
Сбор данных
Наука о данных включает в себя обработку данных, чтобы данные могли хорошо работать с алгоритмами данных. Data Wrangling – это процесс обработки данных, такой как слияние, группировка и конкатенация.
Библиотека Pandas предоставляет полезные функции, такие как merge(), groupby() и concat() для поддержки задач Data Wrangling.
import pandas as pd
d = {
'Employee_id': ,
'Employee_name':
}
df1 = pd.DataFrame(d, columns=)
print(df1)
![]()
import pandas as pd
data = {
'Employee_id': ,
'Employee_name':
}
df2 = pd.DataFrame(data, columns=)
print(df2)
а. merge()
print(pd.merge(df1, df2, on='Employee_id'))
![]()
Мы видим, что функция merge() возвращает строки из обоих DataFrames, имеющих то же значение столбца, которое использовалось при слиянии.
b. Группировка
import pandas as pd import numpy as np data = { 'Employee_id': , 'Employee_name': } df2 = pd.DataFrame(data) group = df2.groupby('Employee_name') print(group.get_group('Meera'))
Поле «Employee_name» со значением «Meera» сгруппировано по столбцу «Employee_name». Пример вывода приведен ниже:
Python 2.7 (функциональная реализация)
def merge(right, left, result):
result.append((left if left < right else right).pop(0))
return merge(right=right, left=left, result=result) if left and right else result+left+right
merge_sort = (lambda arr: arr if len(arr) == 1 else merge(merge_sort(arr[len(arr)/2:]),
merge_sort(arr[:len(arr)/2]), []))
Недостатком сортировки слиянием является использование дополнительной памяти. Но когда работать приходиться с файлами или списками, доступ к которым осуществляется только последовательно, то очень удобно применять именно этот метод. Также, к достоинствам алгоритма стоит отнести его устойчивость и неплохую скорость работы O(n*logn).
При написании статьи были использованы открытые источники сети интернет :
Youtube
Скорость сортировки в Python
Python
# speed/main.py
import random
from boxx import timeit
def list_sort(arr):
return arr.sort()
def sorted_builtin(arr):
return sorted(arr)
def main():
arr =
with timeit(name=»sorted(list)»):
sorted_builtin(arr)
with timeit(name=»list.sort()»):
list_sort(arr)
if __name__ == «__main__»:
main()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# speed/main.py importrandom fromboxx importtimeit deflist_sort(arr) returnarr.sort() defsorted_builtin(arr) returnsorted(arr) defmain() arr=random.randint(,50)forrinrange(1_000_000) withtimeit(name=»sorted(list)») sorted_builtin(arr) withtimeit(name=»list.sort()») list_sort(arr) if__name__==»__main__» main() |
Указанный выше код выводит следующий результат:
Shell
$ python main.py
«sorted(list)» spend time: 0.1104379
«list.sort()» spend time: 0.0956471
|
1 2 3 |
$python main.py «sorted(list)»spend time0.1104379 «list.sort()»spend time0.0956471 |
Как видите, метод немного быстрее, чем функция . Почему так получается? Разберем обе функции и посмотрим, сможет ли байтовый код дать ответ:
Python
>>> import dis
>>> dis.dis(list_sort)
12 0 LOAD_FAST 0 (arr)
2 LOAD_METHOD 0 (sort)
4 CALL_METHOD 0
6 RETURN_VALUE
>>> dis.dis(sorted_builtin)
16 0 LOAD_GLOBAL 0 (sorted)
2 LOAD_FAST 0 (arr)
4 CALL_FUNCTION 1
6 RETURN_VALUE
|
1 2 3 4 5 6 7 8 9 10 11 |
>>>importdis >>>dis.dis(list_sort) 12LOAD_FAST(arr) 2LOAD_METHOD(sort) 4CALL_METHOD 6RETURN_VALUE >>>dis.dis(sorted_builtin) 16LOAD_GLOBAL(sorted) 2LOAD_FAST(arr) 4CALL_FUNCTION1 6RETURN_VALUE |
Байтовый код обеих функций практически идентичен. Единственное различие в том, что функция сначала загружает список, и за методом (sort) следует вызванный метод списка без аргументов. Если сравнить, функция сначала загружает встроенную функцию , а за ней следует список и вызов загруженной функции со списком в качестве аргумента.
