
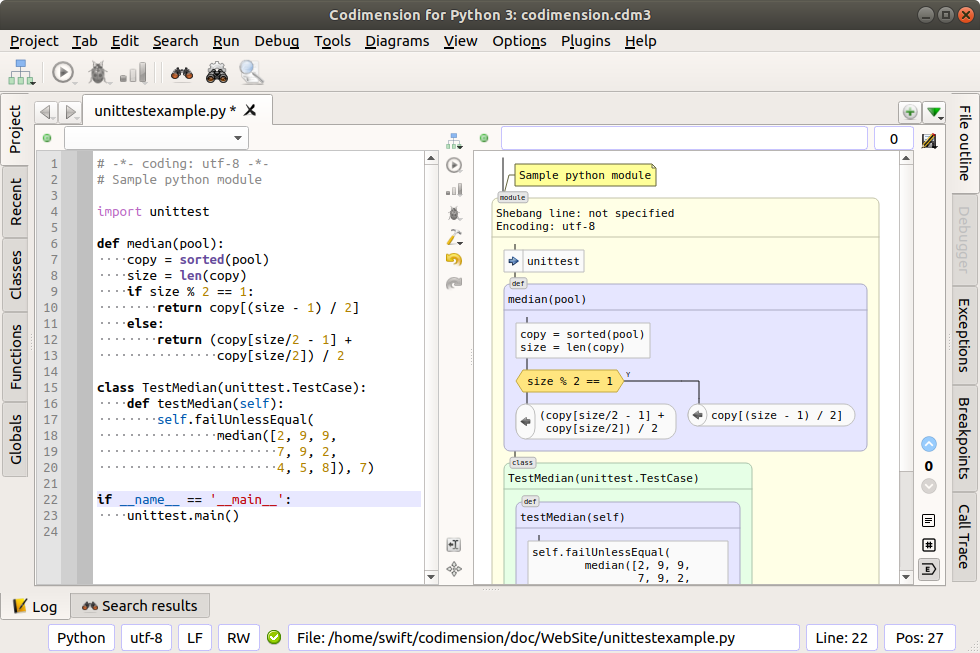
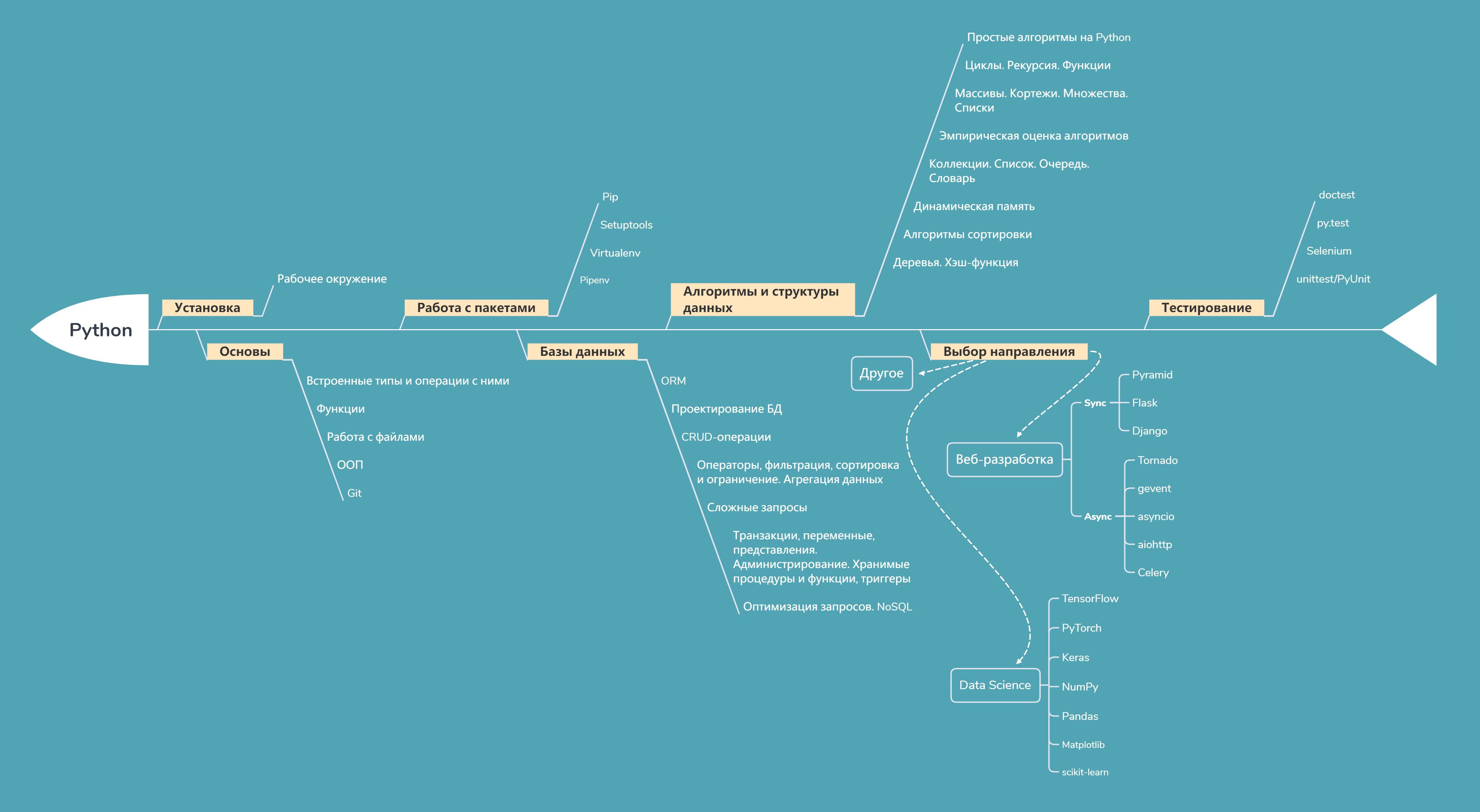
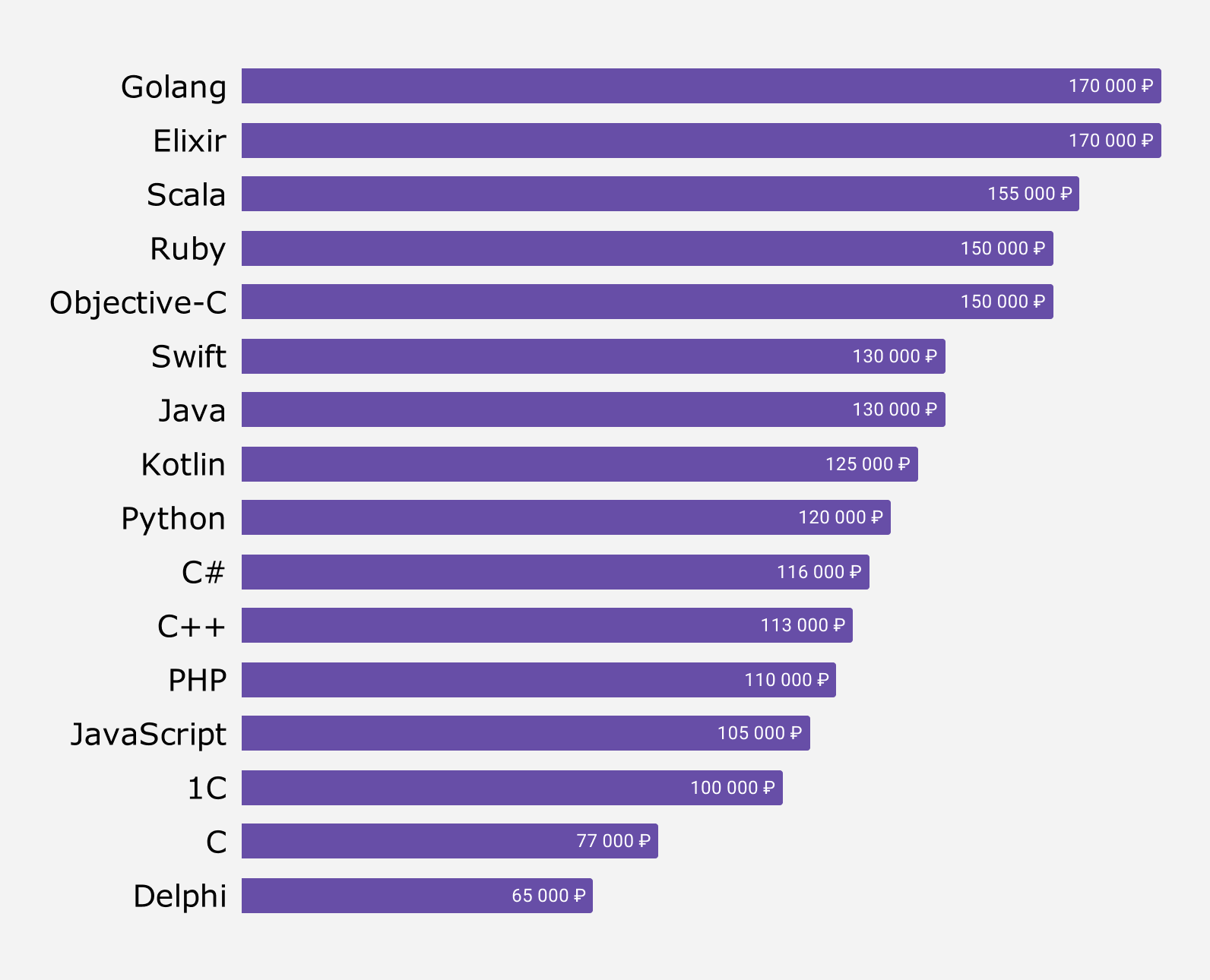
Билинейная интерполяция
Билинейная интерполяция, также известная как билинейная интерполяция. Математически билинейная интерполяция представляет собой расширение линейной интерполяции функции интерполяции с двумя переменными.Его основная идея заключается в выполнении линейной интерполяции в двух направлениях. Как показано ниже: Сначала выполните два вычисления линейной интерполяции в направлении X, а затем выполните вычисление интерполяции в направлении Y. При обработке изображений мы сначала
s
r
c
X
=
d
s
t
X
∗
(
s
r
c
W
i
d
t
h
d
s
t
W
i
d
t
h
)
srcX=dstX* (srcWidth/dstWidth)
srcX=dstX∗(srcWidthdstWidth)
s
r
c
Y
=
d
s
t
Y
∗
(
s
r
c
H
e
i
g
h
t
d
s
t
H
e
i
g
h
t
)
srcY = dstY * (srcHeight/dstHeight)
