
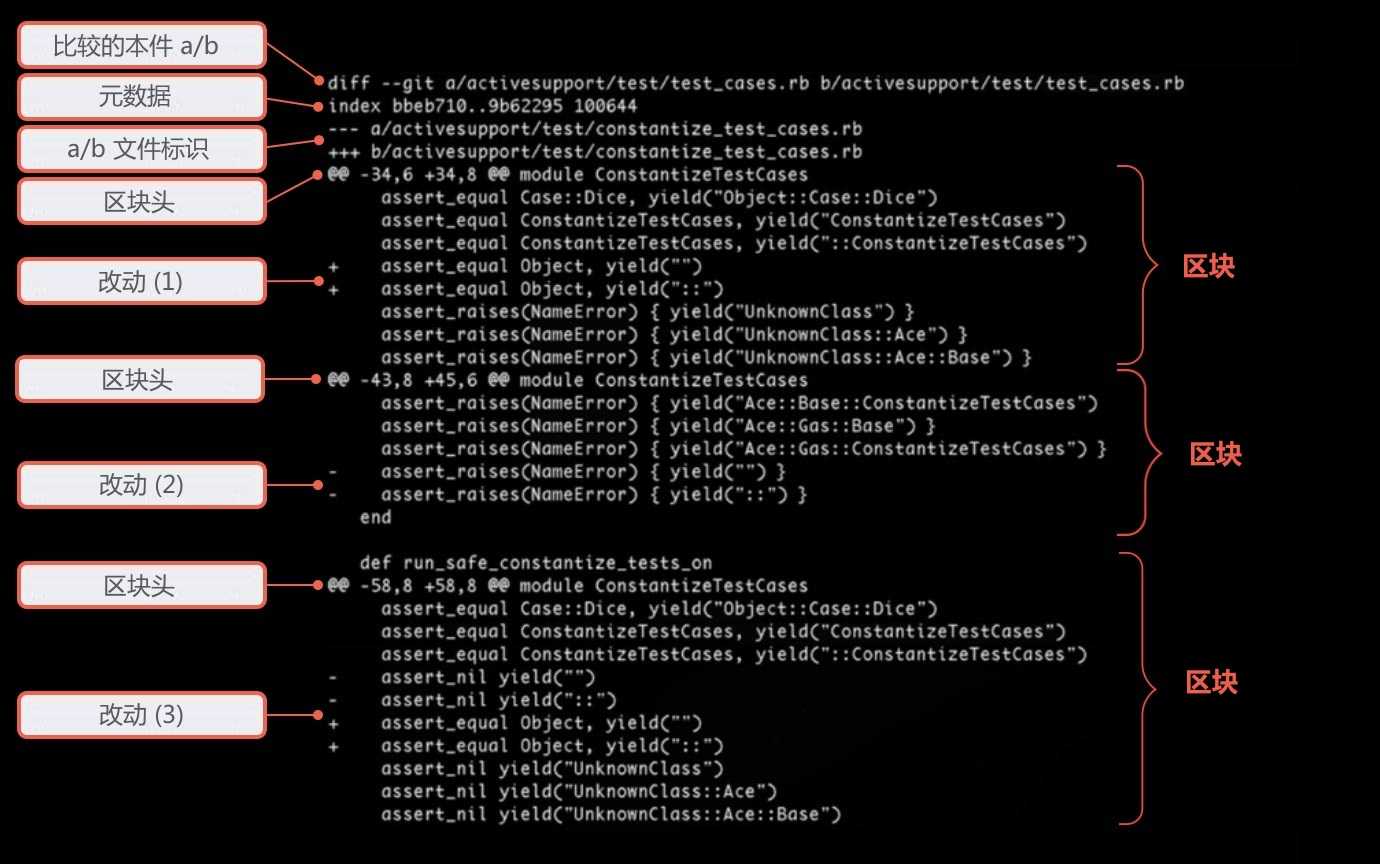
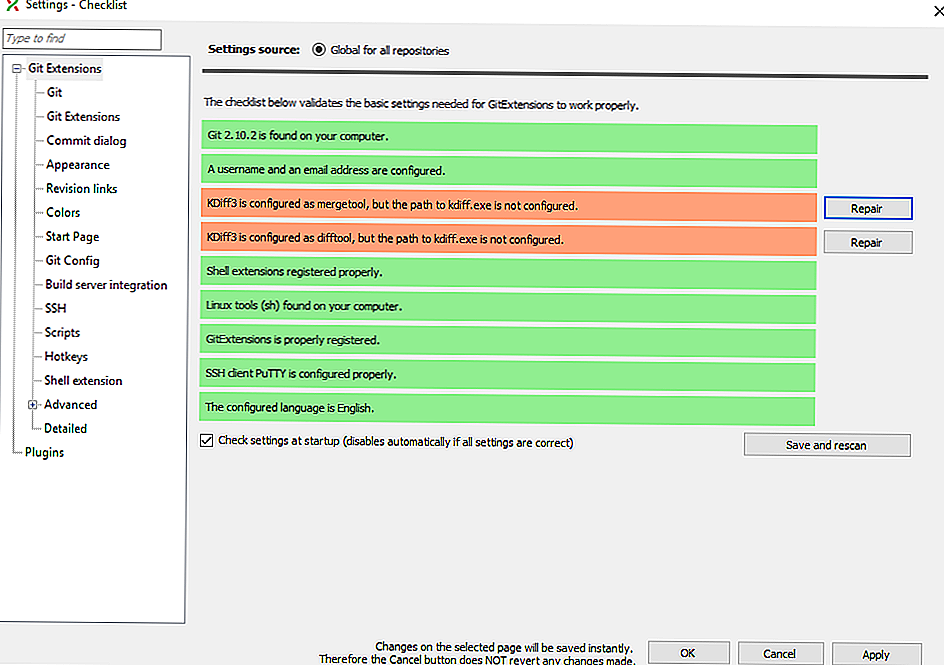
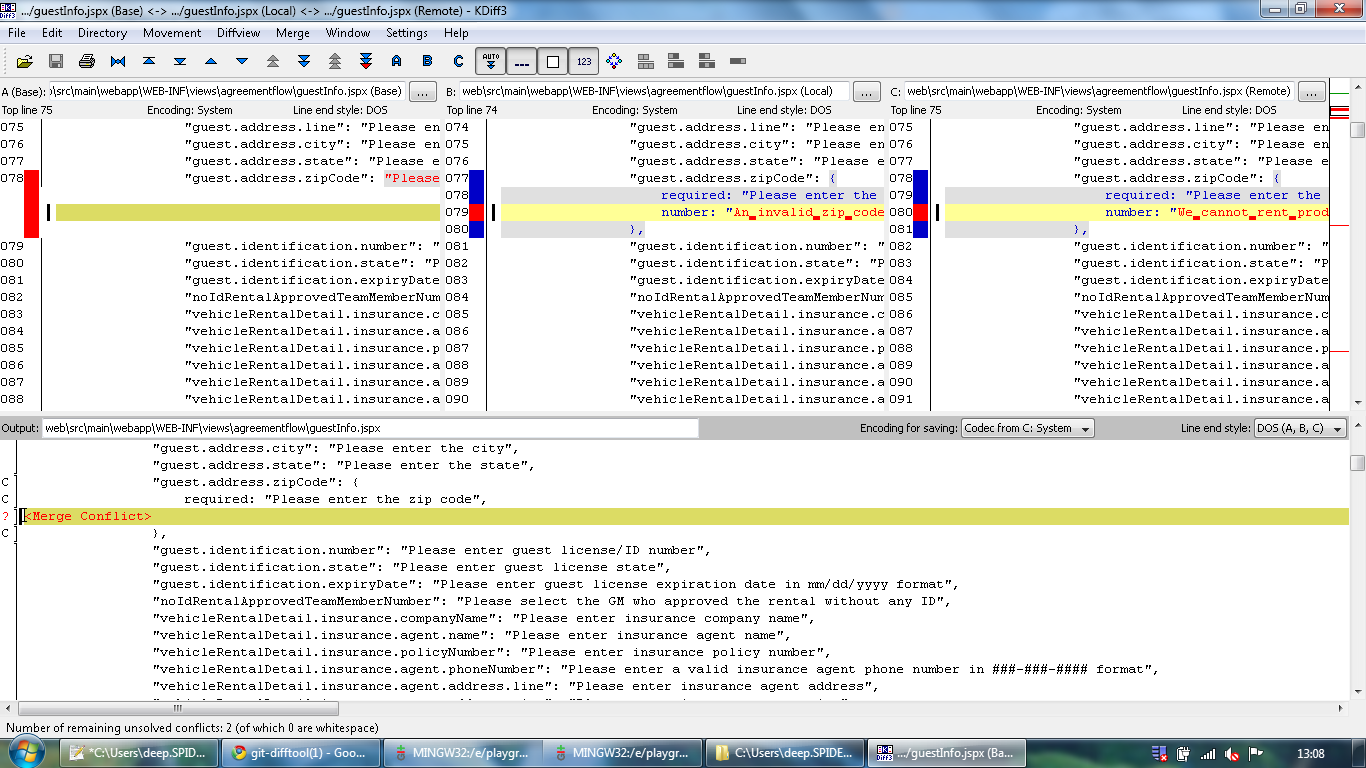
Как именно делать git squash
Возьмем для примера следующую историю Git:
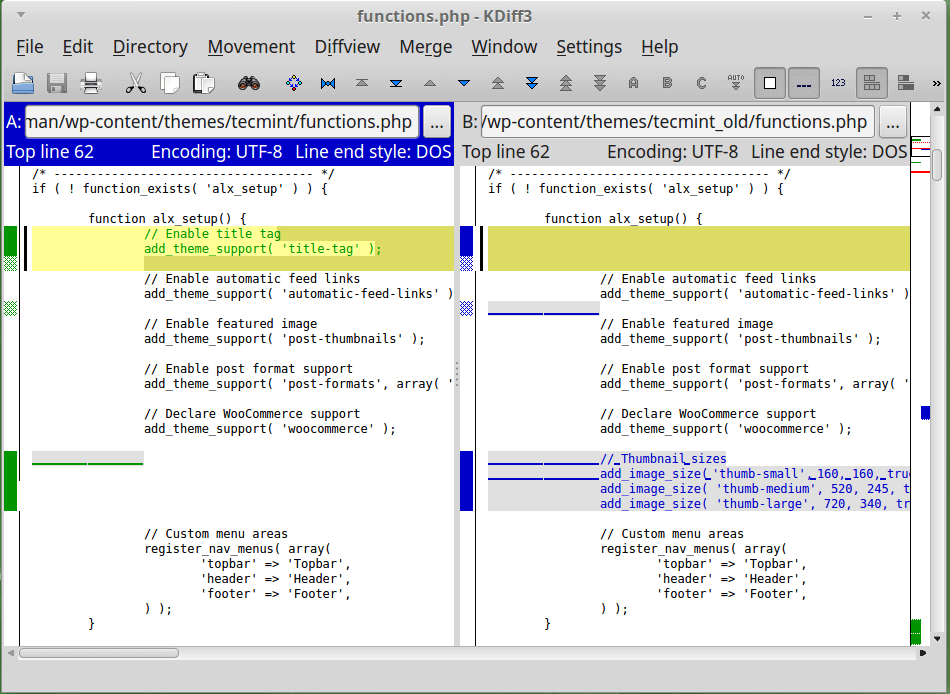
Здесь видны последние три коммита. В сообщениях к ним поясняется, что мы добавили новый файл и какое-то содержимое. Лучше заменить их одним единственным коммитом о том, что произошло добавление нового файла с некоторым содержимым. Итак, давайте посмотрим, как сжать последние три коммита в один:
git rebase -i HEAD~3
— интерактивный инструмент, который помогает сжимать коммиты. У него много возможностей, но давайте сосредоточимся на .
Если вы не очень хорошо знакомы с перебазированием — не волнуйтесь. Сжатие коммитов — одна из самых простых операций, которые выполняются через интерактивный git-rebase (т.е. ). означает, что мы берем последние три коммита.
Далее откроется редактор
Посмотрите, охватывает только последние три коммита, и обратите внимание на количество опций. Нас, однако, интересует только
Давайте же приведем все к одному коммиту.
Как видите, для сжатия мы отметили последние два коммита с помощью команд или .
В примере, приведенном выше, коммиты, предназначенные для сжатия, будут слиты с основным коммитом — тем, который отмечен командой . Отметив коммиты, сохраните изменения в редакторе.
Далее снова откроет редактор для ввода сообщения о коммите, как на картинке ниже:
Отредактировав и сохранив сообщения, можете закрыть редактор
Обратите внимание: строки, которые начинаются с , будут проигнорированы. После этого журнал Git будет выглядеть следующим образом:
![]()
Здесь изменилось сообщение о коммите, и обратите внимание: три коммита “склеились” в один. Также изменился хэш коммита
Через всегда создается новый коммит, содержащий соответствующие изменения.
Так что используйте этот инструмент с осторожностью. Помните: сжатие коммитов меняет историю Git, поэтому не рекомендуется сжимать ветвь, если вы уже отправили ее в удаленный репозиторий
Всегда выполняйте сжатие до того, как отправить пуш с изменениями
Помните: сжатие коммитов меняет историю Git, поэтому не рекомендуется сжимать ветвь, если вы уже отправили ее в удаленный репозиторий. Всегда выполняйте сжатие до того, как отправить пуш с изменениями.
Merging and resolving conflicts
Before going to the tip itself, to make sure that everyone is on the same page, let’s see how commonly git merge is used, conflicts happen and are solved.
Imagine that you and a coworker are working on a development project and the team use a Git repository to store the source code. In addition to the branch, each developer has their own branch (e.g. and ). While you are developing a feature, you commit to your branch. When you are finished, you merge your branch into the branch.