Почему же временные результаты отличаются?
Можно предположить, что в то время как может работать с известным размером и менять элементы внутри данного размера, должен работать c неизвестным размером. Следовательно, если при добавлении нового элемента не хватает памяти, нужно изменить размер нового списка, созданного через . На это требуется время! Если просмотреть исходный код CPython, можно найти следующий комментарий об изменении размера списка объектов:
Помните, что сейчас мы работаем со списком из 1 000 000 элементов — изменений размера будет довольно много! К несчастью, пока что это лучший ответ на вопрос, почему на 13% быстрее, чем .
Python
new_array = arr.copy()
arr.sort()
|
1 2 |
new_array=arr.copy() arr.sort() |
Имплементация приводит к разнице во времени выполнения, поскольку создание копии списка занимает некоторое время.
Что такое Группировка?
Группировка базы данных/фрейма данных является обычной практикой в повседневном анализе и очистке данных. Группировка означает объединение идентичных данных (или данных, имеющих одинаковые свойства) в разные группы.
Например : Представьте себе школьную базу данных, в которой есть ученики всех классов. Теперь, если директор хочет сравнить результаты/посещаемость между классами, ему нужно сравнить средние данные по каждому классу. Но как он может это сделать? Он группирует данные учащихся в зависимости от того, к какому классу они принадлежат (учащиеся одного класса входят в одну группу), а затем усредняет данные по каждому учащемуся в группе.
Наш пример охватывает очень идеальную ситуацию, но это самое основное применение группировки. Группировка может основываться на нескольких свойствах. Это иногда называют иерархической группировкой, когда группа далее подразделяется на более мелкие группы на основе какого-либо другого свойства данных. Это позволяет нашим запросам быть настолько сложными, насколько нам требуется.
Существует также очень простая проблема, которую мы проигнорировали в нашем примере: все данные в базе данных не нужно усреднять. Например, если нам нужно сравнить только среднюю посещаемость и процент каждого класса, мы можем игнорировать другие значения, такие как номер мобильного телефона или номер рулона, среднее значение которых действительно не имеет смысла. В этой статье мы узнаем, как создавать такие сложные команды группировки в панд.
Как вставить данные в DataFrame
Когда у нас уже создан DataFrame со своими столбцами, нам остается только добавить в него данные. Существует несколько способов сделать это. Давайте посмотрим на некоторые из них.
Предположим, что у нас есть данные, которые нужно вставить в списки, то есть список для каждого столбца со значениями каждой строки для этого столбца. Мы можем сделать простое отображение следующим образом:
Результат этой операции будет следующим:
Будьте осторожны! Если вы присваиваете значения DataFrame таким образом, все списки должны иметь одинаковую длину.
Обратите внимание, что если вы присваиваете значения таким образом, вам не нужно предварительно создавать столбцы, так как присвоение само создает столбец, если он не был определен. Обратите внимание, что таким же образом вы можете смешивать старые значения с новыми, если колонка уже существует
Когда у нас есть некоторые значения, мы можем добавить новые значения, вставляя полные строки. Это полезно, как я уже говорил, чтобы иметь возможность вставлять значения постепенно, по мере их получения или генерации. Для этого можно воспользоваться функцией append объектов DataFrame, которая добавляет строку в конец таблицы.
Вы можете предоставить этой функции объект типа Series of pandas, который представляет собой список значений, или объект типа dictionary, где каждое значение соответствует имени столбца в таблице в качестве ключа. Рассмотрим оба способа на одном примере:
Обратите внимание на несколько моментов:
- Функция append возвращает новый объект с новыми значениями, поэтому мы должны выполнить присваивание df = df.append(…).