srcY=dstY∗(srcHeightdstHeight)Чтобы вычислить положение целевого пикселя в исходном изображении, вычисленные здесь srcX и srcY обычно являются числами с плавающей запятой. Например, пиксель f (1.2, 3.4) существует виртуально. Сначала найдите четыре фактических пикселя, смежных с ним. точка (1,3) (2,3) (1,4) (2,4) записывается как
f
(
i
+
u
,
j
+
v
)
f(i+u,j+v)
f(i+u,j+v)В виде
u
=
0.2
,
v
=
0.4
,
i
=
1
,
j
=
3
u=0.2,v=0.4, i=1, j=3
u=.2,v=.4,i=1,j=3При интерполяции по направлению X,
f
(
R
1
)
=
u
(
f
(
Q
21
)
−
f
(
Q
11
)
)
+
f
(
Q
11
)
f(R1)=u(f(Q21)-f(Q11))+f(Q11)
f(R1)=u(f(Q21)−f(Q11))+f(Q11)Вычислите таким же образом в направлении Y. Или напрямую организовать одноэтапные расчеты,
f
(
i
+
u
,
j
+
v
)
=
(
1
−
u
)
(
1
−
v
)
f
(
i
,
j
)
+
(
1
−
u
)
v
f
(
i
,
j
+
1
)
+
u
(
1
−
v
)
f
(
i
+
1
,
j
)
+
u
v
f
(
i
+
1
,
j
+
1
)
f(i+u,j+v) = (1-u)(1-v)f(i,j) + (1-u)vf(i,j+1) + u(1-v)f(i+1,j) + uvf(i+1,j+1)
