
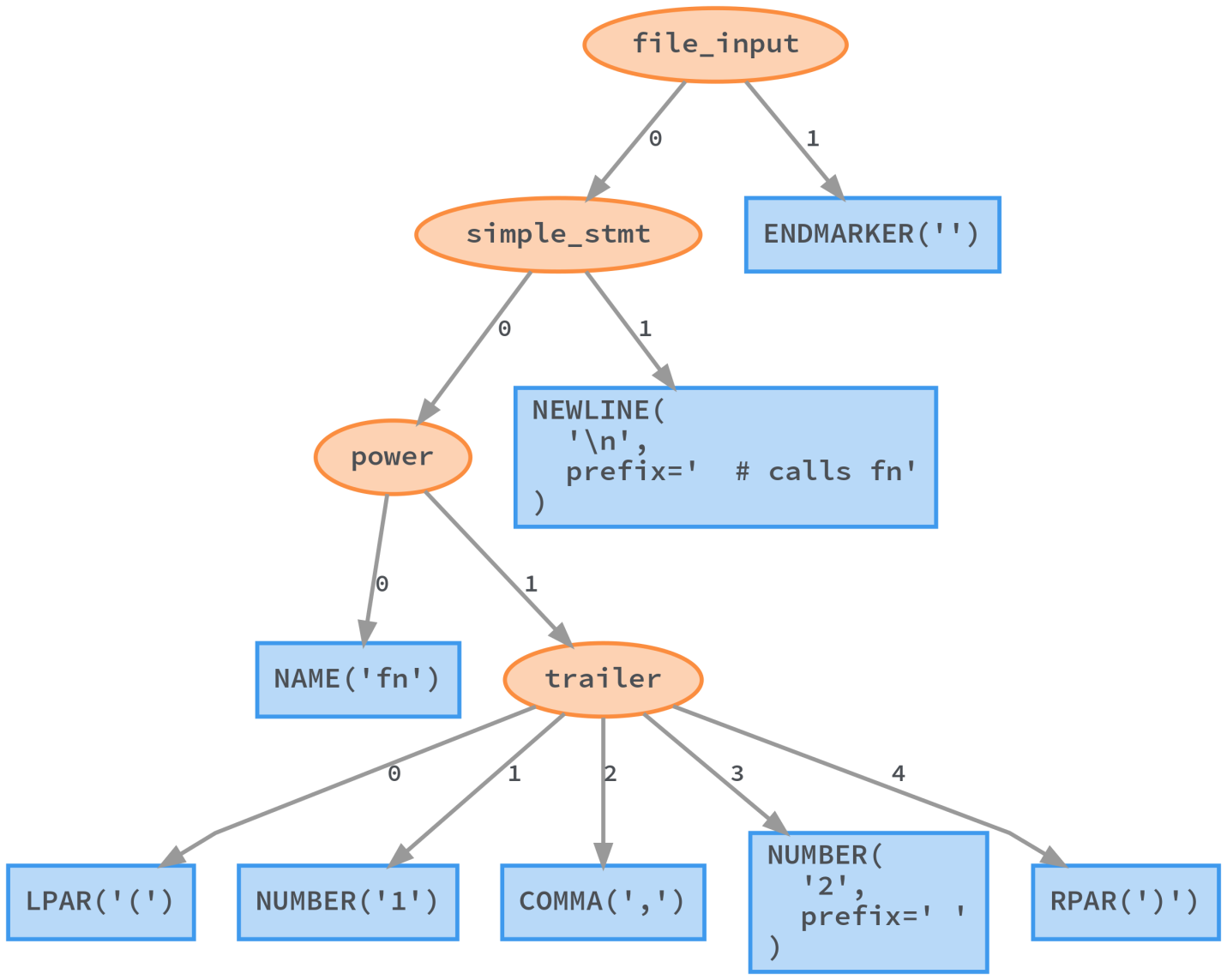
Связанные списки в Python
Связанные списки — это последовательный набор данных, который использует реляционные указатели на каждом узле данных для связи со следующим узлом в списке.
В отличие от массивов, связанные списки не имеют объективных позиций в списке. Вместо этого у них есть относительные позиции, основанные на их окружающих узлах.
Первый узел в связанном списке называется головным узлом, а последний — хвостовым узлом, который имеет nullуказатель.
![]()
Связанные списки могут быть односвязными или дважды связанными в зависимости от того, имеет ли каждый узел только один указатель на следующий узел или он также имеет второй указатель на предыдущий узел.
Вы можете думать о связанных списках как о цепочке; отдельные ссылки имеют связь только со своими ближайшими соседями, но все ссылки вместе образуют более крупную структуру.
Python не имеет встроенной реализации связанных списков и поэтому требует, чтобы вы реализовали Nodeкласс для хранения значения данных и одного или нескольких указателей.
Связанные списки в основном используются для создания расширенных структур данных, таких как графики и деревья, или для задач, требующих частого добавления / удаления элементов по всей структуре.
Преимущества:
- Эффективная вставка и удаление новых элементов.
- Проще реорганизовать, чем массивы.
- Полезно в качестве отправной точки для сложных структур данных, таких как графики или деревья.
Недостатки:
- Хранение указателей с каждой точкой данных увеличивает использование памяти.
- Всегда должен перемещаться по связанному списку от узла Head, чтобы найти определённый элемент.
Приложения:
- Строительный блок для расширенных структур данных.
- Решения, требующие частого добавления и удаления данных.
Общие вопросы собеседования по связному списку в Python
- Распечатать средний элемент данного связанного списка.
- Удалить повторяющиеся элементы из отсортированного связного списка.
- Проверьте, является ли односвязный список палиндромом.
- Объединить K отсортированных связанных списков.
- Найдите точку пересечения двух связанных списков.
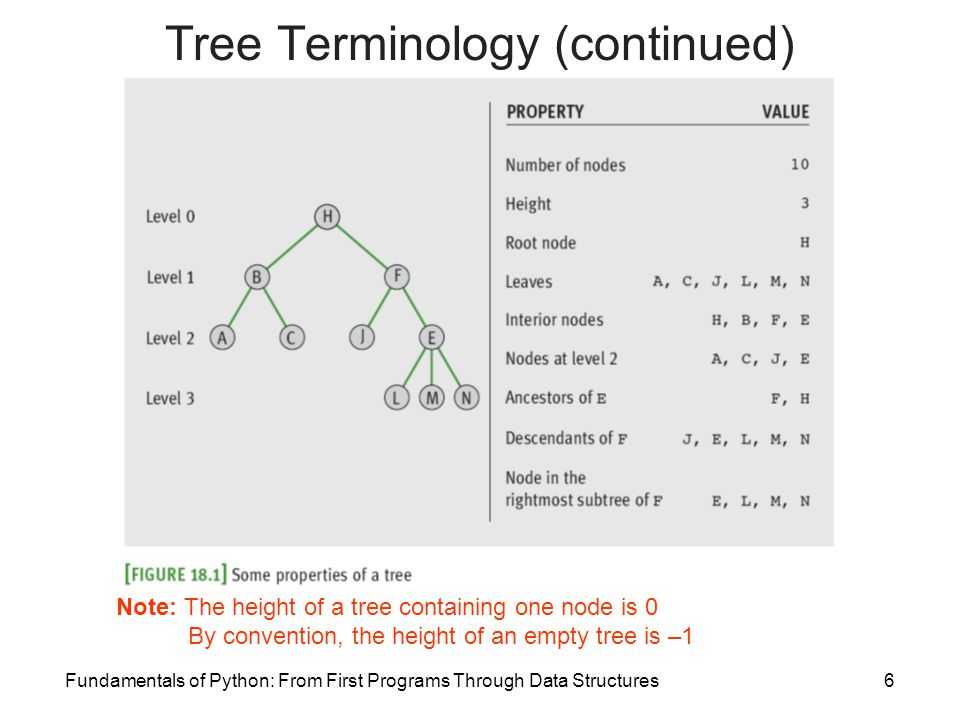
Как проверить, является ли бинарное дерево сбалансировано или нет?