- Мы должны указать параметр ignore_index, установленный в False в функции append, чтобы она не учитывала индексы новых данных, которые могли бы быть указаны (хотя в данном случае они этого не делают). Помните, что мы можем добавить данные из другого DataFrame, у которого есть индексы.
- При создании объекта Series, помимо новых данных, необходимо указать столбцы (в том же порядке, что и данные). Для этого я использую параметр index и атрибут columns фрейма DataFrame, чтобы не писать их вручную.
Результатом приведенного выше кода является:
Вы можете добавить сразу несколько строк, предоставив функции append список словарей или Series, по одному на строку. Это будет более эффективно, чем несколько вызовов функции, по одному вызову на строку.
Подобно столбцам, строки тоже могут иметь имя. Каждый ряд может иметь собственное название или метку. Вы можете представить себе еженедельный календарь, в котором каждая строка представляет собой день недели. Таким образом, мы можем обозначить каждый ряд названиями “понедельник”, “вторник”, “среда” и так далее.
Это делает очень удобным доступ к определенным строкам без необходимости знать их положение в таблице. Создадим DataFrame для хранения, например, лекарств, которые человек должен принимать утром, днем и вечером для каждого дня недели.
Другим способом добавления данных является использование атрибута loc фрейма DataFrame. loc позволяет получить доступ к определенной строке (или нескольким строкам) через ее имя.
Рассмотрим пример:
Преимущество этой формы в том, что нам не нужно указывать имена столбцов для каждого значения. Однако необходимо указывать значения в соответствующем порядке. Результат получается следующим:
Обратите внимание, что во вторник во второй половине дня лекарств нет. В этом случае я могу указать значение None
Это имена меток или строк, являющиеся набором индексов, которые print(df) намеревался вывести на экран, когда DataFrame был пуст.
Обратите внимание, что loc переписывает существующую строку в том случае, если указанный индекс уже существует в таблице. Конечно, существует еще много способов вставки данных, но рассмотрение всех этих способов не является целью данной статьи, мы рассматриваем различные способы создания DataFrame
Теперь, когда мы увидели, как создать пустой и как создать еще один из значений столбцов, давайте рассмотрим другие способы
Конечно, существует еще много способов вставки данных, но рассмотрение всех этих способов не является целью данной статьи, мы рассматриваем различные способы создания DataFrame. Теперь, когда мы увидели, как создать пустой и как создать еще один из значений столбцов, давайте рассмотрим другие способы.
Сортировка List в языке C#
Для того, чтобы произвести сортировку списка List, элементами которого являются ссылочные типы данных, сначала необходимо написать метод, описывающий сравнение двух таких “сложных” элементов списка.
Данный метод называется Compare и он должен находиться в отдельно созданном классе, реализующем интерфейс IComparer<>.
Первый пример сортировки списка
Сначала выполним сортировку по такому принципу: отсортируем список people по возрастанию длин имён людей.
Для этого создадим класс с именем NameComparer (имя может быть любым допустимым), который реализует интерфейс IComparer<string[]>. Тип string[] мы указываем, поскольку элемент списка в нашем случаем – это строковый массив.
C#
class NameComparer : IComparer<string[]>
{
public int Compare(string[] o1, string[] o2)
{
if (o1.Length > o2.Length)
{
return 1;
}
else if (o1.Length < o2.Length)
{
return -1;
}
return 0;
}
}
|
1 |
classNameComparerIComparer<string> { publicintCompare(stringo1,stringo2) { if(o1.Length>o2.Length) { return1; } elseif(o1.Length<o2.Length) { return-1; } return; } } |
В классе обязательно должен содержаться метод Compare, в котором описано как сравнивать два объекта (два элемента списка). В нашем случае эти объекты имеют имена o1 и o2.
Сортировка по возрастанию
Если первый объект по нужному признаку больше второго объекта, то следует возвратить единицу. Если меньше, то минус единицу.
Если объекты равны, то возвращаем ноль.