f(i+u,j+v)=(1−u)(1−v)f(i,j)+(1−u)vf(i,j+1)+u(1−v)f(i+1,j)+uvf(i+1,j+1) Мысли о некоторых проблемах билинейной интерполяции:
-
За счет расчетных
s
r
c
X
srcX
srcXсs
r
c
Y
srcY
srcY Все они являются числами с плавающей запятой, и позже будет много умножений, а объем данных изображения велик, а скорость не будет идеальной, поэтомуПреобразование операций с плавающей запятой в целочисленные операции。 - Учитывая, что источник интерполяции отличается, использование метода интерполяции может показать разные эффекты интерполяции, поэтомуОтрегулируйте целевое изображение, центрируя его。
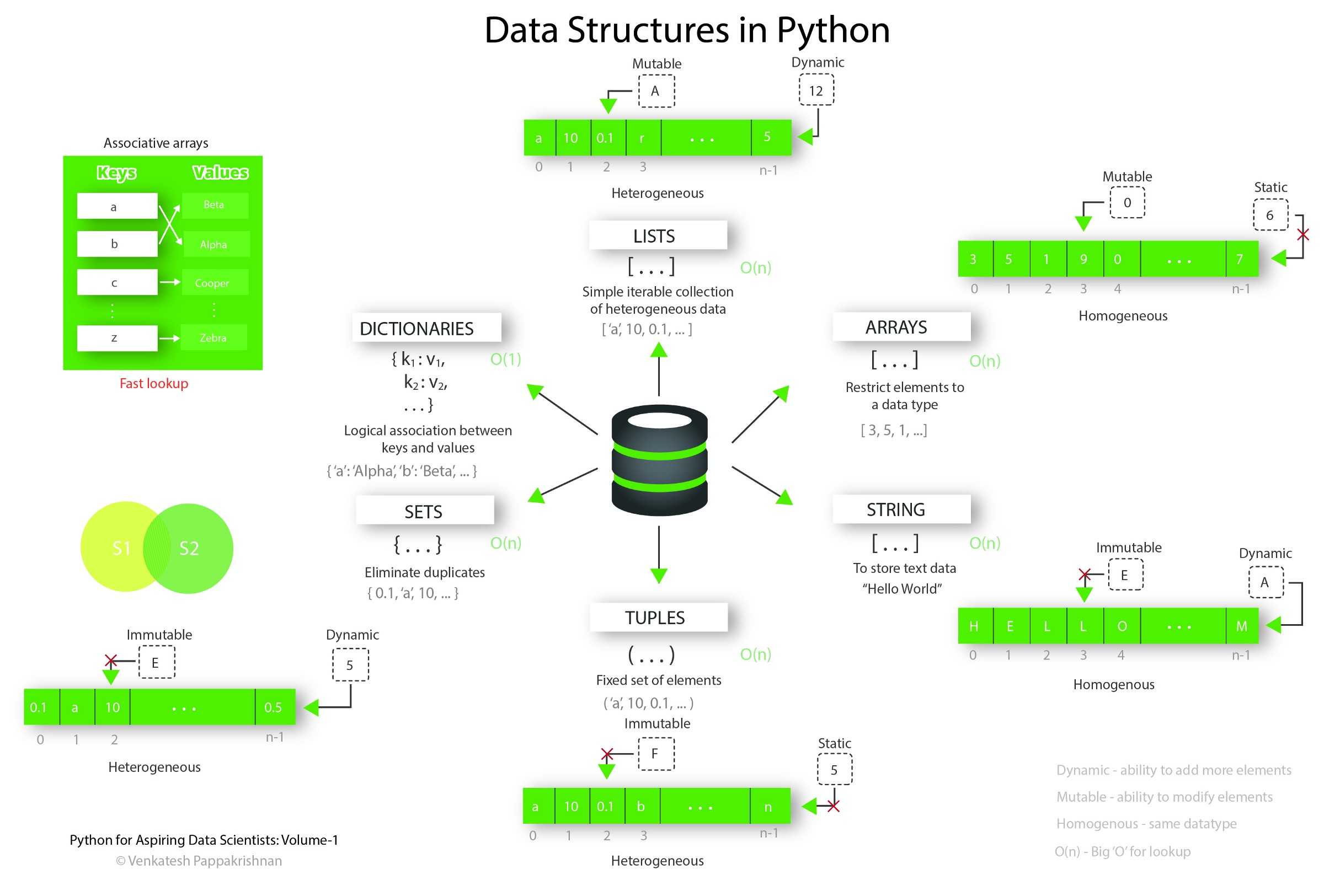
Меры описательной статистики
Задача описательной статистики, как следует из названия, — дать хорошее описание данных. Она не для предсказаний, выводов или преобразований — только внешняя форма данных, измеренная в показателях.
