
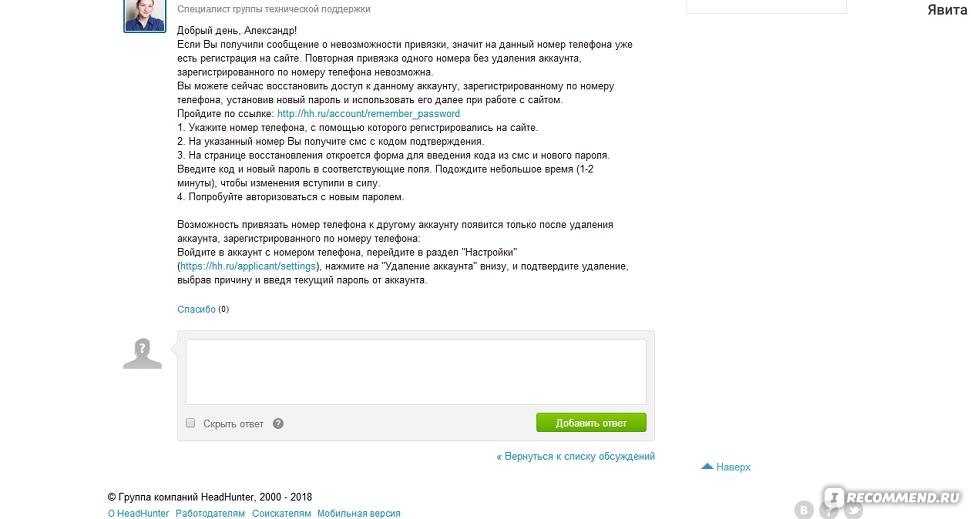
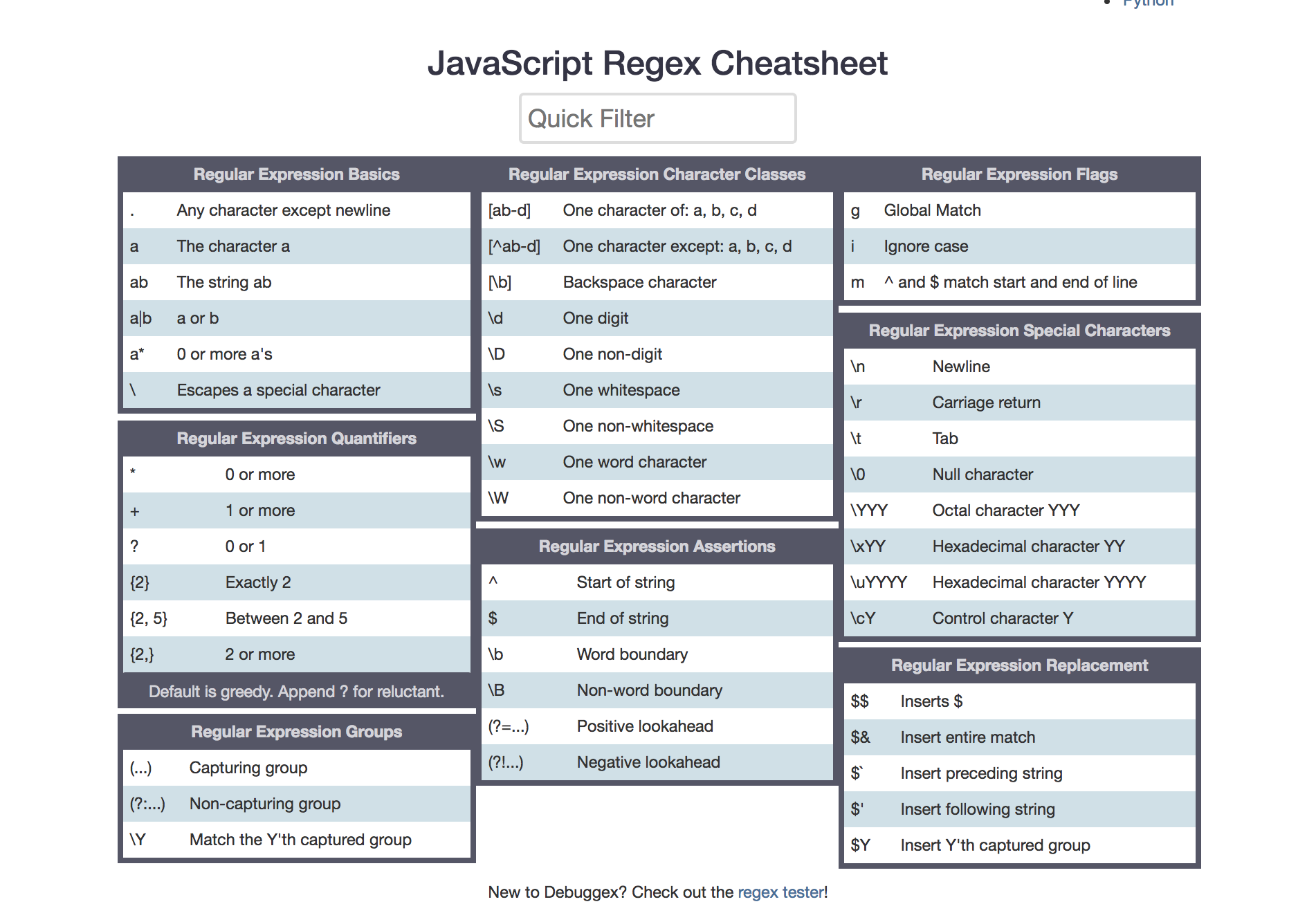
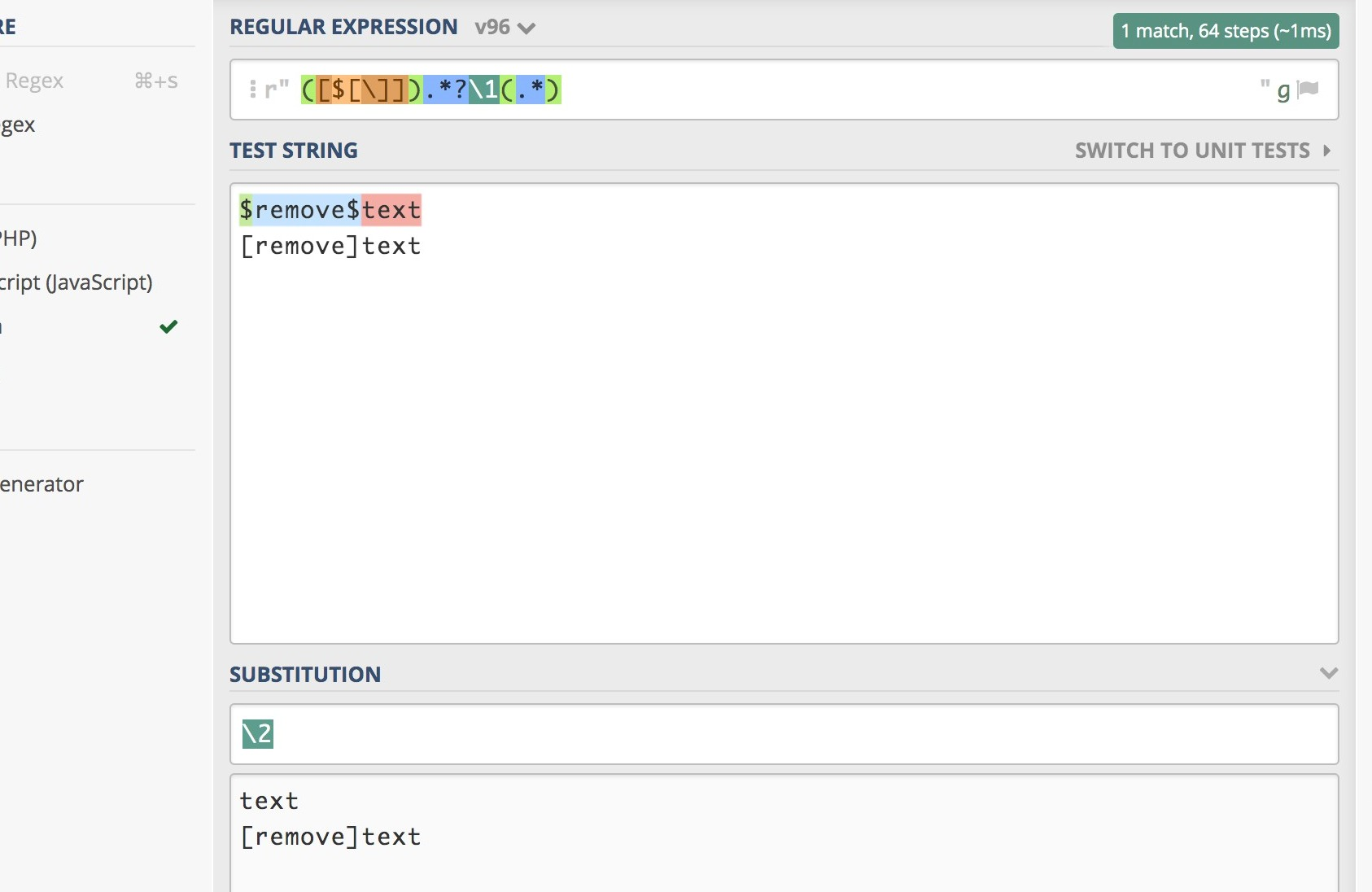
Сопоставление и поиск
Чтобы регулярное выражение соответствовало целевой последовательности, все данное выражение должно соответствовать целевой последовательности целиком. Например, регулярное выражение соответствует целевой последовательности, но не соответствует целевой последовательности или целевой последовательности .