Для сортировки по убыванию поменяйте местами 1 и -1.
В данном примере мы сравниваем длину строк первых (нулевых) элементов двух массивов, поскольку в первом элементе хранится имя пользователя.
Отсортируем список people. Для этого создадим экземпляр класса NameComparer и вызовем у списка метод Sort, передав в него в качестве аргумента экземпляр созданного класса. После выведем список в консоль.
C#
NameComparer nc = new NameComparer();
people.Sort(nc);
OutputList(people, «Список после сортировки по длине имён»);
|
1 |
NameComparer nc=newNameComparer(); people.Sort(nc); OutputList(people,»Список после сортировки по длине имён»); |
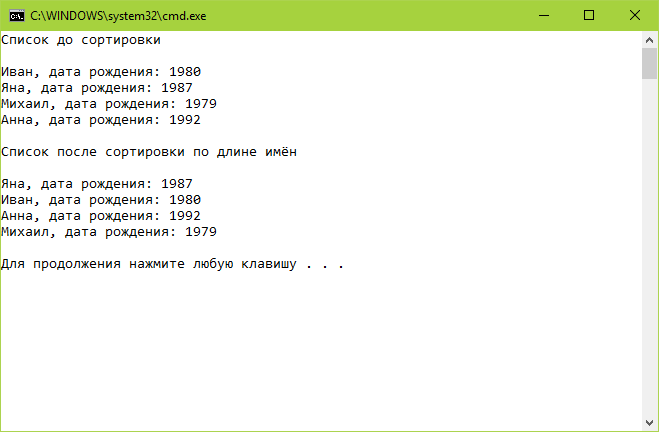 Второй пример сортировки списка
Второй пример сортировки списка
Рассмотрим еще один пример сортировки. На этот раз отсортируем список people по году рождения людей (от старших к младшим). Для этого создадим класс YearComparer.
C#
class YearComparer : IComparer<string[]>
{
public int Compare(string[] o1, string[] o2)
{
int a = Convert.ToInt32(o1);
int b = Convert.ToInt32(o2);
if (a > b)
{
return 1;
}
else if (a < b)
{
return -1;
}
return 0;
}
}
|
1 |
classYearComparerIComparer<string> { publicintCompare(stringo1,stringo2) { inta=Convert.ToInt32(o11); intb=Convert.ToInt32(o21); if(a>b) { return1; } elseif(a<b) { return-1; } return; } } |
Поскольку у нас год хранится в виде строки, сначала её необходимо конвертировать в число. Делается это с помощью метода Convert.ToInt32() .
Отсортируем List по годам рождения пользователей и выведем его на экран.
C#
YearComparer yc = new YearComparer();
people.Sort(yc);
OutputList(people, «Список после сортировки по году рождения»);
|
1 |
YearComparer yc=newYearComparer(); people.Sort(yc); OutputList(people,»Список после сортировки по году рождения»); |
![]()
Скачать исходник программы из данного урока:
Скачать исходникРепозиторий проекта на GitHub
Сортировка списка объектов
Сортировка по умолчанию работает с числами и строками. Но это не будет работать со списком настраиваемых объектов. Посмотрим, что произойдет, когда мы попытаемся запустить сортировку по умолчанию для списка объектов.
class Employee:
def __init__(self, n, a, gen):
self.name = n
self.age = a
self.gender = gen
def __str__(self):
return f'Emp'
# List uses __repr__, so overriding it to print useful information
__repr__ = __str__
e1 = Employee('Alice', 26, 'F')
e2 = Employee('Trudy', 25, 'M')
e3 = Employee('Bob', 24, 'M')
e4 = Employee('Alexa', 22, 'F')
emp_list =
print(f'Before Sorting: {emp_list}')
try:
emp_list.sort()
except TypeError as te:
print(te)
Вывод:
Before Sorting: , Emp, Emp, Emp] '<' not supported between instances of 'Employee' and 'Employee'
В этом случае мы должны в обязательном порядке предоставить ключевую функцию для указания поля объектов, которое будет использоваться для сортировки.