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, ), — это:
- Среднее: чаще всего вычисляется как среднее арифметическое. Просто складываем все значения, делим на их количество — и вуаля, средняя температура по больнице готова.
- Медиана: если выстроить все данные по возрастанию и найти середину этого ряда, это как раз и будет медиана. Одна половина из значений данных будет больше медианы, а другая — меньше.
- Мода: значение в наборе данных, которое встречается чаще всего. Запомнить очень легко: мода — самое популярное из значений, то, что «носят все».
![]()
Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, . Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.
Сравнение понижающей дискретизации и повышающей дискретизации в методе интерполяции — три канала RGB.
Для исходного изображения исходное изображение подвергается понижающей дискретизации, а затем повышающей дискретизации в соответствии с коэффициентом масштабирования, равным 3. Цветное изображение, считываемое matlab, является трехканальным изображением RGB, и операции повышения и понижения частоты дискретизации выполняются на каждом отдельном канале отдельно. Результаты в следующей таблице получены с использованием соответствующего метода интерполяции.результатпротивИсходное изображение (наземная правда)Результат сравнения:
| down|up | nearest | bilinear | bicubic | lanczos2 | lanczos3 |
| nearest | 28.320/0.834 | 30.331/0.883 | 30.214/0.882 | 30.207/0.882 | 30.026/0.876 |
| bilinear | 29.342/0.852 | 30.382/0.876 | 30.742/0.885 | 30.749/0.885 | 30.893/0.889 |
| bicubic | 29.241/0.851 | 30.996/0.893 | 30.918/0.890 | 30.912/0.890 | 30.667/0.883 |
| lanczos2 | 29.238/0.851 | 30.671/0.883 | 30.915/0.890 | 30.920/0.890 | 30.998/0.893 |
| lanczos3 | 29.089/0.848 | 30.775/0.886 | 30.939/0.891 | 30.944/0.891 | 30.968/0. |
Наблюдаемые дефекты интерполяции
Все неадаптивные интерполяторы пытаются подобрать оптимальный баланс между тремя нежелательными дефектами: граничными гало, размытием и ступенчатостью.
|
Оригинал |
||||
| ступенчатость | размытие | гало |
Даже наиболее развитые неадаптивные интерполяторы всегда вынуждены увеличивать или уменьшать один из вышеприведенных дефектов за счёт двух других — как следствие, как минимум один из них будет заметен. Заметьте, насколько граничное гало похоже на дефект, порождаемый повышением резкости с помощью нерезкой маски, и как оно повышает кажущуюся резкость посредством усиления чёткости.
Адаптивные интерполяторы могут создавать или не создавать вышеописанные дефекты, но они тоже могут породить несвойственные исходному изображению текстуры или одиночные пиксели на крупных масштабах:
| Оригинал с малоразмерной текстурой | Участок при увеличении 220% |
С другой стороны, некоторые «дефекты» адаптивных интерполяторов тоже могут рассматриваться как преимущества. Поскольку глаз ожидает увидеть в областях с мелкой текстурой, таких как листва, детали вплоть до мельчайших подробностей, подобные рисунки могут обмануть глаз на расстоянии (для определённых видов материала).
Концепция
Суть интерполяции заключается в использовании имеющихся данных для получения ожидаемых значений в неизвестных точках. Например, если вам захотелось знать, какова была температура в полдень, но измеряли её в 11 и в час, можно предположить её значение, применив линейную интерполяцию:
Если бы у вас имелось дополнительное измерение в половине двенадцатого, вы могли бы заметить, что до полудня температура росла быстрее, и использовать это дополнительное измерение для квадратической интерполяции:
Чем больше измерений температуры вы будете иметь около полудня,тем более комплексным (и ожидаемо более точным) может быть ваш алгоритм интерполяции.
Интерполяция высшего порядка: сплайны и sinc
Есть много других интерполяторов, которые принимают во внимание больше окружающих пикселей и таким образом требуют более интенсивных вычислений. Эти алгоритмы включают в себя сплайны и кардинальный синус (sinc), и они сохраняют большинство информации об изображении после интерполяции
Как следствие, они являются исключительно полезными, когда изображение требует нескольких поворотов или изменений перспективы за отдельные шаги. Однако, для однократных увеличений или поворотов такие алгоритмы высшего порядка дают незначительное визуальное улучшение при существенном увеличении времени обработки. Более того, в некоторых случаях алгоритм кардинального синуса на гладком участке отрабатывает хуже, чем бикубическая интерполяция.