Для успешного поиска регулярного выражения одна из частей целевой последовательности должна соответствовать данному регулярному выражению. Обычно результатом поиска является крайняя левая соответствующая часть последовательности.
Примеры:
-
Поиск регулярного выражения в целевой последовательности выполняется правильно и соответствует всей последовательности. Тот же поиск в целевой последовательности также будет выполнен, и в нем будут сопоставлены последние три символа. Такой же поиск в целевой последовательности также будет выполнен и соответствует первым трем символам.
-
Поиск регулярного выражения в целевой последовательности выполняется правильно и соответствует первым трем символам.
При наличии нескольких подследовательностей, совпадающих в одном месте целевой последовательности, существует два способа выбора соответствующего шаблона.
Первое соответствие выбирает часть последовательности, найденную первой при установке соответствия с регулярным выражением.
Наиболее длинное соответствие выбирает самую длинную часть последовательности из соответствующих в данном положении. Если имеется более одной подпоследовательности с максимальной длиной, самое длинное совпадение выбирает тот, который был найден первым.
Например, при использовании первого совпадения поиск регулярного выражения в целевой последовательности соответствует подпоследовательности, поскольку левый термин чередования соответствует этой подпоследовательности, поэтому первое совпадение не пытается использовать правое условие чередования. При использовании наиболее длинного совпадения совпадение поиска совпадает с тем, что больше .
Частичное совпадение завершается успешно, если совпадение достигает конца целевой последовательности без ошибок, даже если оно не достигло конца регулярного выражения. Поэтому после успешного частичного совпадения добавление символов в конец целевой последовательности может вызвать ошибку последующего частичного соответствия. Однако после сбоя частичного совпадения Добавление символов в целевую последовательность не может привести к успешному завершению частичного совпадения. Например, при частичном совпадении соответствует целевой последовательности, но не .
Сокращение шаблонов с квантификаторами
В regex есть понятие квантификаторов, который указывает количество повторений символа слева. Квантификаторы помещаются в фигурные скобки {}. В зависимости от ситуации квантификаторы могут работать по разному:
- {1,3} — значение повторяется от 1 до 3 раз;
- {2} — значение слева повторяется два раза;
- {2,} — повторяется минимум 2 раза.
Можно сократить один из шаблонов, который был написан выше до этого:
![]()
Обратите внимание, что в следующем сценарии у нас вернутся все значения т.к. во всех них есть 3 цифры:
![]()
Кроме квантификаторов вы можете использовать другие метасимволы:
- + эквивалентен {1,} , что значит повторение более одного раза;
- * эквивалентно {0,} , повторение неограниченного количества раз;
- ? тоже что и {0,1} , повторение или отсутствие символа.
Задача2 – Даты
Предположим, что ведется журнал посещения сотрудниками научных конференций (см. файл примера лист Даты ).
![]()
К сожалению, столбец Дата посещения не отсортирован и необходимо выделить дату первого и последнего посещения каждого сотрудника. Например, сотрудник Козлов первый раз поехал на конференцию 24.07.2009, а последний раз – 18.07.2015.
Сначала создадим формулу для условного форматирования в столбцах В и E. Если формула вернет значение ИСТИНА, то соответствующая строка будет выделена, если ЛОЖЬ, то нет.
В столбце D создана формула массива = МАКС(($A7=$A$7:$A$16)*$B$7:$B$16)=$B7 , которая определяет максимальную дату для определенного сотрудника.