Согласно определению высота левого поддерева и правого поддерева не должна превышать одного на любом узле.
Поэтому, если мы рассмотрим дерево, которое будет сбалансировано на любом узле, нам придется найти высоту его левого подделка и правого подмаревки.
Тогда мы проверим разницу в высотах. Если разница выйдет больше 1 на любом узле, мы объявим, что дерево не сбалансировано. Ниже приведен алгоритм для этой процедуры:
Algorithm CheckBalancedBinaryTree: Input: Root Node of the binary tree. Output:True if binary tree is balanced and False otherwise. Start. 0.If tree is empty, return True. 1. Check the height of left sub-tree. 2.Check the height of right sub-tree. 3.If difference in height is greater than 1 return False. 4.Check if left sub-tree is balanced. 5.Check if right sub-tree is balanced. 6. If left sub-tree is balanced and right sub-tree is also balanced, return True. End
Мы выяснили алгоритм для проверки, если бинарное дерево сбалансировано, но мы не знаем, как рассчитать высоту дерева и подделки. Таким образом, мы сначала реализуем программу, чтобы найти высоту дерева, если узел корневого узла, а затем мы реализуем вышеуказанный алгоритм.
расширения
В этом разделе перечислены расширения к этому учебнику, которые могут вас заинтересовать.
- Алгоритм настройки, Конфигурация, использованная в руководстве, была найдена с небольшими пробами и ошибками, но не была оптимизирована. Поэкспериментируйте с большим количеством деревьев, различным количеством функций и даже с различными конфигурациями деревьев, чтобы повысить производительность.
- Больше проблем, Примените эту технику к другим задачам классификации и даже адаптируйте ее для регрессии с помощью новой функции стоимости и нового метода для объединения прогнозов из деревьев.
DFS в Python
Дерево в коде мы представляем, используя список смежности через словарь Python. Для каждой вершины есть список смежных ей узлов.
graph = { 'A' : , 'B' : , 'C' : [], 'D' : [], 'E' : []}
Далее мы определяем отслеживание посещённых узлов через инструкцию .
Взяв за основу список смежности и начав с узла A, мы можем найти все узлы дерева, применяя рекурсивную функцию DFS. Алгоритм функции :
1. Проверяем, посещён ли текущий узел. Если да, то он добавляется в соответствующий набор.2. Функция повторно вызывается для каждого соседа узла.3. Базовый case вызывается, когда все узлы уже посещены, и после этого функция делает возврат.
def dfs(visited, graph, node): if node not in visited: print (node) visited.add(node) for neighbor in graph: dfs(visited, graph, neighbor)
Поиск в ширину (BFS)
В этом подходе мы выполняем поиск по всем узлам дерева, создавая широкую сеть. Это означает, что сначала мы обходим один уровень потомков и лишь затем переходим к последующему уровню уже их потомков.
Такой поиск сначала изучает ближайшие узлы и затем переходит всё дальше в сторону от исходной точки. С учётом этого мы хотим работать со структурой данных, которая при необходимости даёт самый старший элемент, считая их по порядку добавления. Здесь нам нужно применить механизм “очереди”.
![]()
Посмотрим, как очереди помогут нам с реализацией BFS и увидим работу BFS в бинарном дереве. Начиная от исходного узла A, мы продолжаем по порядку исследовать ветки, а именно переходим сначала к B, а затем к C, на котором текущий уровень завершается. После мы спускаемся на следующий уровень и посещаем D, откуда следуем к E.
Сначала мы инициализируем очередь и массив “visited”.
![]()
Начинаем с посещения корневого узла A.
![]()
Отмечаем A как посещённый и переходим к смежным с ним непосещённым узлам. В данном примере это два узла — B и C, и мы добавляем их в очередь, следуя алфавитному порядку.
![]()
Далее мы отмечаем B как посещённый и добавляем в очередь его потомков — D и E.
![]()
Теперь переходим к С, у которого нет непосещённых соседей.
![]()
Далее, спустившись на уровень вниз, мы посещаем сначала D, а потом E, также продолжая убирать каждый посещаемый узел из очереди. Программа завершится, когда в очереди не останется элементов.
![Визуализация дерева решений [matplotlib / graphviz] - русские блоги](https://fuzeservers.ru/wp-content/uploads/5/6/9/569bd29af054081fe7e69a59934d9da4.png)
![]()
![]()
Преимущества:
- Легко реализовать.
- Можно применять в любой задаче поиска.
- В отличие от DFS не подвержен проблеме бесконечного цикла, которая может вызвать сбой компьютера при выполнении углублённого DFS-поиска.
- Всегда находит кратчайший путь при условии равного веса ссылок, в связи с чем считается полноценным и более оптимальным способом поиска.
Недостатки:
- BFS требует больше памяти.
- BFS — это так называемый “слепой” поиск, охватывающий огромную область, из-за чего производительность будет уступать другим аналогичным эвристическим методам.
Scikit-Sulect 4-ступенчатый модель моделирования
# Step 1: Import the model you want to use
# This was already imported earlier in the notebook so commenting out
#from sklearn.tree import DecisionTreeClassifier
# Step 2: Make an instance of the Model
clf = DecisionTreeClassifier(max_depth = 2,
random_state = 0)
# Step 3: Train the model on the data
clf.fit(X_train, Y_train)
# Step 4: Predict labels of unseen (test) data
# Not doing this step in the tutorial
# clf.predict(X_test)
С помощью Scikit-Learn Version 21.0 (примерно в мае 2019 года), деревья решений теперь могут быть нанесены с помощью MATPLOTLIB, используя Scikit-Source Не полагаясь на точечную библиотеку, которая является трудно установленной зависимостью, которую мы будем охватывать позже в сообщении в блоге. Код ниже графики принимают решение, используя Scikit-Suart.
tree.plot_tree(clf);
В дополнение к добавлению кода, чтобы позволить вам сохранить свое изображение, код ниже пытается сделать дерево решений более интерпретируемо, добавив имена функций и классов (а также настройку).
fn=
cn=
fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (4,4), dpi=300)
tree.plot_tree(clf,
feature_names = fn,
class_names=cn,
filled = True);
fig.savefig('imagename.png')
Изображение выше – это решение TTE, производимый через графику. Graphviz – это программное обеспечение визуализации графика открытого исходного кода. Визуализация графика – это способ представления структурной информации как диаграммы абстрактных графов и сетей. В науке данных одно использование графики состоит в том, чтобы визуализировать деревья решений. Я должен отметить, что причина, по которой я иду через графики после покрытия Matplotlib, заключается в том, что для того, чтобы понять это на работу может быть сложно. Первая часть этого процесса включает создание точечного файла. DOT-файл – это графическое представление дерева решений. Проблема в том, что используя Graphviz для преобразования файла точек в файл изображения (PNG, JPG и т. Д.) Может быть сложно. Есть пара параметров, в том числе: Установка Python-Graphviz Hote AnaConda, установка Graphviz через домощь (MAC), установка исполняемых файлов Graphviz с официального сайта (Windows) и используя онлайн-конвертер на содержимое вашего точечного файла для преобразования это в изображение.