Классификация методов сэмплинга
Общепринятая классификация методов сэмплинга представлена на рис. 2.
Рисунок 2. Классификация методов сэмплинга
Все методы сэмплинга делятся на две группы — детерминированные и вероятностные (probability sampling) или случайные (random sampling). В детерминированных методах процесс формирования выборки производится в соответствии с формально заданными правилами и ограничениями. Например «выбрать всех мужчин в возрасте от 30 до 40 лет». Тогда все объекты, удовлетворяющие правилу будут помещены в выборку обязательно. В вероятностных методах для каждого объекта определяется вероятность, с которой он может быть взят в выборку.

![[масштабирование изображения] бикубическая (кубическая) свертка с интерполяцией - русские блоги](https://fuzeservers.ru/wp-content/uploads/7/7/8/7785c4a64ab1c88a4f863a66662e554d.jpeg)
Сравнение сходства между методами интерполяции
Для художественного изображения с исходным размером 1390 × 1110 исходное изображение подвергается понижающей дискретизации в соответствии с коэффициентом масштабирования 3 для получения изображения с низким разрешением. Используйте разные методы интерполяции, чтобы выполнить эту операцию и сравнить сходство между изображениями с низким разрешением. Результаты будут следующими:
| nearest | bilinear | bicubic | lanczos2 | lanczos3 | |
| nearest | 35.115/0.963 | 36.004/0.969 | 35.973/0.968 | 35.961/0.968 | |
| bilinear | 45.604/0.997 | 45.486/0.997 | 41.652/0.992 | ||
| bicubic | 63.529/0.999 | 48.558/0.998 | |||
| lanczos2 | 48.763/0.998 | ||||
| lanczos3 |
Сглаживание, вызванное масштабированием
Вдобавок к дефектам муара, масштабированное изображение может также стать значительно менее резким. Алгоритмы интерполяции, которые лучше сохраняют резкость, одновременно больше подвержены муару, тогда как те, которые исключают муар, обычно дают более мягкий результат. К сожалению, такого компромисса при масштабировании избежать невозможно.
| Оригинал | Размытие при изменении размера |
Один из наилучших способов бороться с этим — это применить сразу после масштабирования маску нерезкости — даже если оригинал уже подвергался повышению резкости. Наведите курсор на вышеприведенный снимок, чтобы увидеть, как это может восстановить утраченную резкость.
2.5.5. Независимый компонентный анализ (ICA)
Независимый компонентный анализ разделяет многомерный сигнал на аддитивные подкомпоненты, которые максимально независимы. Это реализовано в scikit-learn с использованием алгоритма . Обычно ICA используется не для уменьшения размерности, а для разделения наложенных сигналов. Поскольку модель ICA не включает термин «шум», для того, чтобы модель была правильной, необходимо применить отбеливание. Это можно сделать внутренне, используя аргумент whiten, или вручную, используя один из вариантов PCA.
Он обычно используется для разделения смешанных сигналов (проблема, известная как слепое разделение источников ), как в примере ниже:
![]()
ICA также можно использовать как еще одно нелинейное разложение, которое находит компоненты с некоторой разреженностью:
![]()
![]()
Примеры:
- Слепое разделение источников с использованием FastICA
- FastICA для двумерных облаков точек
- Разбиение набора данных Faces
Оптический и цифровой зум
Многие компактные цифровые камеры могут осуществлять как оптическое, так и цифровое увеличение (зум). Оптический зум осуществляется движением вариобъектива, так чтобы свет усиливался до попадания на цифровой сенсор. На контрасте, цифровой зум понижает качество, поскольку осуществляет простую интерполяцию изображения — уже после получения его сенсором.
Оптический зум (х10) Цифровой зум (х10)
Даже несмотря на то, что фото с использованием цифрового зума содержит то же число пикселей, его детальность отчётливо меньше, чем при использовании оптического зума.Цифровой зум следует практически полностью исключить, за вычетом случаев, когда он помогает отобразить удалённый объект на ЖК-экране вашей камеры. С другой стороны, если вы обычно снимаете в JPEG и хотите впоследствии обрезать и увеличить снимок, цифровой зум имеет преимущество в том, что его интерполяция осуществляется до внесения дефектов компрессии. Если вы обнаруживаете, что цифровой зум вам нужен слишком часто, купите телеконвертор, а ещё лучше объектив с большим фокусным расстоянием.
Алгоритм бикубической свертки
Бикубическая сплайн-интерполяция требует решения линейной системы, описанной выше, для каждой ячейки сетки. Интерполятор с аналогичными свойствами может быть получен путем применения свертки со следующим ядром в обоих измерениях:
- W(Икс)знак равно{(а+2)|Икс|3-(а+3)|Икс|2+1для |Икс|≤1,а|Икс|3-5а|Икс|2+8а|Икс|-4адля 1<|Икс|<2,иначе,{\ displaystyle W (x) = {\ begin {cases} (a + 2) | x | ^ {3} — (a + 3) | x | ^ {2} +1 & {\ text {for}} | x | \ leq 1, \\ a | x | ^ {3} -5a | x | ^ {2} + 8a | x | -4a & {\ text {for}} 1 <| x | <2, \\ 0 & { \ text {else}}, \ end {case}}}
где обычно устанавливается равным -0,5 или -0,75
Обратите внимание, что и для всех ненулевых целых чисел .