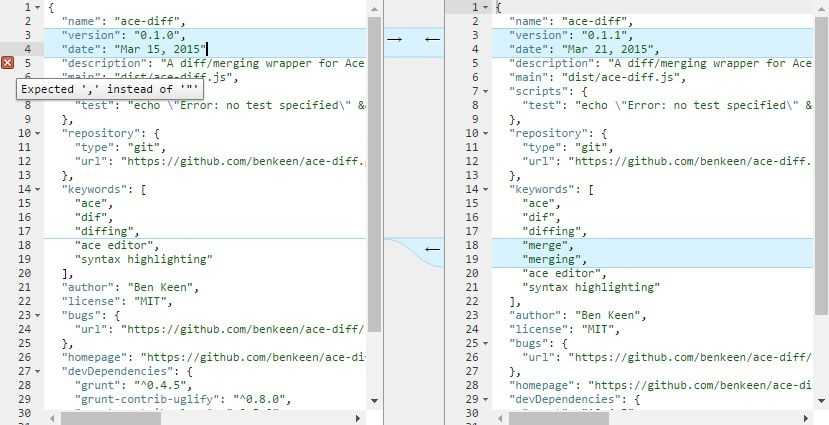
Imagine also that you and your colleague are working in parallel on the same file, editing the same part of the file (or even the same lines), but your colleague merged his branch into the branch before you. When you try to merge your branch, Git accuses a file conflict:
![]()
I’ll give you an example that happened to me in real life once, while merging upstream changes to a fork:
In case of a merge conflict, you need to manually edit the conflicting files, comparing the changes you and your colleague made and deciding on the final version of the files, and then run git commit to finalize the merge commit.
Администрирование конфигураций 1С (недокументированные особенности работы)
Многие мои коллеги по работе и по профессии, уверен, сталкиваются с аналогичными ситуациями, когда программа 1С при работе с конфигурацией, мягко говоря, работает «странно». Как говорит один хороший знакомый (к слову, один из авторов УТ 11):
— «вот, ну согласись, нанять пару серьезных методистов — реальных дядечек с реального производства, до начала разработки — единственная ЭЛЕМЕНТАРНАЯ политика, как можно было этого не сделать???? там их НЕТ. Причем это 0 в плане затрат на разработку, там нет ограничений бюджета, это просто самый тупой прокол.»
В этой статье приведу способы лечения пресловутых проколов (за последний месяц).
Форматирование и пробелы
Проблемы форматирования и пробелов являются одними из самых неприятных и незаметных проблем, с которыми сталкивают разработчики при совместной работе, особенно используя разные платформы. Это легко может произойти с патчами или с любой другой совместной работой, так как редакторы молча исправляют несоответствия, и если ваши файлы когда либо касаются систем Windows, то переносы строк могут быть заменены. В Git есть несколько настроек, чтобы справиться с этими проблемами.
Если вы программируете в Windows и работаете с людьми, которые не используют её (или наоборот), рано или поздно, вы столкнётесь с проблемами переноса строк. Это происходит потому, что Windows при создании файлов использует для обозначения переноса строки два символа «возврат каретки» и «перевод строки», в то время как Mac и Linux используют только один – «перевод строки». Это незначительный, но невероятно раздражающий факт кроссплатформенной работы; большинство редакторов в Windows молча заменяют переносы строк вида LF на CRLF или вставляют оба символа, когда пользователь нажимает клавишу Enter.
Git может автоматически конвертировать переносы строк CRLF в LF при добавлении файла в индекс и наоборот – при извлечении кода. Такое поведение можно включить используя настройку . Если у вас Windows, то установите значение – при извлечении кода окончания строк LF будут преобразовываться в CRLF:
Если у вас система Linux или Mac, то вам не нужно автоматически конвертировать переносы строк при извлечении файлов; однако, если файл с окончаниями строк CRLF случайно попал в репозиторий, то Git может его исправить. Можно указать Git конвертировать CRLF в LF во время коммита, но не наоборот, установив настройке значение :
Такая конфигурация позволит вам использовать переносы строк CRLF в Windows, при этом в репозитории и системах Mac и linux будет использован LF.
Если вы используете Windows и программируете только для Windows, то вы можете отключить описанный функционал, задав значение , сохраняя при этом символы CR в репозитории:
Git поставляется настроенным на обнаружение и исправление некоторых проблем с пробелами. Он в состоянии найти шесть основных проблем, обнаружение трёх из них включено по умолчанию, а трёх других – выключено.
По умолчанию включены:
- ищет пробелы в конце строки;
- ищет пробелы в конце файла;
- ищет пробелы перед символом табуляции в начале строки.
По умолчанию выключены:
- ищет строки с пробелами вначале вместо символа табуляции (и контролируется настройкой );
- ищет символы табуляции в отступах в начале строки;
- указывает Git на валидность наличия CR в конце строки.
Указав через запятую значения для настройки , можно сказать Git, какие из этих опций должны быть включены. Чтобы отключить ненужные проверки, достаточно удалить их из строки значений или поставить знак перед каждой из них. Например, чтобы включить все проверки, кроме , выполните команду (при этом является сокращением и охватывает как , так и ):
Или можно указать только часть проверок:
Git будет искать указанные проблемы при выполнении команды и пытаться подсветить их, чтобы вы могли исправить их перед коммитом. Также эти значения будут использоваться во время применения патчей командой . При применении патчей, можно явно указать Git информировать вас в случае нахождения проблем с пробелами:
Так же можно указать Git автоматически исправлять эти проблемы перед применением патча:
Эти настройки также применяются при выполнении команды . Если проблемные пробелы попали в коммит, но ещё не отправлены в удалённую ветку, можно выполнить для автоматического исправления этих проблем.
Решение для Windows / msys git
Прочитав ответы, я обнаружил более простой способ, заключающийся в изменении только одного файла.
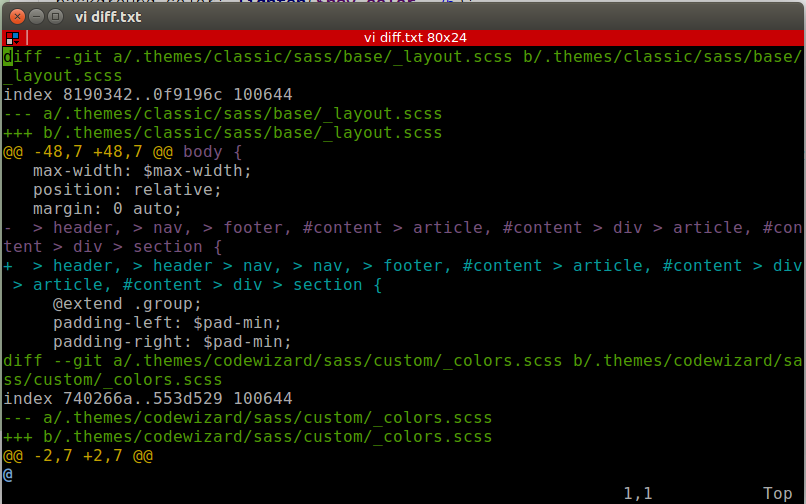
Создайте командный файл для вызова вашей программы сравнения с аргументами 2 и 5. Этот файл должен быть где-то на вашем пути. (Если вы не знаете, где это, поместите его в c: \ windows). Назовите его, например, «gitdiff.bat». Мой:
Установите переменную среды так, чтобы она указывала на ваш командный файл. Например:. Или через PowerShell, набрав
Важно не использовать кавычки и не указывать какую-либо информацию о пути, иначе это не сработает. Вот почему gitdiff.bat должен быть на вашем пути
Теперь, когда вы набираете «git diff», он вызывает вашу внешнюю программу просмотра различий.