Примечание: Если нужно определить максимальную дату вне зависимости от сотрудника, то формула значительно упростится = $B7=МАКС($B$7:$B$16) и формула массива не понадобится.
Теперь выделим все ячейки таблицы без заголовка и создадим правило Условного форматирования . Скопируем формулу в правило (ее не нужно вводить как формулу массива!).
![]()
Теперь предположим, что столбец с датами отсортировали и требуется выделить строки у которых даты посещения попадают в определенный диапазон.
![]()
Для этого используйте формулу =И($B23>$E$22;$B23
Для ячеек Е22 и Е23 с граничными датами (выделены желтым) использована абсолютная адресация $E$22 и $E$23. Т.к. ссылка на них не должна меняться в правилах УФ для всех ячеек таблицы.
Для ячейки В22 использована смешанная адресация $B23, т.е. ссылка на столбец В не должна меняться (для этого стоит перед В знак $), а вот ссылка на строку должна меняться в зависимости от строки таблицы (иначе все значения дат будут сравниваться с датой из В23 ).
Таким образом, правило УФ например для ячейки А27 будет выглядеть =И($B27>$E$22;$B27 , т.е. А27 будет выделена, т.к. в этой строке дата из В27 попадает в указанный диапазон (для ячеек из столбца А выделение все равно будет производиться в зависимости от содержимого столбца В из той же строки – в этом и состоит “магия” смешанной адресации $B23).
А для ячейки В31 правило УФ будет выглядеть =И($B31>$E$22;$B31 , т.е. В31 не будет выделена, т.к. в этой строке дата из В31 не попадает в указанный диапазон.
Виталий решил открыть депозит, но в Петропавловске-Камчатском, где он живет, банки предлагают по вкладам не больше 4,5% годовых.
А его сестра Наталья, которая переехала в Калининград, рассказывает, что там можно положить деньги в банк и под 6%. Что может сделать Виталий, чтобы стать клиентом банка, у которого нет офиса в его городе?
Выберите один верный ответ
У Виталия есть возможность открыть вклад, а также купить ценные бумаги и оформить страховые полисы в компаниях из других регионов дистанционно — через финансовый маркетплейс
Виталию придется съездить один раз в другой город, заключить договор с нужной ему финансовой организацией и дальше он сможет дистанционно с ней работать — другого выхода нет
Инвестиции — Что нужно знать инвестору 5 вопросов
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
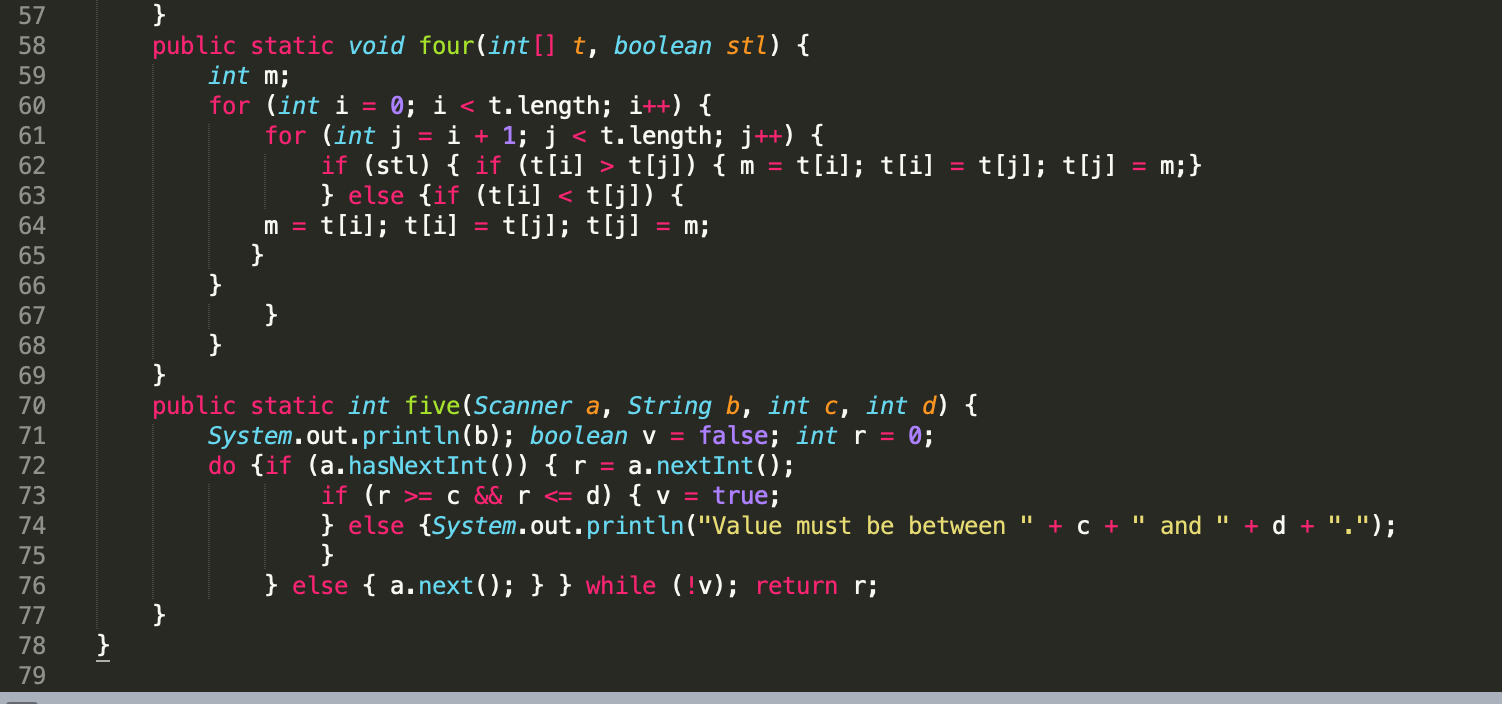
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
Как перенести текст на новую строку в Excel с помощью формулы