Что такое структуры данных?
Структуры данных — это структуры кода для хранения и организации данных, которые упрощают изменение, навигацию и доступ к информации. Структуры данных определяют способ сбора данных, функциональные возможности, которые мы можем реализовать, и отношения между данными.
Структуры данных используются практически во всех областях информатики и программирования, от операционных систем до интерфейсной разработки и машинного обучения.
Структуры данных помогают:
- Управляйте большими наборами данных и используйте их.
- Быстрый поиск определённых данных в базе данных.
- Создавайте чёткие иерархические или реляционные связи между точками данных.
- Упростите и ускорьте обработку данных.
Структуры данных являются жизненно важными строительными блоками для эффективного решения реальных проблем. Структуры данных — это проверенные и оптимизированные инструменты, которые дают вам удобную основу для организации ваших программ. В конце концов, вам не нужно переделывать колесо (или конструкцию) каждый раз, когда это нужно.
У каждой структуры данных есть задача или ситуация, для решения которой она наиболее подходит. Python имеет 4 встроенных структуры данных, списки, словари, кортежи и наборы. Эти встроенные структуры данных поставляются с методами по умолчанию и негласной оптимизацией, которая упрощает их использование.
Большинство структур данных в Python являются их модифицированными формами или используют встроенные структуры в качестве основы.
- Список: структуры, похожие на массивы, которые позволяют сохранять набор изменяемых объектов одного и того же типа в переменную.
- Кортеж: кортежи — это неизменяемые списки, то есть элементы не могут быть изменены. Он объявлен в круглых скобках вместо квадратных.
- Набор: наборы — это неупорядоченные коллекции, что означает, что элементы неиндексированы и не имеют установленной последовательности. Они объявляются фигурными скобками.
- Словарь (dict): Подобно хэш-карте или хеш-таблицам на других языках, словарь представляет собой набор пар ключ / значение. Вы инициализируете пустой словарь пустыми фигурными скобками и заполняете его ключами и значениями, разделёнными двоеточиями. Все ключи — уникальные неизменяемые объекты.
Теперь давайте посмотрим, как мы можем использовать эти структуры для создания всех сложных структур, которые ищут интервьюеры.
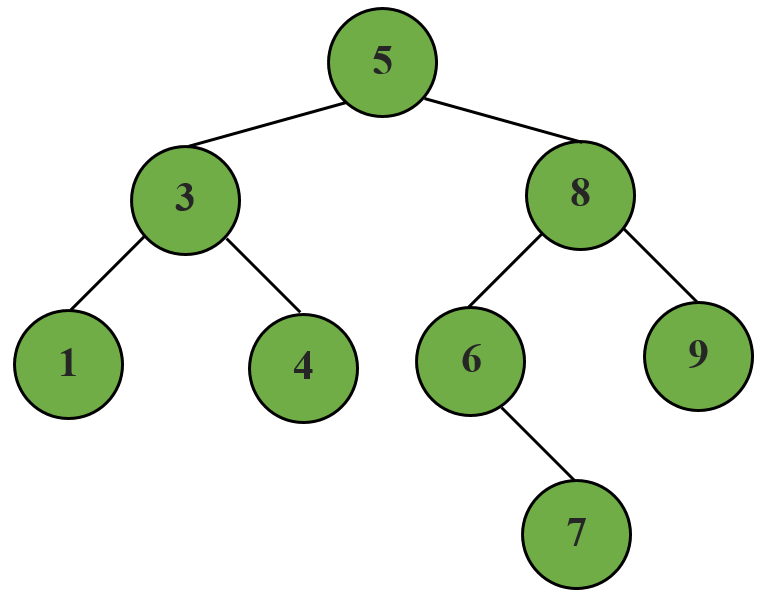
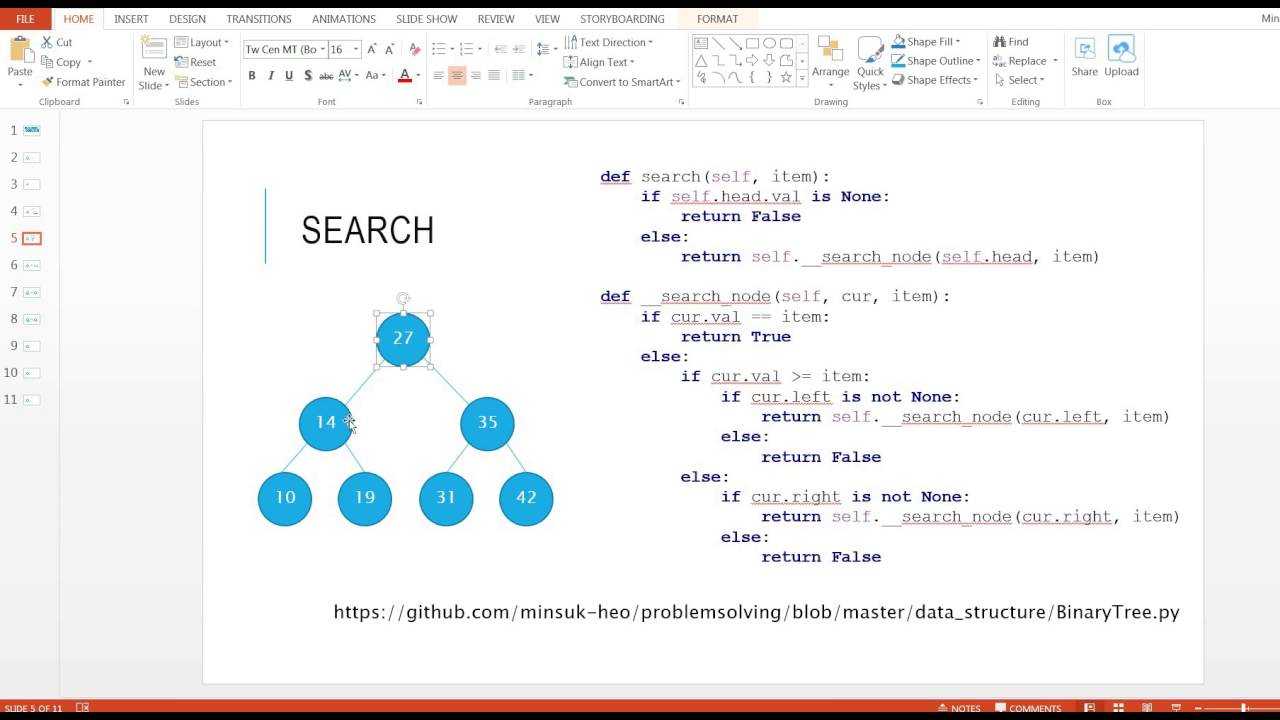
Основные терминологии в бинарных деревьях
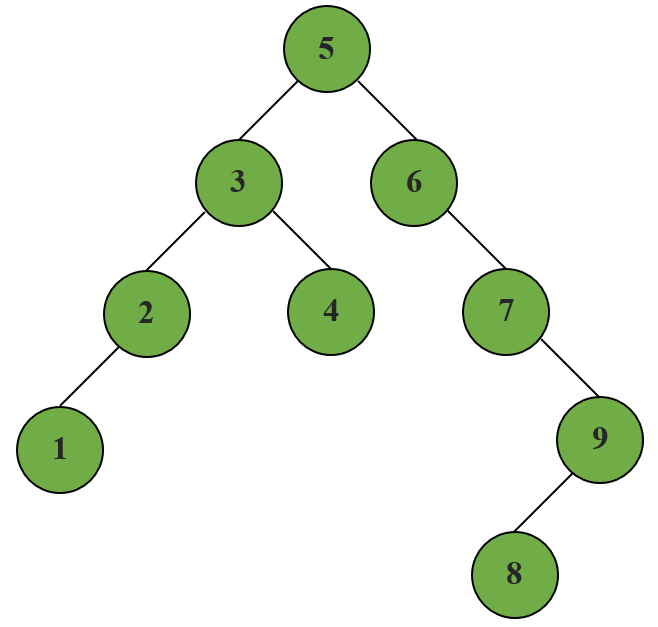
Теперь мы возьмем пример бинарного дерева и посмотрите на терминологии, связанные с ним. Предположим, нам дали ниже двоичное дерево.
- Корневой узел : Самый верхний узел бинарного дерева называется его корневым узлом. Это первый узел, созданный во время создания дерева. В приведенном выше примере 10 является корневым узлом.
- Родительский узел : Родитель узла – это узел, чей левой ссылкой или правой ссылкой указывает на текущий узел. Например, 10 является родительским узлом 15.
- Детский узел : Узел, на котором указывается родительский узел, называется его дочерним узлом. Здесь 15 – детский узел 10.
- Край : Край – это ссылка, соединяющая любые два узла в дереве.
- Внутренние узлы: внутренние узлы – это узлы, которые имеют по крайней мере один ребенок. В нашем примере узлы, содержащие данные 10,15 и 20, являются внутренними узлами.
- Узел листьев или внешние узлы : Это узлы в бинарном дереве, которые не имеют детей. Их как левый, так и правый, относящийся к Нет Отказ В приведенном выше примере узлы с данными 60, 14, 25 и 6 являются узлами листа или внешние узлы.