- 1 +1 (+10, если бы мог.) Это действительно самое простое решение. Я часами боролся с принятым ответом и, наконец, сдался (некоторые из моих проблем, вероятно, были связаны с запуском Git через PowerShell …) Однако я использовал , вместо установки переменная окружения, и она работает одинаково хорошо.
- Пара проблем с этим решением: 1. Не работает с новыми файлами. WinMerge просит меня ввести второй файл для сравнения. 2. Окно сравнения следующего файла открывается только после закрытия текущего окна WinMerge, поэтому нет простого способа увидеть все файлы одновременно.
Если вы делаете это через cygwin, вам может потребоваться использовать Cygpath:
По какой-то причине использование «bc3» больше не работает для меня, но если я использую «за пределами», это нормально.
Посмотрев на некоторые другие внешние инструменты сравнения, я обнаружил, что view в IntelliJ IDEA (и Android Studio) для меня лучший.
Шаг 1 — настройте IntelliJ IDEA для запуска из командной строки
Если вы хотите использовать IntelliJ IDEA в качестве инструмента сравнения, вы должны сначала настроить IntelliJ IDEA для запуска из командной строки, следуя инструкциям здесь:
В macOS или UNIX:
Убедитесь, что IntelliJ IDEA запущена. В главном меню выберите . Откроется диалоговое окно «Создать сценарий запуска» с предложенным путем и именем сценария запуска. Вы можете принять значение по умолчанию или указать свой собственный путь
Обратите внимание на это, так как оно вам понадобится позже. Вне IntelliJ IDEA добавьте путь и имя сценария запуска к своему пути
В Windows:
- Укажите расположение исполняемого файла IntelliJ IDEA в системной переменной среды Path. В этом случае вы сможете вызывать исполняемый файл IntelliJ IDEA и другие команды IntelliJ IDEA из любого каталога.
Шаг 2 — настройте git для использования IntelliJ IDEA в качестве инструмента сравнения
Следуя инструкциям в этом сообщении в блоге:
Баш
Рыбы
Теперь добавьте в конфигурацию git следующее:
Вы можете попробовать это с или же
это работает для меня в Windows 7. Нет необходимости в промежуточных сценариях sh
содержимое .gitconfig:
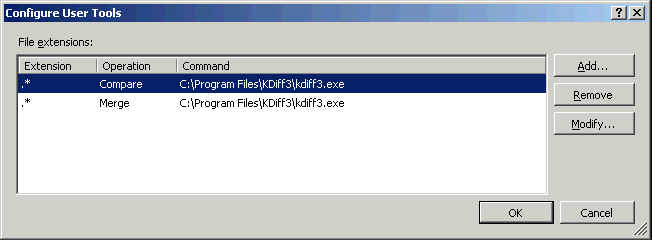
- У вас также есть kdiff3, определенный как ваш mergetool? Не могли бы вы поделиться этой частью вашего gitconfig, если так?
- 2 Спасибо. Это не совсем сработало для меня, но оно сработало, когда я удалил и изменил к
Краткое изложение приведенных выше замечательных ответов:
Затем используйте его, набрав (при желании также указав имя файла):
Резюме
Подведу маленький итог написанному. Скажу сразу, что загрузиться с переконфигурированного ядра мне удалось раза с пятого:) Посему — пробуйте, экспериментируйте! VirtualBox вам в помощь:)
По моему мнению, указанную в статье процедуру целесообразно выполнять либо при необходимости выиграть несколько мегабайт свободной памяти, либо добавить необходимые модули/драйвера (конечно, можно и другие причины придумать, например для экспериментов ). При этом, в первом случае, сборка ядра растягивается на неопределенный промежуток времени и неопределенное количество попыток сборки и перезагрузки для того чтобы получить «идеально» оптимизированное под железо и заточенное под себя ядро. Во втором случае, сборка ядра сводится к нескольким шагам: 1. получение исходников, 2. подготовка ядра к компиляции, 2.1 выполнение make cloneconfig перед make menuconfig для копирования текущих настроек ядра, 3. Выполнение make menuconfig или другой цели для конфигурирования и добавления новых параметров, 4. Компиляция и установка по вышеуказанной инструкции.
Итак, сборка и настройка индивидуального ядра состоит из нескольких этапов: 1. получение исходников ядра, 2. Конфигурирование ядра, 3. Сборка (компиляция) ядра, 4. Установка ядра. первый этап — это команда wget, второй — make menuconfig, третий — make. Вот так
Буду рад Вашим комментариям.
upd 2010.01.15: добавил новую цель — make nconfig (спасибо S_paul за коммент)
Основные понятия
Прежде чем перейти к выполнению каких-либо действий, нужно выяснить, какие именно настройки нужно отладить.
Предположим, что есть компьютер с достаточно сложными конфигурациями в стадии разработки. Эту систему нужно использовать для создания репозитория Git. В данный репозиторий нужно добавить соответствующие файлы, которые позже нужно будет толкнуть в удаленный репозиторий Git.
Удаленный репозиторий Git – удобное место для хранения конфигурационных данных, поскольку позже к нему можно будет получить доступ с любой машины, которой нужны эти файлы. Некоторые пользователи предпочитают хранить свои файлы на платформах совместной разработки (например, GitHub), но это достаточно рискованно, поскольку можно случайно разместить конфиденциальные данные в общедоступном для чтения месте.
Данное руководство использует GitLab, аналогичную GitHub платформу для хостинга git-репозиториев, которую можно запустить на собственном сервере.
Конфигурационные файлы, размещенные в удаленном git-репозитории, позже можно будет извлечь на другие системы для активации настроек.
Какие файлы можно хранить в git-репозитории?
Существует множество различных уровней настройки системы, и в некоторых случаях определенные типы файлов и настроек подходят больше, чем другие.
Файлы, содержащие сильно зависящие от системы значения, вероятно, лучше обработать вручную или с помощью системы управления конфигурациями (как Chef, Puppet или Ansible).
В случае, если настройки отлаживаются относительно потребностей системы, а не с расчетом на простоту использования, система Git не будет очень полезна, ведь большинство конфигураций все равно придется изменить под клиентскую систему.
Использование Git – отличное решение для хранения конфигураций инструментов и файлов пользовательской среды (таких, как vim, emacs, screen, tmux, bash, etc.).
В целом, в git-репозитории можно помещать любые дотфайлы (или файлы с точкой – скрытые конфигурационные файлы, расположенные в домашнем каталоге), которые не содержат конфиденциальных или сильно зависящих от системы настроек.
Основы ветвления
Предположим, вы работаете над проектом и уже имеете несколько коммитов.
Рисунок 18 – Простая история коммитов
Вы решаете, что теперь вы будете заниматься проблемой #53 из вашей системы отслеживания ошибок. Чтобы создать ветку и сразу переключиться на нее, можно выполнить команду с параметром :
Это то же самое что и:
Рисунок 19 – Создание нового указателя ветки
Вы работаете над своим сайтом и делаете коммиты. Это приводит к тому, что ветка движется вперед, так как вы переключились на нее ранее ( указывает на нее).