а{\ displaystyle a}W()знак равно1{\ Displaystyle W (0) = 1}W(п)знак равно{\ Displaystyle W (п) = 0}п{\ displaystyle n}. Этот подход был предложен Кизом, который показал, что дает сходимость третьего порядка относительно интервала дискретизации исходной функции.
азнак равно-0,5{\ displaystyle a = -0,5}
Этот подход был предложен Кизом, который показал, что дает сходимость третьего порядка относительно интервала дискретизации исходной функции.
азнак равно-0,5{\ displaystyle a = -0,5}
Если мы используем матричную запись для общего случая , мы можем выразить уравнение более удобным способом:
азнак равно-0,5{\ displaystyle a = -0,5}
- п(т)знак равно121тт2т32-112-54-1-13-31ж-1жж1ж2{\ displaystyle p (t) = {\ tfrac {1} {2}} {\ begin {bmatrix} 1 & t & t ^ {2} & t ^ {3} \\\ end {bmatrix}} {\ begin {bmatrix} 0 & 2 & 0 & 0 \ \ -1 & 0 & 1 & 0 \\ 2 & -5 & 4 & -1 \\ — 1 & 3 & -3 & 1 \\\ end {bmatrix}} {\ begin {bmatrix} f _ {- 1} \\ f_ {0} \\ f_ {1} \\ f_ {2} \\\ конец {bmatrix}}}
для одного измерения от 0 до 1
Обратите внимание, что для интерполяции одномерной кубической свертки требуется 4 точки выборки. Для каждого запроса слева находятся два образца, а справа — два образца
В этом тексте эти точки пронумерованы от -1 до 2. Расстояние от точки с индексом 0 до точки запроса обозначено здесь.
т{\ displaystyle t}т{\ displaystyle t}



Для двух измерений, которые сначала наносятся один раз и снова в :
Икс{\ displaystyle x}у{\ displaystyle y}
- б-1знак равноп(тИкс,ж(-1,-1),ж(,-1),ж(1,-1),ж(2,-1)),{\ displaystyle b _ {- 1} = p (t_ {x}, f _ {(- 1, -1)}, f _ {(0, -1)}, f _ {(1, -1)}, f _ {( 2, -1)}),}
- бзнак равноп(тИкс,ж(-1,),ж(,),ж(1,),ж(2,)),{\ displaystyle b_ {0} = p (t_ {x}, f _ {(- 1,0)}, f _ {(0,0)}, f _ {(1,0)}, f _ {(2,0) }),}
- б1знак равноп(тИкс,ж(-1,1),ж(,1),ж(1,1),ж(2,1)),{\ displaystyle b_ {1} = p (t_ {x}, f _ {(- 1,1)}, f _ {(0,1)}, f _ {(1,1)}, f _ {(2,1) }),}
- б2знак равноп(тИкс,ж(-1,2),ж(,2),ж(1,2),ж(2,2)),{\ displaystyle b_ {2} = p (t_ {x}, f _ {(- 1,2)}, f _ {(0,2)}, f _ {(1,2)}, f _ {(2,2) }),}
- п(Икс,у)знак равноп(ту,б-1,б,б1,б2).{\ displaystyle p (x, y) = p (t_ {y}, b _ {- 1}, b_ {0}, b_ {1}, b_ {2}).}
Плюсы и минусы различных видов интерполяции. Автоматический выбор метода
Подведём итоги. Самый простой и быстрый способ интерполяции – линейная интерполяция, просто соединяющая узловые точки прямыми отрезками. При подробном рассмотрении формы сигнала качество картинки неудовлетворительное, но в случаях, когда частота исследуемого сигнала невелика по сравнению с частотой дискретизации, а количество точек, изображаемых на экране, напротив, сравнимо с его разрешением, использование этого метода оправдано из-за самой высокой скорости работы.
Интерполяция сплайнами несколько медленнее линейной, но качество воспроизведения сигнала значительно выше. Используя различные методы сплайн-интерполяции, например, Бесселя для более гладкого восстановления сигнала или Акимы для минимизации ложных осцилляций, можно качественно и быстро восстанавливать низкочастотные сигналы.
Наконец, sinc-интерполяция представляет наилучшие возможности восстановления высокочастотных сигналов по минимуму узловых точек. Однако, является самой медленной из рассмотренных (например, на моём компьютере sinc-интерполяция полной осциллограммы из 64000 точек в программе AKTAKOM Oscilloscope Pro занимала чуть более трёх секунд, при этом сплайн-интерполяция той же осциллограммы – всего 250 миллисекунд). Кроме того, заведомо ограничивает спектр восстанавливаемого сигнала, что может приводить к появлению сильного звона на участках сигнала с крутыми фронтами.
Oscilloscope Pro позволяет пользователю как самостоятельно выбрать метод интерполяции, который он считает наиболее подходящим для его условий измерений (или вовсе выключить интерполяцию), так и указать программе автоматически выбирать метод в зависимости от параметров сигнала.
