_numeric() также принимает errors аргумент ключевого слова, который позволяет принудительно указывать нечисловые значения NaN или просто игнорирует столбцы, содержащие эти значения.
Вот пример использования серии строк, s имеющих объект dtype:
Поведение по умолчанию — повышение, если оно не может преобразовать значение. В этом случае он не может справиться со строкой ‘pandas’:
Вместо того, чтобы потерпеть неудачу, мы могли бы хотеть, чтобы ‘панды’ считались отсутствующим / плохим числовым значением. Мы можем привести недопустимые значения к NaN следующему, используя errors ключевое слово аргумент:
Третий вариант errors — просто игнорировать операцию, если встречается недопустимое значение:
Этот последний вариант особенно полезен, когда вы хотите преобразовать весь свой DataFrame, но не знаете, какие из наших столбцов можно надежно преобразовать в числовой тип. В этом случае просто напишите:
Функция будет применяться к каждому столбцу DataFrame. Столбцы, которые можно преобразовать в числовой тип, будут преобразованы, тогда как столбцы, которые не могут (например, содержат нецифровые строки или даты), будут оставлены в покое.
Основное использование
Просто выберите тип: вы можете использовать dum типа NumPy (например,), некоторые типы Python (например, bool) или типы, специфичные для панд (например, категориальный dtype).
Вызовите метод для объекта, который вы хотите преобразовать, и попытается преобразовать его для вас:
Обратите внимание, что я сказал «попробуй» — если не знает, как преобразовать значение в Series или DataFrame, это вызовет ошибка. Например, если у вас есть или Значение вы получите ошибку при попытке преобразовать его в целое число
Начиная с pandas 0.20.0, эту ошибку можно устранить, передав . Ваш оригинальный объект будет возвращен нетронутым.
Вывод на экран
Чаще всего датафреймы содержат очень много строк и столбцов, которые просто не могут поместиться на экран. В качестве примера, мы можем воспользоваться наборами данных из пакета Seaborn. Скорее всего вы работаете в дистрибутиве Anaconda или в Гугловском колабе, так что Seaborn наверняка у вас уже установлен. А если нет, то быстрее пересаживайтесь на анаконду и колаб!
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 16.99 | 1.01 | Female | No | Sun | Dinner | 2 | |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
| … | … | … | … | … | … | … | … |
| 239 | 29.03 | 5.92 | Male | No | Sat | Dinner | 3 |
| 240 | 27.18 | 2.00 | Female | Yes | Sat | Dinner | 2 |
| 241 | 22.67 | 2.00 | Male | Yes | Sat | Dinner | 2 |
| 242 | 17.82 | 1.75 | Male | No | Sat | Dinner | 2 |
| 243 | 18.78 | 3.00 | Female | No | Thur | Dinner | 2 |
Это данные о чаевых в ресторане, которые состоят из семи столбцов и 244-х строк, понятно, что выводить все эти строки на экран не имеет смысла, т.к. получится очень длинная таблица. Что бы получить какое-то представление о таблице можно воспользоваться методом :
RangeIndex: 244 entries, 0 to 243 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 total_bill 244 non-null float64 1 tip 244 non-null float64 2 sex 244 non-null category 3 smoker 244 non-null category 4 day 244 non-null category 5 time 244 non-null category 6 size 244 non-null int64 dtypes: category(4), float64(2), int64(1) memory usage: 7.3 KB
Да, чаще всего серии и датафреймы являются очень большими и их вывод просто не помещается на экран, поэтому, они выводятся в «урезанной» форме:
0 0.756637
1 0.885349
2 0.525605
3 0.753712
4 0.388052
...
2995 0.484288
2996 0.860380
2997 0.714192
2998 0.315336
2999 0.292255
Length: 3000, dtype: float64
Что бы просмотреть их небольшой фрагмент, можно воспользоваться методами или :
0 0.756637 1 0.885349 2 0.525605 3 0.753712 4 0.388052 dtype: float64
2995 0.484288 2996 0.860380 2997 0.714192 2998 0.315336 2999 0.292255 dtype: float64
По умолчанию выводится всего 5 строк, но мы можем указать столько строк сколько нам нужно:
0 0.756637 1 0.885349 2 0.525605 3 0.753712 4 0.388052 5 0.521513 6 0.728470 7 0.872524 8 0.451322 9 0.343387 10 0.441652 dtype: float64