Рисунок 20 – Ветка двигается вперед
Тут вы получаете сообщение об обнаружении уязвимости на вашем сайте, которую нужно немедленно устранить. Благодаря Git, не требуется размещать это исправление вместе с тем, что вы сделали в . Вам даже не придется прилагать усилий, чтобы откатить все эти изменения для начала работы над исправлением. Всё, что вам нужно – переключиться на ветку .
Но перед тем как сделать это – имейте в виду, что если рабочий каталог или индекс содержат незафиксированные изменения, конфликтующие с веткой, на которую вы хотите переключиться, то Git не позволит переключить ветки. Лучше всего переключаться из чистого рабочего состояния проекта. Есть способы обойти это (припрятать изменения (stash) или добавить их в последний коммит (amend)), но об этом мы поговорим позже в разделе «Припрятывание и очистка» главы 7. Теперь предположим, что вы зафиксировали все свои изменения и можете переключиться на ветку :
С этого момента ваш рабочий каталог имеет точно такой же вид, какой был перед началом работы над проблемой #53, и вы можете сосредоточиться на работе над исправлением
Важно помнить: когда вы переключаете ветки, Git возвращает состояние рабочего каталога к тому виду, какой он имел в момент последнего коммита в эту ветку. Он добавляет, удаляет и изменяет файлы автоматически, чтобы состояние рабочего каталога соответствовало тому, когда был сделан последний коммит
Теперь вы можете перейти к написанию исправления. Давайте создадим новую ветку для исправления, в которой будем работать, пока не закончим.
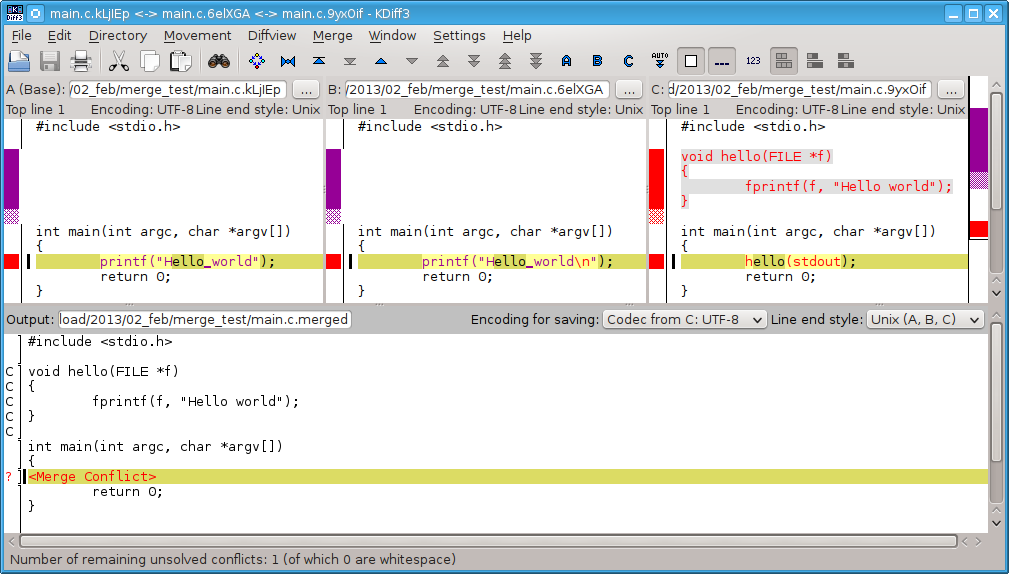
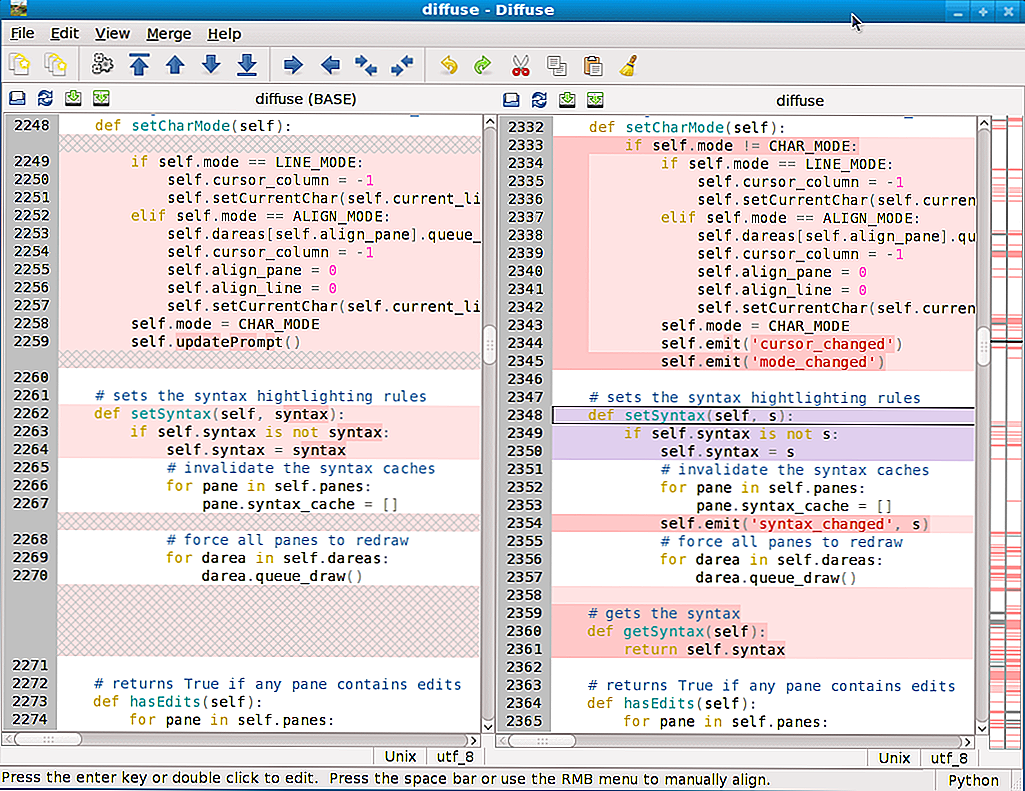
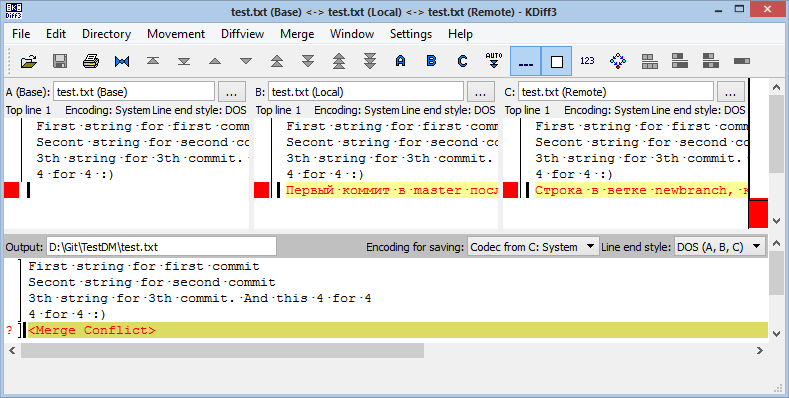
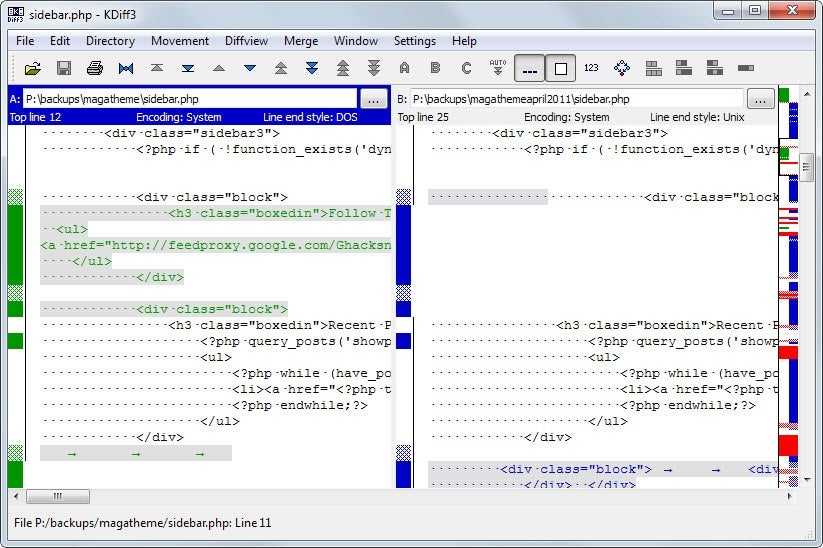
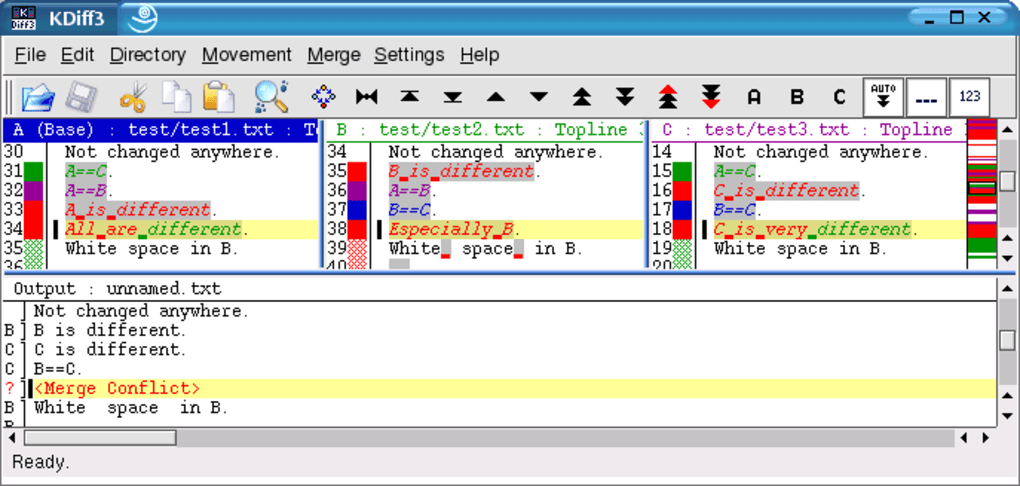
Рисунок 21 – Ветка основана на ветке
Вы можете прогнать тесты, чтобы убедиться, что ваше исправление делает именно то, что нужно. И если это так – выполнить слияние ветки с веткой для включения изменений в продукт. Это делается командой :
Заметили фразу «fast-forward» в этом слиянии? Git просто переместил указатель ветки вперед, потому что коммит C4, на который указывает слитая ветка , был прямым потомком коммита C2, на котором вы находились до этого. Другими словами, если коммит сливается с тем, до которого можно добраться двигаясь по истории прямо, Git упрощает слияние просто перенося указатель ветки вперед, поскольку расхождений в изменениях нет. Это называется «fast-forward».