Реализация бинарного дерева в Python
Теперь мы постараемся реализовать двоичное дерево, приведенное в приведенном выше примере в следующем коде:
class BinaryTreeNode:
def __init__(self, data):
self.data = data
self.leftChild = None
self.rightChild = None
a1=BinaryTreeNode(10)
a2=BinaryTreeNode(15)
a3=BinaryTreeNode(20)
a4=BinaryTreeNode(60)
a5=BinaryTreeNode(14)
a6=BinaryTreeNode(25)
a7=BinaryTreeNode(6)
a1.leftChild=a2
a1.rightChild=a3
a2.leftChild=a4
a2.rightChild=a5
a3.leftChild=a6
a3.rightChild=a7
print("Root Node is:")
print(a1.data)
print("left child of node is:")
print(a1.leftChild.data)
print("right child of node is:")
print(a1.rightChild.data)
print("Node is:")
print(a2.data)
print("left child of node is:")
print(a2.leftChild.data)
print("right child of node is:")
print(a2.rightChild.data)
print("Node is:")
print(a3.data)
print("left child of node is:")
print(a3.leftChild.data)
print("right child of node is:")
print(a3.rightChild.data)
print("Node is:")
print(a4.data)
print("left child of node is:")
print(a4.leftChild)
print("right child of node is:")
print(a4.rightChild)
print("Node is:")
print(a5.data)
print("left child of node is:")
print(a5.leftChild)
print("right child of node is:")
print(a5.rightChild)
print("Node is:")
print(a6.data)
print("left child of node is:")
print(a6.leftChild)
print("right child of node is:")
print(a6.rightChild)
print("Node is:")
print(a7.data)
print("left child of node is:")
print(a7.leftChild)
print("right child of node is:")
print(a7.rightChild)
Выход:
Root Node is: 10 left child of node is: 15 right child of node is: 20 Node is: 15 left child of node is: 60 right child of node is: 14 Node is: 20 left child of node is: 25 right child of node is: 6 Node is: 60 left child of node is: None right child of node is: None Node is: 14 left child of node is: None right child of node is: None Node is: 25 left child of node is: None right child of node is: None Node is: 6 left child of node is: None right child of node is: None
Как вы можете видеть, в вышеуказанном коде мы впервые создали объекты Класс, определенный в примере. Затем мы присваиваем корню дерева, а затем мы добавили детей в корневой узел и так далее. Затем мы напечатали данные в каждом узле и данные в своем детском узле.
Установка и использование графики
Преобразование точечного файла в файл изображения (PNG, JPG и т. Д.) Обычно требуется установка Graphviz, которая зависит от вашей операционной системы и множества других вещей. Цель этого раздела – помочь людям попробовать и решать общую проблему получения следующей ошибки. DOT: команда не найдена.
Как установить и использовать на Mac через AnaConda
Чтобы иметь возможность установить Graphviz на ваш Mac через этот метод, сначала необходимо установить AnaConda (если у вас нет установленной AnaConda, вы можете узнать, как установить его здесь ). Откройте терминал. Вы можете сделать это, нажав на лупу Spotlight в верхней правой правой части экрана, введите терминал, а затем нажмите на значок терминала. Введите команду ниже для установки Graphviz.
conda install python-graphviz
После этого вы должны быть в состоянии использовать команду DOT ниже, чтобы преобразовать файл DOT в файл PNG.
dot -Tpng tree.dot -o tree.png
Как установить и использовать на Mac через доморь
Если у вас нет AnaConda или просто хотите еще один способ установки графики на ваш Mac, вы можете использовать Домашний вид Отказ Ранее я написал статью о том, как установить домощь и использовать его, чтобы преобразовать точечный файл в файл изображения здесь (См. Длительность, чтобы помочь визуализировать раздел деревьев принятия решений учебника).