# sorting based on age
def sort_by_age(emp):
return emp.age
emp_list.sort(key=sort_by_age)
print(f'After Sorting By Age: {emp_list}')
Вывод:
After Sorting By Age: , Emp, Emp, Emp]
Мы также можем использовать модуль functools для создания пользовательской логики сортировки для элементов списка.
11 ответов
Лучший ответ
Если я правильно понимаю, вы хотите что-то вроде этого:
(Здесь я преобразую значения в числа вместо строк, содержащих числа. Вы можете преобразовать их в и , если вы действительно этого хотите, но я не уверен, почему вы этого хотите.)
Причина, по которой ваш код не работает, заключается в том, что использование в столбце (второй в вашем ) не означает «выбрать строки, в которых значение равно« женский »» , Это означает, что нужно выбрать строки, в которых index — это «female», которых в вашем DataFrame может не быть.
218
BrenBarn
26 Апр 2014 в 06:12
В качестве альтернативы есть встроенная функция pd.get_dummies для таких назначений:
Это дает вам фрейм данных с двумя столбцами, по одному на каждое значение, встречающееся в w , из которых вы отбрасываете первый (потому что вы можете вывести его из того, что осталось). Новый столбец автоматически будет назван в качестве строки, которую вы заменили.
Это особенно полезно, если у вас есть категориальные переменные с более чем двумя возможными значениями. Эта функция создает столько фиктивных переменных, сколько необходимо для различения всех случаев. Будьте осторожны, чтобы не назначить весь фрейм данных одному столбцу, а вместо этого, если w может быть ‘male’, ‘female’ или ‘нейтральным’, сделайте что-то вроде этого:
Затем у вас остаются две новые колонки, дающие вам фиктивную кодировку «женщина», и вы избавились от колонки со строками.
7
galliwuzz
1 Дек 2016 в 10:27
Вы можете редактировать подмножество данных, используя loc:
В этом случае:
104
Jimmy Petersson
16 Фев 2015 в 12:27
Это очень компактно:
Еще один хороший:
8
Azz
24 Июл 2018 в 10:55
В также есть функция ` X1`, который вы можете использовать для автоматического выполнения этой работы. Он преобразует метки в числа: . См. этот ответ для получения дополнительной информации.
1
Roald
18 Ноя 2017 в 14:54
Вы также можете использовать с , т.е.
{{Х0}} :
Фрейм данных :
Используя для замены значений из словаря:
Результат:
Примечание: со словарем следует использовать, если все возможные значения столбцов в кадре данных определены в словаре, иначе он будет пустым для тех, которые не определены в словаре.
10
student
13 Мар 2018 в 22:20
Использование с
Если ваш столбец содержит больше строк, чем только и , в этом случае произойдет сбой , поскольку он вернет для других значений.
Вот почему мы должны связать это с :
Пример, почему не удается :
Для метода правильного мы связываем с , поэтому заполняем значениями из исходного столбца:
Erfan
27 Янв 2020 в 19:43
Небольшое изменение:
32
deckard
30 Апр 2016 в 16:34
Я думаю, что в ответе должно быть указано, какой тип объекта вы получаете во всех методах, предложенных выше: это Series или DataFrame.
Когда вы получите столбец по или (где, предположим, 2 — это номер вашего столбца), вы получите DataFrame. Так что в этом случае вы можете использовать методы DataFrame, такие как .
Когда вы используете или , вы возвращаете Series, а Series не имеют метода , поэтому вам следует использовать такие методы, как , и скоро.
Alex-droid AD
15 Окт 2018 в 11:43
Это также должно работать:
19
Nick Crawford
19 Авг 2016 в 20:35
См. pandas.DataFrame.replace () документы. ,
31
jfs
26 Мар 2016 в 15:08
Массивы на «стероидах»
Часто работаете с массивами? Тогда вам понравится это расширение для работы с коллекциями.
Рассмотрим несколько примеров.