Теперь ваши изменения включены в коммит, на который указывает ветка , и исправление можно внедрять.
Рисунок 22 – перемотан до
После внедрения вашего суперважного исправления, вы готовы вернуться к работе над тем, что были вынуждены отложить. Но сначала нужно удалить ветку , потому что она больше не нужна – ветка указывает на то же самое место
Для удаления ветки выполните команду с параметром :
Теперь вы можете переключиться обратно на ветку и продолжить работу над проблемой #53:
Рисунок 23 – Продолжение работы над iss53
Стоит обратить внимание на то, что все изменения из ветки не включены в вашу ветку. Если их нужно включить, вы можете влить ветку в вашу ветку командой , или же вы можете отложить слияние этих изменений до завершения работы, и затем влить ветку в
Working Area
Рассмотрим первый случай, когда имеется отслеживаемый файл , в который вносятся изменения.
Но изменения в этом файле не индексируются () и не фиксируются ().
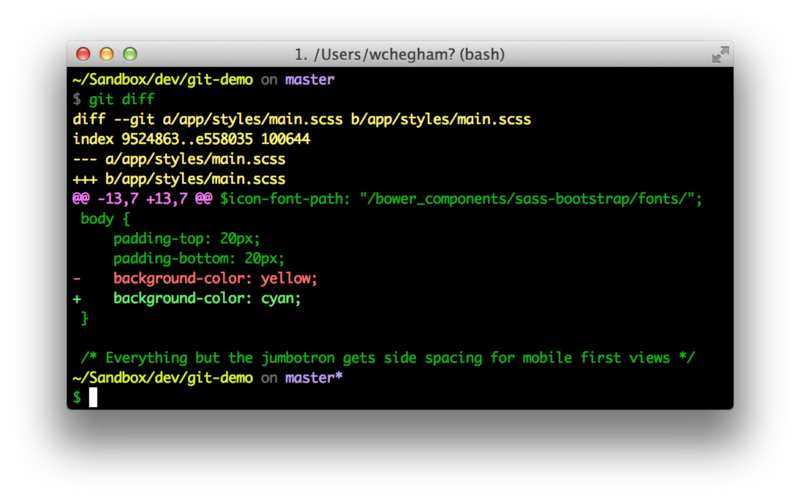
В этом случае, чтобы увидеть изменения, нужно запустить команду:
В этом случае производится сравнение между фиксированной версией файла (в области Repository) и его измененной версией (в области Working Area).
Вывод будет примерно таким:
В этом примере все предельно ясно и понятно. Строка — это фиксированная версия файла . Строка — это измененная версия файла .
Две строки:
… отображают, сколько и каких строк удалено (знак минус); сколько и каких строк добавлено (знак плюс).
Итак, с первым вариантом разобрались. Комадна выполняет сравнение версии файла из области Repository и этой же версии из области Working Area.
Resolving conflicts with Meld
Meld is a visual diff and merge tool targeted at developers. It helps you compare files and folders in two or three ways and supports many popular version control systems, including Git.
To install Meld on either Linux Kamarada or openSUSE, run:
You can use Meld standalone by opening the app and selecting the files or folders you want to compare, but I won’t go into detail about its basic usage, because our goal here is to see how to use Meld integrated with Git.
To resolve merge conflicts using Meld, run git mergetool:
The git mergetool command fires up an appropriate visual merge tool and walks you through the conflicts. It displays that long message on the first run because we have not yet set up a merge tool. Note that it supports several tools, including Meld, which is the first on the list and is also the one it suggests using. Hit Enter to start Meld.