Как установить и использовать на Windows через AnaConda
Это метод, который я предпочитаю на Windows. Чтобы иметь возможность установить Graphviz на Windows через этот метод, сначала нужно установить AnaConda (если у вас нет установленной AnaConda, вы можете узнать, как установить его здесь ). Откройте клемму/командную строку и введите команду ниже, чтобы установить Graphviz.
conda install python-graphviz
После этого вы должны быть в состоянии использовать команду DOT ниже, чтобы преобразовать файл DOT в файл PNG.
dot -Tpng tree.dot -o tree.png
Как установить и использовать на Windows через исполняемый файл Graphviz
Если у вас нет AnaConda или просто хотите, чтобы другой способ установки Graphviz на ваших окнах вы можете использовать следующую ссылку для загрузки и установки его. Если вы не знакомы с изменением переменной пути и хотите использовать точку в командной строке, я поощряю другие подходы. Есть Многие вопросы Stackoverflow на основе этой конкретной проблемы Отказ
Как использовать онлайн-конвертер для визуализации деревьев принятия решений
Если все остальное не удается или вы просто не хотите ничего устанавливать, вы можете использовать Онлайн конвертер Отказ На рисунке ниже я открыл файл с Sublime Text (хотя есть много разных программ, которые могут открывать/прочитать точечный файл) и скопировали содержимое файла. На рисунке ниже я вставил содержимое из файла DOT на левую сторону онлайн-конвертера. Затем вы можете выбрать, какой формат вы хотите, а затем сохраните изображение на правой стороне экрана. Имейте в виду, что есть Другие онлайн-преобразователи Это может помочь осуществить ту же задачу.
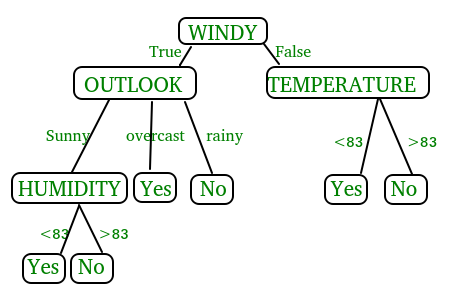
Слабость деревьев решений состоит в том, что они не склонны к лучшей прогностической точности. Это частично из-за высокой дисперсии, что означает, что разные расщепления в учебных данных могут привести к очень разным деревьям. Изображение выше может быть схемой для пакетированных деревьев или случайных моделей лесов, которые являются методами ансамблевых. Это означает использование нескольких алгоритмов обучения для получения лучшей прогностической производительности, чем можно получить только из любого из любых составляющих алгоритмов обучения. В этом случае многие деревья защищают друг друга от своих отдельных ошибок
Насколько именно пакетированные деревья и произвольные лесные модели работают – это предмет для другого блога, но то, что важно отметить, что для каждой обе модели мы выращиваем n деревьев, где n – количество решений, которые указывают пользователя. Следовательно, после того, как вы подходите модель, было бы неплохо посмотреть на отдельные деревья решений, которые составляют вашу модель
Описание
В этом разделе приводится краткое введение в алгоритм Random Forest и набор данных Sonar, используемые в этом руководстве.
Алгоритм случайного леса
Деревья решений включают жадный выбор наилучшей точки разделения из набора данных на каждом шаге.
Этот алгоритм делает деревья решений восприимчивыми к высокой дисперсии, если они не сокращены. Эта высокая дисперсия может быть использована и уменьшена путем создания нескольких деревьев с разными выборками обучающего набора данных (разные взгляды на проблему) и объединения их прогнозов. Этот подход называется агрегацией начальной загрузки или сокращением для краткости.
Ограничение мешков заключается в том, что для создания каждого дерева используется один и тот же жадный алгоритм, а это означает, что вполне вероятно, что в каждом дереве будут выбраны одинаковые или очень похожие точки разделения, что делает разные деревья очень похожими (деревья будут коррелироваться). Это, в свою очередь, делает их прогнозы схожими, смягчая изначально искомую дисперсию.
Мы можем заставить деревья решений быть разными, ограничивая возможности (строки), которые жадный алгоритм может оценивать в каждой точке разделения при создании дерева. Это называется алгоритм случайного леса.
Как и в случае с мешками, берутся несколько образцов обучающего набора данных и тренируют разные деревья на каждом. Разница заключается в том, что в каждой точке выполняется разделение данных и добавление в дерево, можно рассматривать только фиксированное подмножество атрибутов.
Для задач классификации, типа проблем, которые мы рассмотрим в этом уроке, количество атрибутов, которые необходимо учитывать для разделения, ограничено квадратным корнем из числа входных объектов.
Результатом этого небольшого изменения являются деревья, которые более отличаются друг от друга (некоррелированные), в результате чего прогнозы являются более разнообразными, а комбинированные прогнозы часто имеют лучшую производительность, чем одиночное дерево или отдельные пакеты.
Сонар Набор данных
Набор данных, который мы будем использовать в этом уроке, — это набор данных Sonar.
Это набор данных, который описывает возврат эхолота, отражающийся от разных поверхностей. 60 входных переменных — это сила отдачи под разными углами. Это проблема бинарной классификации, которая требует модели для дифференциации горных пород от металлических цилиндров. Есть 208 наблюдений.
Это хорошо понятный набор данных. Все переменные являются непрерывными и обычно находятся в диапазоне от 0 до 1. Выходной переменной является строка «M» для моего и «R» для камня, которую необходимо преобразовать в целые числа 1 и 0.
Прогнозируя класс с наибольшим количеством наблюдений в наборе данных (M или мин), алгоритм нулевого правила может достичь точности 53%.