![]()
Афонский А.А.Суханов Е.В.КИПиС 2010 № 5
Алгоритм CLOPE
Пусть имеется база транзакций D, состоящая из множества транзакций \{ t_1,t_2,…,t_n \}. Каждая транзакция есть набор объектов \{ i_1,…,i_m \}. Множество кластеров \{ C_1,…,C_k \} есть разбиение множества \{ t_1,…,t_n \}, такое, что C_1…C_k = \{ t_1,…,t_n \} и C_i\neq \varnothing \wedge C_i \bigcap C_j = \varnothing, для 1<=i, j<=k. Каждый элемент C_i называется кластером, n, m, k — количество транзакций, количество объектов в базе транзакций и число кластеров соответственно.
Каждый кластер C имеет следующие характеристики:
- D(C) — множество уникальных объектов;
- Occ(i,C) — количество вхождений (частота) объекта i в кластер C;
- S(C)=\sum_{i\in\ D(C)}\ Occ\ (i, C)=\sum_{t_i\in C}\mid t_i \mid;
- W (C) = | D (C) |;
- H(C)=S(C)/W(C).
Гистограммой кластера C называется графическое изображение его расчетных характеристик: по оси OX откладываются объекты кластера в порядке убывания величины Occ(i,C), а сама величина Occ(i,C) — по оси OY (рис. 2).
Рисунок 2. Иллюстрация гистограммы кластера
На рис. 2 S(C)=8, соответствует площади прямоугольника, ограниченного осями координат и пунктирной линией. Очевидно, что чем больше значение H, тем более «похожи» две транзакции. Поэтому алгоритм должен выбирать такие разбиения, которые максимизируют H.
Однако учитывать одно только значение высоты H недостаточно. Возьмем базу, состоящую из 2-х транзакций: \{ abc,def \}. Они не содержат общих объектов, но разбиение \{ \{abc,def \} \} и разбиение \{ \{ abc \}, \{ def \} \} характеризуются одинаковой высотой H=1. Получается, оба варианта разбиения равноценны. Но если для оценки вместо H(C) использовать градиент G(C)=H(C)/W(C)=S(C)/W(C)^2, то разбиение \{ \{ abc \}, \{ def \} \} будет лучше (градиент каждого кластера равен 1/3 против 1/6 у разбиения \{ \{ abc,def \} \}).
Обобщив вышесказанное, запишем формулу для вычисления глобального критерия – функции стоимости Profit(C):
Profit (C) = \frac {\sum_{i=1}^k G(C_i)\times\mid C_i\mid}{\sum_{i=1}^k \mid C_i\mid}=\frac {\sum_{i=1}^k \frac{S(C_i)}{W(C_i)^r}\times\mid C_i\mid}{\sum_{i=1}^k \mid C_i\mid}
где:
- |Ci| — количество транзакций в i-том кластере
- k — количество кластеров
- r — положительное вещественное число большее 1.
С помощью параметра r, названного авторами CLOPE коэффициентом отталкивания (repulsion), регулируется уровень сходства транзакций внутри кластера, и, как следствие, финальное количество кластеров. Этот коэффициент подбирается пользователем. Чем больше r, тем ниже уровень сходства и тем больше кластеров будет сгенерировано.
Формальная постановка задачи кластеризации алгоритмом CLOPE выглядит следующим образом: для заданных D и r найти разбиение C: Profit(C,r) -> max.
Определение
Ядро Ланцоша
Окна Ланцоша для a = 1, 2, 3.
Ядра Ланцоша для случаев a = 2 и a = 3. Отметим, что функция принимает отрицательные значения.
Влияние каждой входной выборки на интерполированные значения определяется ядром восстановления фильтра L ( x ) , называемым ядром Ланцоша. Это нормализованное синк функция синк ( х ) , оконный (умножается) на окне Ланцоша ,или окно sinc , которое является центральным лепестком горизонтально растянутой функции sinc sinc ( x / a ) для — a ≤ x ≤ a .
- L(Икс)знак равно{грех(Икс)грех(Икса)если -а<Икс<а,иначе.{\ displaystyle L (x) = {\ begin {cases} \ operatorname {sinc} (x) \ operatorname {sinc} (x / a) & {\ text {if}} \ -a <x <a, \\ 0 & {\ text {иначе}}. \ End {case}}}
Эквивалентно,
- L(Икс)знак равно{1если Иксзнак равно,агрех(πИкс)грех(πИкса)π2Икс2если -а≤Икс<а а также Икс≠,иначе.{\ Displaystyle L (x) = {\ begin {cases} 1 & {\ text {if}} \ x = 0, \\ {\ dfrac {a \ sin (\ pi x) \ sin (\ pi x / a) } {\ pi ^ {2} x ^ {2}}} & {\ text {if}} \ -a \ leq x <a \ {\ text {and}} \ x \ neq 0, \\ 0 & {\ текст {иначе}}. \ end {case}}}
Параметр a — положительное целое число, обычно 2 или 3, которое определяет размер ядра. Ядро Ланцоша имеет 2 доли а — 1 : положительную в центре и по 1 чередующихся отрицательных и положительных долей с каждой стороны.