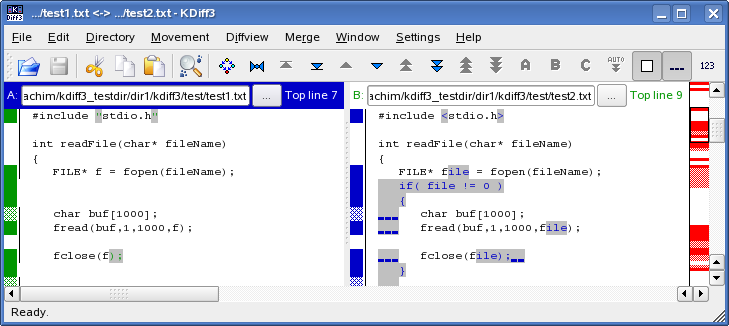
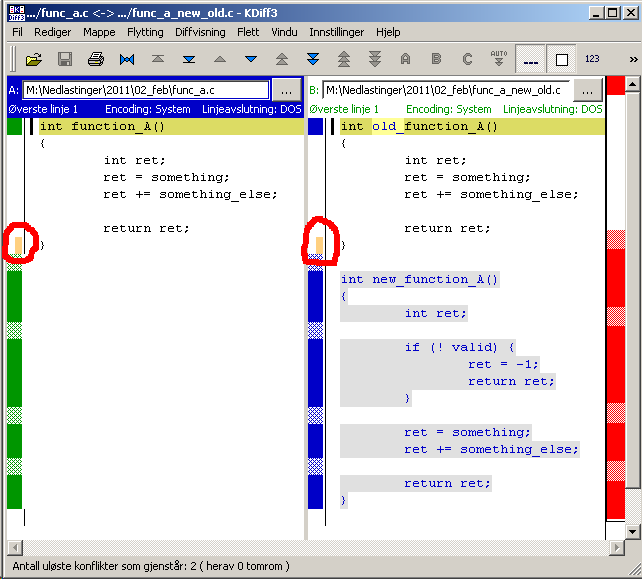
Meld opens the conflicting file in three ways: by the left, the previous version in the current branch (in this example, the branch); in the middle, the merged version (this is the one which is going to be commited); and by the right, the version in the branch being merged ():
![]()
You can use the arrows next to the lines to copy code snippets from one version to the other.
Note that, as Atom, Meld does not impose you take binary decisions: you can simply place the cursor in the middle view and start typing. The final version of the merged file will be anything which is in the middle view, it does not matter if the content came from the left view, the right view, or was typed by hand.
When you are finished resolving the conflict, click Save.
To set up Git to always use Meld to resolve conflicts without asking which tool to use, run the following commands:
With that done, that long message will no longer appear when you run git mergetool: Git will indicate which file you are merging and will already open Meld (you won’t need to hit Enter).
Besides resolving merge conflicts, Meld can be used to compare revisions of files controlled by Git.
Основные конфликты слияния
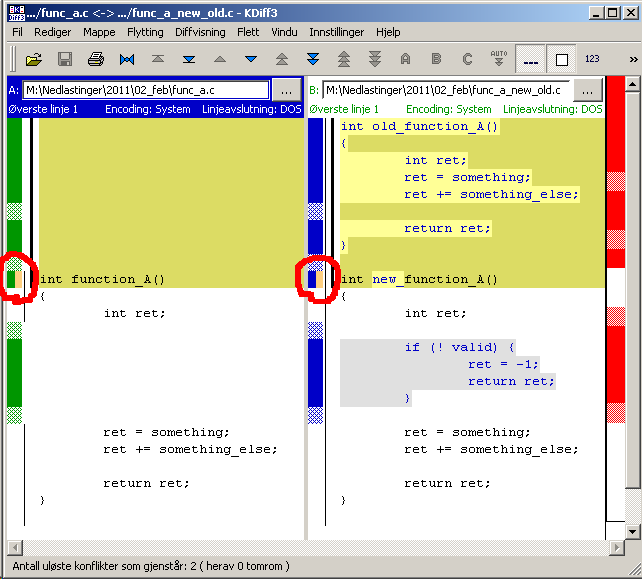
Иногда процесс не проходит гладко. Если вы изменили одну и ту же часть одного и того же файла по-разному в двух объединяемых ветках, Git не сможет их чисто объединить. Если ваше исправление ошибки #53 потребовало изменить ту же часть файла что и , вы получите примерно такое сообщение о конфликте слияния:
Git не создал коммит слияния автоматически. Он остановил процесс до тех пор, пока вы не разрешите конфликт. Чтобы в любой момент после появления конфликта увидеть, какие файлы не объединены, вы можете запустить :
Всё, где есть неразрешённые конфликты слияния, перечисляется как неслитое. В конфликтующие файлы Git добавляет специальные маркеры конфликтов, чтобы вы могли исправить их вручную. В вашем файле появился раздел, выглядящий примерно так:
Это означает, что версия из (вашей ветки , поскольку именно её вы извлекли перед запуском команды слияния) – это верхняя часть блока (всё, что над =======), а версия из вашей ветки представлена в нижней части. Чтобы разрешить конфликт, придётся выбрать один из вариантов, либо объединить содержимое по-своему. Например, вы можете разрешить конфликт, заменив весь блок следующим:
В этом разрешении есть немного от каждой части, а строки <<<<<<<, ======= и >>>>>>> полностью удалены. Разрешив каждый конфликт во всех файлах, запустите для каждого файла, чтобы отметить конфликт как решённый. Добавление файла в индекс означает для Git, что все конфликты в нём исправлены.
Если вы хотите использовать графический инструмент для разрешения конфликтов, можно запустить , который проведет вас по всем конфликтам:
Если вы хотите использовать инструмент слияния не по умолчанию (в данном случае Git выбрал , поскольку команда запускалась на Mac), список всех поддерживаемых инструментов представлен вверху после фразы «one of the following tools». Просто введите название инструмента, который хотите использовать.
Примечание
Более продвинутые инструменты для разрешения сложных конфликтов слияния мы рассмотрим в разделе «Продвинутое слияние» главы 7.
После выхода из инструмента слияния Git спросит об успешности процесса. Если вы ответите скрипту утвердительно, то он добавит файл в индекс, чтобы отметить его как разрешенный. Теперь можно снова запустить , чтобы убедиться в отсутствии конфликтов:
Если это вас устраивает и вы убедились, что все файлы, где были конфликты, добавлены в индекс – выполните команду для создания коммита слияния. Комментарий к коммиту слияния по умолчанию выглядит примерно так:
Если вы считаете, что коммит слияния требует дополнительных пояснений – опишите, как были разрешены конфликты, и почему были применены именно такие изменения, если это не очевидно.
Настройка удаленного сервера Git
Существует множество способов настройки удаленного репозитория для хранения файлов.
Проще всего толкнуть репозиторий конфигураций на GitHub. Для некоторых пользователей это отличное решение; но имейте в виду, что это действие представляет риск случайного разоблачения конфиденциальных данных.
Избежть этого можно путем использования закрытого git-репозитория, отличным примером которого является GitLab.
После установки нужно создать новый пустой репозиторий, который будет работать как удаленое место назначения файлов.