Вы можете узнать больше об этом наборе данных наUCI хранилище машинного обучения,
Загрузите набор данных бесплатно и поместите его в свой рабочий каталог с именем файлаsonar.all-data.csv,
Измерение производительности модели
Хотя существуют и другие способы измерения производительности модели (точность, отзыв, оценка F1,РПЦ Криваяи т. д.), мы будем придерживаться этого простого и использовать точность в качестве нашей метрики
Точность определяется как:
(доля правильных прогнозов): правильные прогнозы / общее количество точек данных
# The score method returns the accuracy of the modelscore = clf.score(X_test, Y_test)print(score)
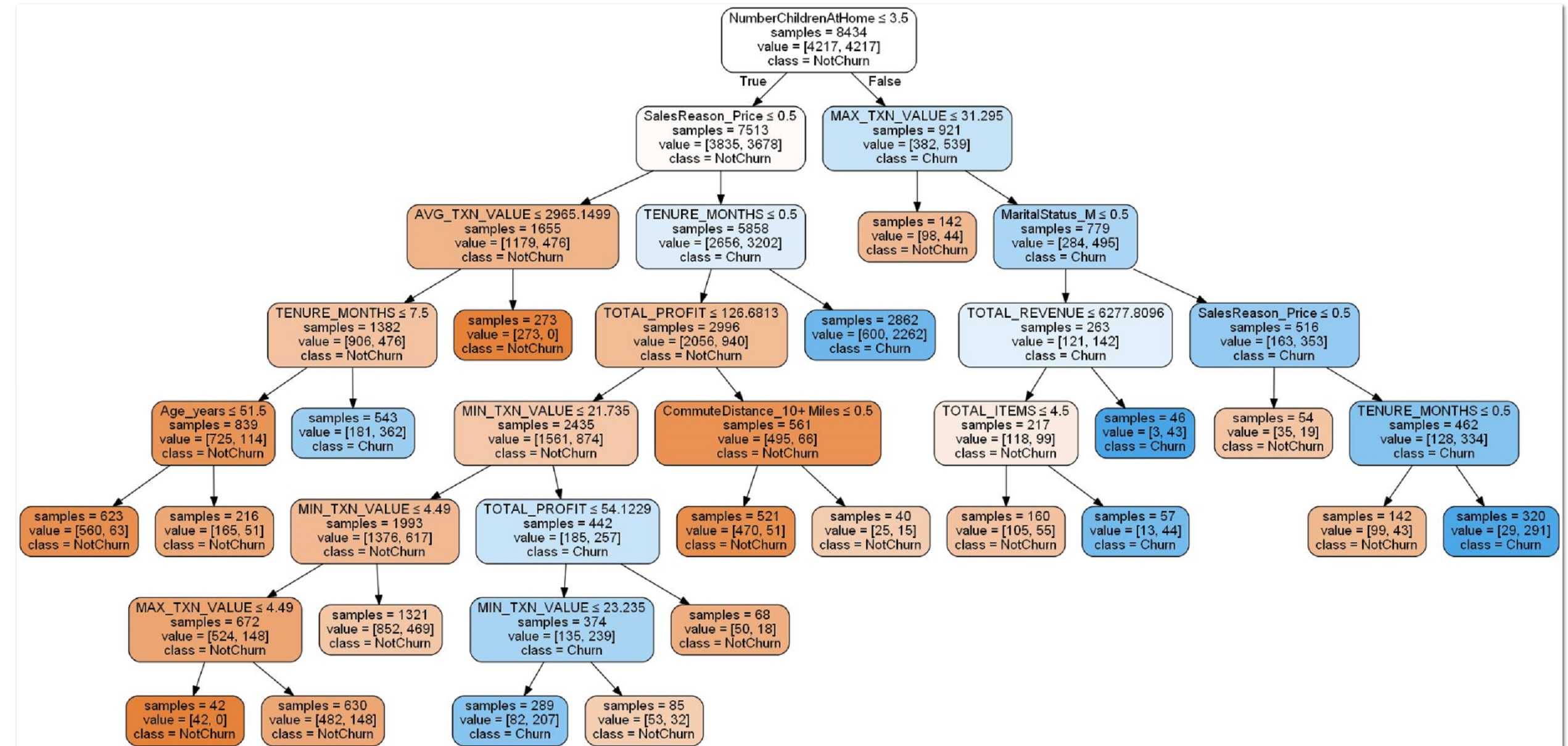
Настройка глубины дерева
Нахождение оптимального значения дляэто один из способов настройки вашей модели. Приведенный ниже код выводит точность для деревьев решений с различными значениями для,
# List of values to try for max_depth:max_depth_range = list(range(1, 6))# List to store the average RMSE for each value of max_depth:accuracy = []for depth in max_depth_range: clf = DecisionTreeClassifier(max_depth = depth, random_state = 0) clf.fit(X_train, Y_train) score = clf.score(X_test, Y_test) accuracy.append(score)
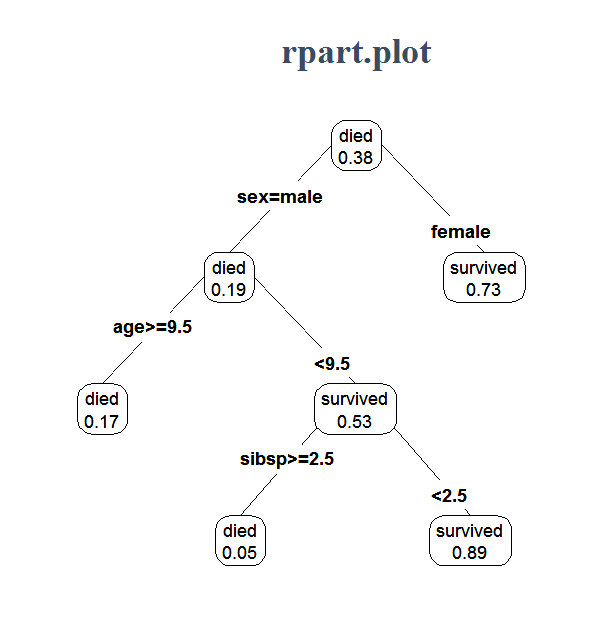
Поскольку график ниже показывает, что наилучшая точность для модели — это когда параметрбольше или равно 3, может быть лучше выбрать наименее сложную модель с,
Я выбираю max_depth = 3, так как он кажется точной и не самой сложной моделью.
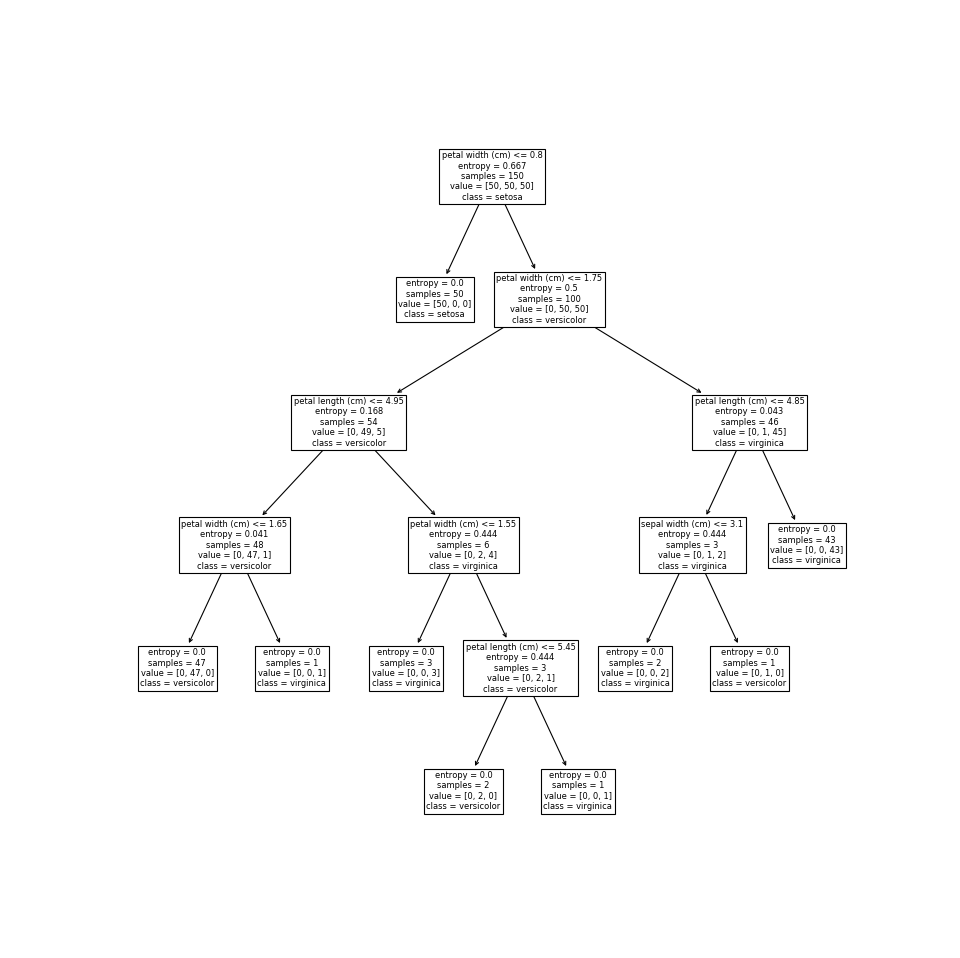