Формула интерполяции
Учитывая одномерный сигнал с отсчетами s i , для целых значений i значение S ( x ), интерполированное с произвольным вещественным аргументом x , получается дискретной сверткой этих отсчетов с ядром Ланцоша:
- S(Икс)знак равно∑язнак равно⌊Икс⌋-а+1⌊Икс⌋+аsяL(Икс-я),{\ Displaystyle S (х) = \ сумма _ {я = \ lfloor x \ rfloor -a + 1} ^ {\ lfloor x \ rfloor + a} s_ {i} L (xi),}
где a — параметр размера фильтра, а — минимальная функция . Границы этой суммы таковы, что вне них ядро равно нулю.
⌊Икс⌋{\ displaystyle \ lfloor x \ rfloor}
Основные этапы построения выборки
Какой-либо универсальной, подходящей для всех задач анализа, последовательности действий при реализации процесса сэмплинга, вообще говоря, указать нельзя. Но наиболее типичной является следующая последовательность шагов.
Определение генеральной совокупности. На данном этапе аналитик должен определить из каких объектов будет состоять совокупность (людей, домохозяйств, предприятий, товаров и т.д.), какими признаками они характеризуются, а также произвести географическую и временную привязку. В некоторых случаях может возникнуть ситуация, когда совокупность может содержать наблюдения, которые будут являться следствием наблюдением другой совокупности (суперсовокупности). При этом совокупность и суперсовокупность могут частично перекрываться.
Определение основы выборки (sampling frame). В простейшем случае, в выборку может быть включен любой элемент совокупности — это называется прямым отбором. Однако на практике может оказаться полезным сформировать так называемую основу выборки — часть генеральной совокупности, элементы которой удовлетворяют требованиям решаемой задачи. Например, это могут быть люди старше 18 лет, клиенты с доходом выше среднего по региону и т.д. Возможно требование, чтобы каждый элемент совокупности попадал в основу выборки только один раз. Применяется показатель инцидентности (охвата) выборки, равный процентной доле генеральной совокупности, которая будет использоваться для отбора.
Выбор метода и алгоритма сэмплинга (план выборки). Этот выбор не всегда очевиден и однозначен. На практике приходится использовать опыт решения аналогичных задач, либо выбирать лучший метод экспериментально. Кроме этого выбранный метод зависит от типа данных и количества объектов.
Определение объёма выборки. Зависит от многих факторов. Например, в статистических методах исследования объём выборки должен обеспечивать возможность оценки законов распределения данных и их параметров. В машинном обучении объём обучающей выборки должен обеспечивать её полноту и репрезентативность, а также может зависеть от особенностей модели. Например, число примеров обучающей выборки для обучения нейронной сети должно превышать число межнейронных связей, которые настраиваются в процессе обучения. В противном случает сеть не приобретёт обобщающей способности.
Реализация процесса сэмплинга. Также имеет свои особенности. Например отбор наблюдений может производится из локальных или удалённых источников. Во втором случае процесс извлечения выборок больших объёмов может сопровождаться повышением нагрузки на сеть компании. Поэтому его лучше реализовывать в соответствии с наиболее безопасным временным регламентом
Кроме этого в процессе сэмплинга может произойти разрыв соединения, поэтому важно, чтобы после его восстановления процесс можно было продолжить, а не начинать сначала.
Сбор данных по отобранным объектам (если это необходимо). В некоторых случаях в процессе сэмплинга отбираются только идентификаторы объектов
Например, клиенты для опроса могут сначала отбираться по номерам клиентских карт, а потом в ходе опроса определяются их пол, возраст, доход и т.д.
Сравнение понижающей и повышающей дискретизации в канале яркости метода интерполяции y, преобразованном с помощью rgb2ycbcr
Для исходного изображения сначала преобразуйте считываемое цветное изображение RGB в трехканальное ycbcr с помощью функции rgb2ycbcr из matlab, а затем разделите канал y, и только уменьшите разрешение канала y, а затем увеличьте дискретизацию. Результаты в следующей таблице получены с использованием соответствующего метода интерполяции на канале y.результатпротивY-канал исходного изображенияРезультат сравнения:
| down|up | nearest | bilinear | bicubic | lanczos2 | lanczos3 |
| nearest | 28.320/0.834 | 30.331/0.883 | 30.214/0.882 | 30.207/0.882 | 30.026/0.876 |
| bilinear | 29.342/0.852 | 30.382/0.876 | 30.742/0.885 | 30.749/0.885 | 30.893/0.889 |
| bicubic | 29.241/0.851 | 30.996/0.893 | 30.918/0.890 | 30.912/0.890 | 30.667/0.883 |
| lanczos2 | 29.238/0.851 | 30.671/0.883 | 30.915/0.890 | 30.920/0.890 | 30.998/0.893 |
| lanczos3 | 29.089/0.848 | 30.775/0.886 | 30.939/0.891 | 30.944/0.891 | 30.968/0.892 |
Заключение
Data Science — не просто комбинирование модных моделей в Jupyter-ноутбуке. Профессионалы в этой области глубоко понимают природу данных и то, как они могут помочь в принятии конкретных бизнес-решений.
Всё это изучалось в статистике задолго до того, как первый дата-сайентист набрал свой первый import pandas as pd. Статистика — фундамент всей современной науки о данных, включая машинное обучение, глубокие нейросети и даже искусственный интеллект.
В нашем курсе «Профессия Data Scientist» статистике уделено самое пристальное внимание. Вы не ударите в грязь лицом ни на тусовке статистиков, ни на настоящем DS-собеседовании
Приходите!