Создав пустой репозиторий, GitHub или GitLab выведет страницу с командами-подсказками, как переместить конфигурационные файлы в репозиторий. Если SSH-ключи еще не были добавлены, с помощью специальной клавиши можно переключиться с команд SSH на команды HTTP.
Используйте рекомендации, чтобы переместить конфигурационные файлы в удаленный репозиторий. Это делается примерно так:
Это толкнет файлы в репозиторий GitLab.
Извлечение конфигураций из удаленного репозитория
Теперь, когда конфигурационные файлы перемещены в удаленный репозиторий, их можно извлечь на другие машины. Для этого нужно сослаться на сервер, на который нужно извлечь конфигурационные файлы, как на целевую машину.
Убедитесь, что на целевой машине установлена система gitю Опять же, на Ubuntu это делается так:
После установки нужно установить основные переменные конфигураций:
Дальнейшие действия зависят от того, как данная машина должна взаимодействовать с файлами git-репозитория.
Сервер 1С:Предприятие на Ubuntu 16.04 и PostgreSQL 9.6, для тех, кто хочет узнать его вкус. Рецепт от Капитана
Если кратко описать мое отношение к Postgres: Использовал до того, как это стало мейнстримом.
Конкретнее: Собирал на нем сервера для компаний среднего размера (до 50 активных пользователей 1С).
На настоящий момент их набирается уже больше, чем пальцев рук пары человек (нормальных, а не фрезеровщиков).
Следуя этой статье вы сможете себе собрать такой же и начать спокойную легальную жизнь, максимально легко сделать первый шаг в мир Linux и Postgres.
А я побороться за 1. Лучший бизнес-кейс (лучший опыт автоматизации предприятия на базе PostgreSQL).
Если, конечно, статья придется вам по вкусу.
Когда нужно собирать новую версию ядра?
В настоящее время ядро Linux развивается очень быстро и бурно. Зачастую производители дистрибутивов не успевают внедрять в свои системы новые версии ядер. Как правило все новомодные «фишки» больше понадобятся любителям экзотики, энтузиастам, обладателям новинок устройств и оборудования и просто любопытствующим — т. е. преимущественно тем, в чьём распоряжении имеется обычный пользовательский компьютер.
Для серверных машин, однако, мода вряд ли имеет какое-то значение, а новые технологии внедряются только после того как на практике доказали свою надёжность и эффективность на тестовых стендах или даже платформах. Каждый опытный системный администратор знает, что гораздо надёжнее один раз настроить то, что может и должно хорошо и безотказно работать, чем пытаться бесконечно модернизировать систему. Ведь для этого необходимы многие часы работы (ведь приходится собирать ядро из исходных кодов, что довольно сложно) и обслуживания, что довольно дорогостоящее занятие, поскольку, вдобавок ко всему прочему требует глубокого резервирования — сервера не должны останавливаться без организации «горячего» (а уж тем более без «холодного») резерва.
Поэтому всегда стоит взвешивать все факторы и оценить, стоит ли вообще обновляться ради несущественных заплат, не влияющих на работу системы или внедрённых новых драйверов для устройств, коих в данный момент в системе нет и нескоро предвидится.
Если же принято решение обновить версию ядра путём его самостоятельной сборки, то нужно выяснить, является ли данная версия стабильной. Раньше система нумерования версий ядра Linux была организована таким образом, что чётные номера версий означали стабильный выпуск, нечётные — ещё «сырой». В настоящее время этот принцип соблюдается далеко не всегда и выяснять этот момент следует из информации на официальном сайте kernel.org.
Конфигурация сервера
Для серверной части Git не так много настроек, но есть несколько интересных, на которые стоит обратить внимание. Git способен убедиться, что каждый объект, отправленный командой , валиден и соответствует своему хешу SHA-1
По умолчанию эта функция отключена; это очень дорогая операция и может привести к существенному замедлению, особенно для больших объёмов отправляемых данных или для больших репозиториев. Вы можете включить проверку целостности объектов для каждой операции отправки, установив значение в :
Git способен убедиться, что каждый объект, отправленный командой , валиден и соответствует своему хешу SHA-1. По умолчанию эта функция отключена; это очень дорогая операция и может привести к существенному замедлению, особенно для больших объёмов отправляемых данных или для больших репозиториев. Вы можете включить проверку целостности объектов для каждой операции отправки, установив значение в :
Теперь, Git будет проверять целостность репозитория до принятия новых данных для уверенности, что неисправные или злонамеренные клиенты не смогут отправить повреждённые данные.
Если вы перебазируете коммиты, которые уже отправлены, и попытаетесь отправить их снова или попытаетесь отправить коммит в удалённую ветку, в которой не содержится коммит, на который она указывает, то данные приняты не будут. В принципе, это правильная политика; но в случае перебазирования вы знаете, что делаете и можете принудительно обновить удалённую ветку, используя флаг для команды .
Для запрета перезаписи истории установите в значение :
Сделать то же самое можно другим способом – используя хук на стороне сервера, мы рассмотрим его немного позже. Этот подход позволяет более гибко настроить ограничения: например, запретить перезапись истории определённой группе пользователей.
Политику можно обойти, удалив ветку и создав новую с таким же именем. Для предотвращения этого, установите в значение :
Эта команда запретит удаление веток и тегов всем пользователям. Чтобы удалить ветку, придётся удалить все соответствующие ей файлы на сервере вручную. Куда более интересный способ – это настроить права пользователей, с ним вы познакомитесь в разделе «Пример принудительной политики Git».
Компиляция ядра
Самое сложное в компиляции ядра Linux – это создание конфигурации сборки, поскольку нужно знать, какие компоненты подключать. Хотя использование команд make xconfig, make gconfig, make menuconfig и обеспечивает задание стандартной рабочей конфигурации, с которой система будет работать на большинстве аппаратных платформ и конфигураций. Вопрос лишь в том, чтобы грамотно задать конфигурацию ядра без ненужных и занимающих лишние ресурсы компонентов при его работе.
Итак, для успешного конфигурирования и компиляции ядра нужно выполнить следующие действия:
- перейти в каталог с исходными кодами ядра. Обычно «исходники» для ядра Linux помещаются в каталог /usr/src, либо можно скачать с сайта kernel.org в любое удобное место;
- выполнить команду make xconfig, make gconfig или make menuconfig;
- выполнить команду make dep (можно не выполнять для ядер версии 2.6.x и более поздних);
- выполнить команду make clean (для очистки от всего того, что может помешать успешной сборке);
- выполнить команду make;
- выполнить команду make modules_install;
- скопировать файл /arch/имя_архитектуры/boot/bzImage в /boot/vmlinuz. Здесь каталог /arch находится в каталоге с исходными кодами ядра Linux, имя_архитектуры — каталог, имеющий имя соответствующей архитектуры (указанной на этапе конфигурирования). Имя собранного бинарного образа ядра bzImage может быть другим;
- скопировать файл /arch/имя_архитектуры/boot/System.map в /boot/System.map;
- внести изменения в конфигурационные файлы системных загрузчиков /etc/lilo.conf (для LILO) или /boot/grub/grub.conf — для GRUB, а также добавить в них соответствующие конфигурационные и параметры загрузки для нового ядра.
Далее остаётся протестировать загрузку и работу нового ядра. В случае проблем обычно подбираются нужные параметры для системных загрузчиков.