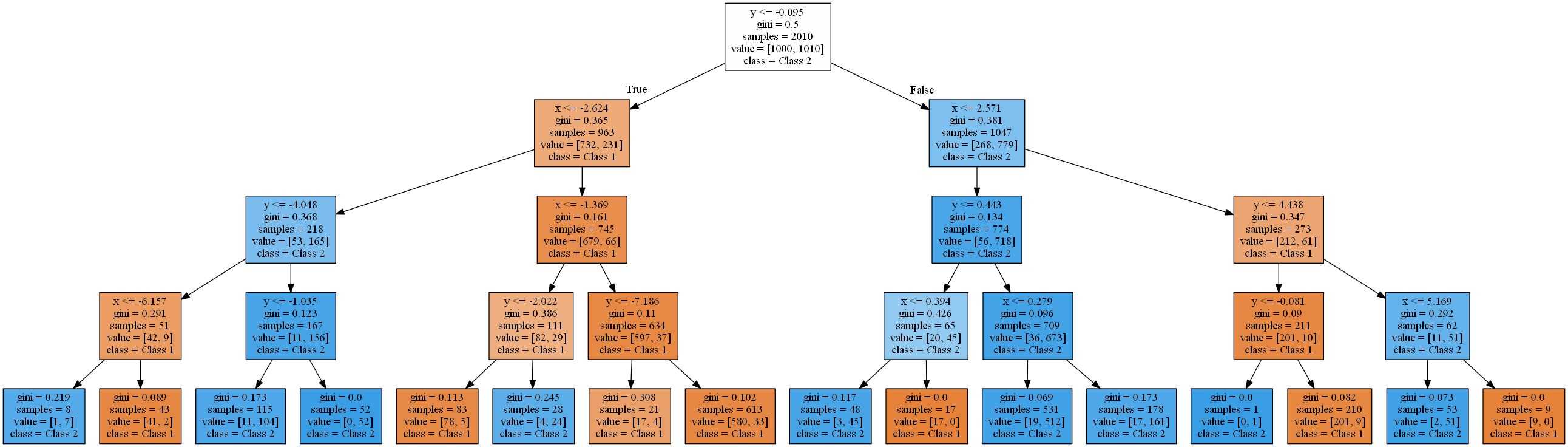
Важно помнить, чтоэто не то же самое, что глубина дерева решений.способ предопределить дерево решений Другими словами, если дерево уже настолько чистое, насколько это возможно на глубине, оно не будет продолжать расщепляться. На рисунке ниже показаны деревья решений сзначения 3, 4 и 5
Обратите внимание, что деревья сиз 4 и 5 идентичны. Они оба имеют глубину 4
Обратите внимание, что у нас есть два одинаковых дерева. Если вы когда-нибудь задумывались, какова глубина вашего обученного дерева решений, вы можете использоватьметод
Кроме того, вы можете получить число конечных узлов для обученного дерева решений, используяметод
Если вы когда-нибудь задумывались, какова глубина вашего обученного дерева решений, вы можете использоватьметод. Кроме того, вы можете получить число конечных узлов для обученного дерева решений, используяметод.
В то время как этот учебник охватывал изменение критерия выбора (индекс Джини, энтропия и т. Д.) Идерева, имейте в виду, что вы также можете настроить минимальные выборки для узла для разделения (), максимальное количество листовых узлов (), и больше.
Важность функции
Одним из преимуществ классификационных деревьев является то, что их относительно легко интерпретировать
Деревья классификации в scikit-learn позволяют вычислить важность функции, которая представляет собой общую величину, которую индекс Джини или энтропия уменьшают из-за разделения на данную функцию. Scikit-learn выводит число от 0 до 1 для каждой функции