Простая сортировка чисел:
$collection = collect(); $sorted = $collection->sort(); $sorted->values()->all(); //
Сортировка по одной «колонке» ассоциативного массива:
$collection = collect(,
,
,
]);
$sorted = $collection->sortBy('price');
$sorted->values()->all();
/*
,
,
,
]
*/
Сортировка по нескольким аттрибутам одновременно:
$collection = collect(,
,
,
,
]);
$sorted = $collection->sortBy(,
,
]);
$sorted->values()->all();
/*
,
,
,
,
]
*/
Вы также можете использовать свои функции сортировки при работе с коллекциями:
$collection = collect(,
,
,
,
]);
$sorted = $collection->sortBy( <=> $b,
fn ($a, $b) => $b <=> $a,
]);
$sorted->values()->all();
/*
,
,
,
,
]
*/
Коллекции позволяют работать с массивами как в Laravel и функции этого замечательного инструмента далеко не ограничиваются сортировкой.
Изучите документацию и вы влюбитесь в коллекции.
Помогла ли Вам эта статья?
Да
Нет
DataFrame и Series
Чтобы анализировать данные с помощью Pandas, нужно понять, как устроены структуры этих данных внутри библиотеки. В первую очередь разберем, что такое DataFrame и Series.
Pandas Series (серия) — это одномерный массив. Визуально он похож на пронумерованный список: слева в колонке находятся индексы элементов, а справа — сами элементы.
![]()
Индексом может быть числовой показатель (0, 1, 2…), буквенные значения (a, b, c…) или другие данные, выбранные программистом. Если особое значение не задано, то числовые индексы проставляются автоматически. Например, от 0 до 5 как в примере выше.
Такая нумерация называется RangeIndex, в ней всегда содержатся числа от 0 до определенного числа N, которое обозначает количество элементов в серии. Собственные значения индексов задаются в квадратных скобках через index, как в примере ниже:
![]()
Индексы помогают обращаться к элементам серии и менять их значения. Например, чтобы в нашей серии заменить значения некоторых элементов на 0, мы прописываем индексы нужных элементов и указываем, что они равны нулю:
![]()
Можно сделать выборку по нескольким индексам, чтобы ненужные элементы в серии не отображались:
>>> my_series2]
a 5
b 6
f 10
dtype: int64
Pandas DataFrame — это двумерный массив, похожий на таблицу/лист Excel (кстати, данные из Excel можно читать с помощью команды pandas.read_excel(‘file.xls’)). В нем можно проводить такие же манипуляции с данными: объединять в группы, сортировать по определенному признаку, производить вычисления. Как любая таблица, датафрейм состоит из столбцов и строк, причем столбцами будут уже известные объекты — Series.
Чтобы проверить, действительно ли серии — это части датафрейма, можно извлечь любую колонку из таблицы. Возьмем набор данных о нескольких странах СНГ, их площади и населении и выберем колонку country:
>>> df = pd.DataFrame({
… ‘country’: ,
… ‘population’: ,
… ‘square’:
… })
>>> df
country population square
0 Kazakhstan 17.04 2724902
1 Russia 143.50 17125191
2 Belarus 9.50 207600
3 Ukraine 45.50 603628
В итоге получится простая серия, в которой сохранятся те же индексы по строкам, что и в исходном датафрейме.
>>> df
0 Kazakhstan
1 Russia
2 Belarus
3 Ukraine
Name: country, dtype: object
>>> type(df)
<class ‘pandas.core.series.Series’>
Курс
Аналитика данных с нуля
Получите востребованные навыки и освойте профессию аналитика данных за 6 месяцев. Дополнительная скидка 5% по промокоду BLOG.
Узнать больше
Кроме этого, у датафрейма есть индексы по столбцам, которые задаются вручную. Для простоты написания кода обозначим страны индексами из двух символов: Kazakhstan — KZ, Russia — RU и так далее:
>>> df = pd.DataFrame({
… ‘country’: ,
… ‘population’: ,
… ‘square’:
… }, index=)
>>> df
country population square
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
>>> df.index =
>>> df.index.name = ‘Country Code’
>>> df
country population square
Country Code
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
По индексам можно искать объекты и делать выборку, как в Series. Возьмем тот же датафрейм и сделаем выборку по индексам KZ, RU и колонке population методом .loc (в случае .loc мы используем квадратные скобки, а не круглые, как с другими методами), чтобы сравнить население двух стран:
>>> df.loc, ‘population’]
Country Code
KZ 17.04
RU 143.50
Name: population, dtype: float64
Также в DataFrame производят математические вычисления. Например, рассчитаем плотность населения каждой страны в нашем датафрейме. Данные в колонке population (численность населения) делим на square (площадь) и получаем новые данные в колонке density, которые показывают плотность населения:
>>> df = df / df * 1000000
>>> df
country population square density
Country Code
KZ Kazakhstan 17.04 2724902 6.253436
RU Russia 143.50 17125191 8.379469
BY Belarus 9.50 207600 45.761079
UA Ukraine 45.50 603628 75.377550
Курс
Data Science с нуля
Закрепите навыки Data Science и получите перспективную профессию за 13 месяцев. Дополнительная скидка 5% по промокоду BLOG.
Узнать больше
Статистический анализ в Pandas
Модуль Python Pandas предлагает большое количество встроенных методов, помогающих пользователям проводить статистический анализ данных.
Ниже приводится список некоторых наиболее часто используемых функций для статистического анализа:
| Метод | Description |
|---|---|
| count() | Подсчитывает количество всех непустых наблюдений |
| sum() | Возвращает сумму элементов данных. |
| mean() | Возвращает среднее значение всех элементов данных. |
| median() | Возвращает медианное значение всех элементов данных. |
| mode() | Возвращает режим всех элементов данных |
| std() | Возвращает стандартное отклонение всех элементов данных. |
| min() | Возвращает минимальный элемент данных среди всех входных элементов. |
| max() | Возвращает максимальный элемент данных среди всех входных элементов. |
| abs() | Возвращает абсолютное значение. |
| prod() | Возвращает произведение значений данных. |
| cumsum() | Возвращает кумулятивную сумму значений данных. |
| cumprod() | Возвращает совокупное произведение значений данных. |
| describe() | Он отображает статистическую сводку всех записей за один снимок, т.е. (сумма, количество, мин, среднее и т. Д.) |
Для начала давайте создадим DataFrame, который мы будем использовать в этом разделе для понимания различных функций, предоставляемых для статистического анализа.
import pandas
import numpy
input = {'Name':pandas.Series(),
'Marks':pandas.Series(),
'Roll_num':pandas.Series()
}
#Creating a DataFrame
data_frame = pandas.DataFrame(input)
print(data_frame)
Выход:
Name Marks Roll_num 0 John 44 1 1 Bran 48 2 2 Caret 75 3 3 Joha 33 4 4 Sam 99 5
Заключение ↑
Теперь вы знаете, как использовать два основных метода библиотеки pandas: и . Обладая этими знаниями, вы можете выполнять базовый анализ данных с помощью DataFrame. Хотя между этими двумя методами есть много общего, различие между ними позволяет понять, какой из них использовать для разных аналитических задач. В этом руководстве вы узнали, как:
- Сортировать Dataframe pandas по значениям одного или нескольких столбцов
- Использовать параметр , чтобы изменить порядок сортировки
- Сортировать DataFrame по индексу с помощью
- Упорядочивать недостающие данные при сортировке значений
- Сортировать DataFrame на месте, используя для параметра значение
Эти методы — значимая часть навыков анализа данных. Они помогут вам построить прочный фундамент, на котором можно выполнять более сложные операции с pandas. Если вы хотите увидеть несколько примеров более продвинутого использования методов сортировки pandas, документация pandas — отличный ресурс.
По мотивам Pandas Sort: Your Guide to Sorting Data in Python