Все значения функций нормализованы для суммирования до 1. В приведенном ниже коде показаны значения функций для каждого объекта в модели дерева решений.
importances = pd.DataFrame({'feature':X_train.columns,'importance':np.round(clf.feature_importances_,3)})importances = importances.sort_values('importance',ascending=False)
![]()
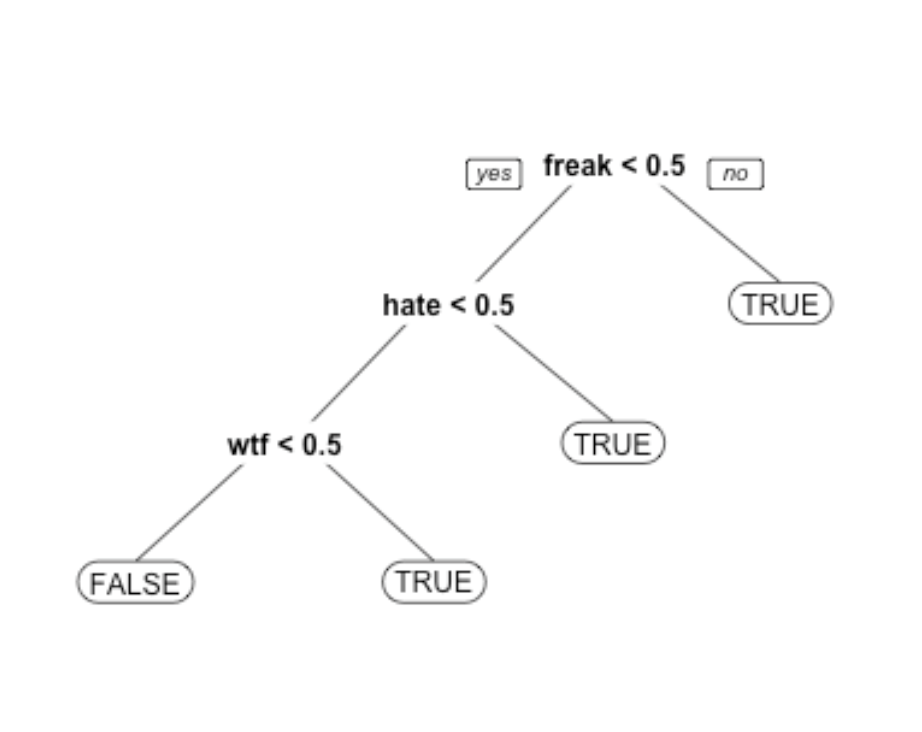
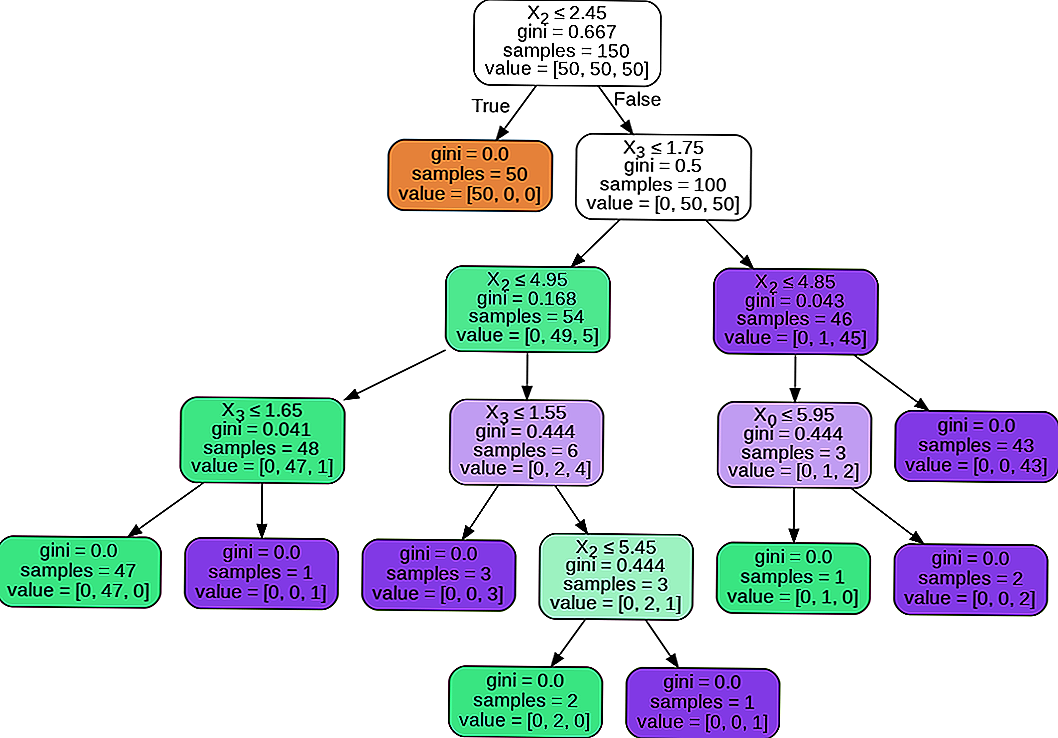
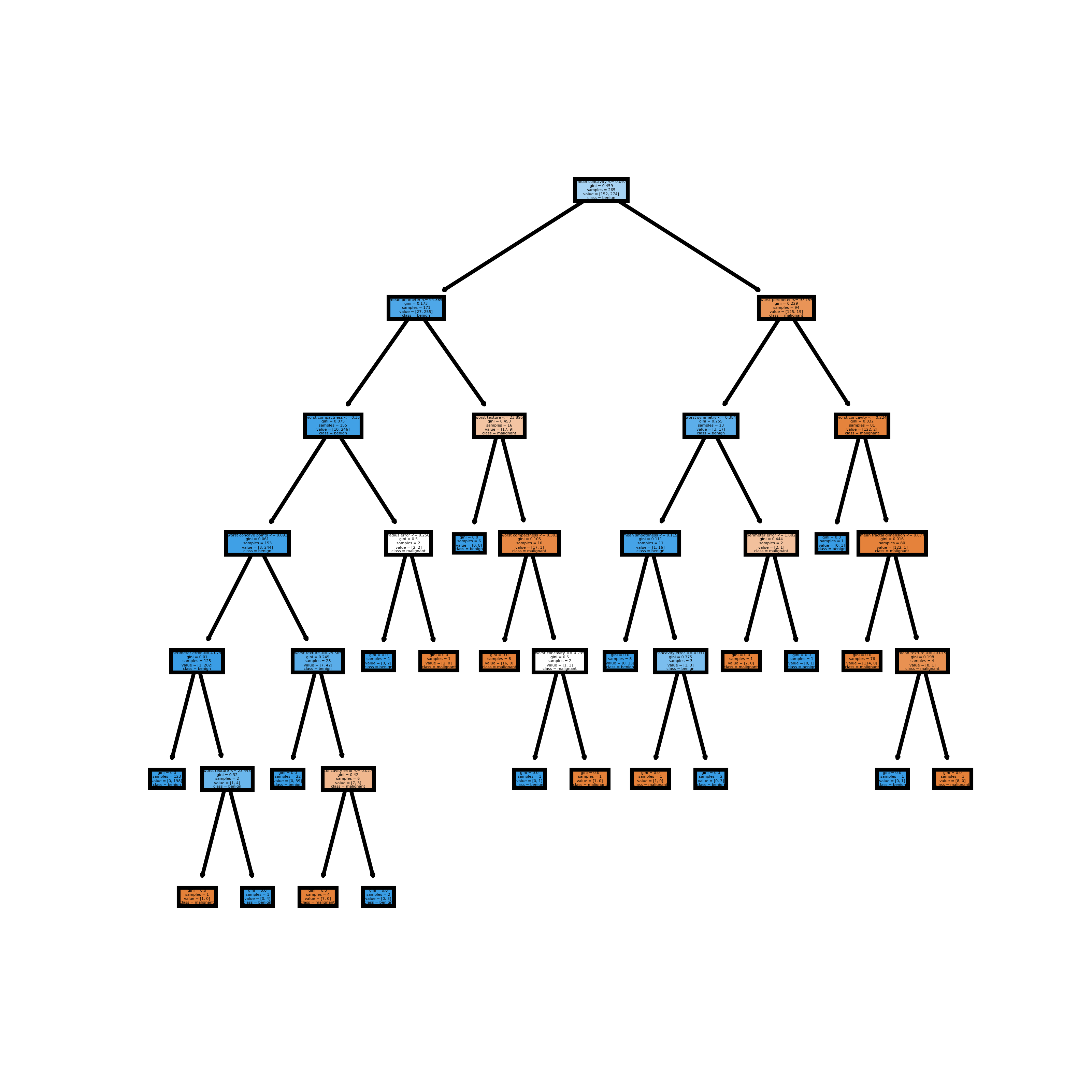
В приведенном выше примере (для конкретного теста на разделение радужной оболочки) ширина лепестка имеет наивысший весовой коэффициент важности. Мы можем подтвердить, посмотрев на соответствующее дерево решений
Единственное, что разделяет это дерево решений — это ширина лепестка (см) и длина лепестка (см),
Имейте в виду, что если функция имеет низкое значение важности функции, это не обязательно означает, что функция не важна для прогнозирования, это просто означает, что конкретная функция не была выбрана на особенно раннем уровне дерева. Также может быть, что функция может быть идентичной или сильно коррелированной с другой информативной функцией
Значения важности объектов также не говорят о том, для какого класса они являются очень прогнозирующими, или о взаимосвязях между функциями, которые могут повлиять на прогноз. Важно отметить, что при выполнении перекрестной проверки или аналогичной функции вы можете использовать среднее значение важности функций из нескольких разделений теста поезда.