Иногда требуется сделать перенос строки не разово, а с помощью функций в Excel. Вот как в этом примере на рисунке. Мы вводим имя, фамилию и отчество и оно автоматически собирается в ячейке A6




Для начала нам необходимо сцепить текст в ячейках A1 и B1 ( A1&B1 ), A2 и B2 ( A2&B2 ), A3 и B3 ( A3&B3 )
После этого объединим все эти пары, но так же нам необходимо между этими парами поставить символ (код) переноса строки. Есть специальная таблица знаков (таблица есть в конце данной статьи), которые можно вывести в Excel с помощью специальной функции СИМВОЛ(число), где число это число от 1 до 255, определяющее определенный знак. Например, если прописать =СИМВОЛ(169), то мы получим знак копирайта
Нам же требуется знак переноса строки, он соответствует порядковому номеру 10 — это надо запомнить. Код (символ) переноса строки — 10 Следовательно перенос строки в Excel в виде функции будет выглядеть вот так СИМВОЛ(10)
Примечание: В VBA Excel перенос строки вводится с помощью функции Chr и выглядит как Chr(10)
Итак, в ячейке A6 пропишем формулу
= A1&B1 &СИМВОЛ(10)& A2&B2 &СИМВОЛ(10)& A3&B3
В итоге мы должны получить нужный нам результат
Обратите внимание! Чтобы перенос строки корректно отображался необходимо включить «перенос по строкам» в свойствах ячейки. Для этого выделите нужную нам ячейку (ячейки), нажмите на правую кнопку мыши и выберите «Формат ячеек…»
В открывшемся окне во вкладке «Выравнивание» необходимо поставить галочку напротив «Переносить по словам» как указано на картинке, иначе перенос строк в Excel не будет корректно отображаться с помощью формул.
Как в Excel заменить знак переноса на другой символ и обратно с помощью формулы
Можно поменять символ перенос на любой другой знак, например на пробел, с помощью текстовой функции ПОДСТАВИТЬ в Excel
Рассмотрим на примере, что на картинке выше. Итак, в ячейке B1 прописываем функцию ПОДСТАВИТЬ:
A1 — это наш текст с переносом строки; СИМВОЛ(10) — это перенос строки (мы рассматривали это чуть выше в данной статье); » » — это пробел, так как мы меняем перенос строки на пробел
Если нужно проделать обратную операцию — поменять пробел на знак (символ) переноса, то функция будет выглядеть соответственно:
Напоминаю, чтобы перенос строк правильно отражался, необходимо в свойствах ячеек, в разделе «Выравнивание» указать «Переносить по строкам».
Как поменять знак переноса на пробел и обратно в Excel с помощью ПОИСК — ЗАМЕНА
Бывают случаи, когда формулы использовать неудобно и требуется сделать замену быстро. Для этого воспользуемся Поиском и Заменой. Выделяем наш текст и нажимаем CTRL+H, появится следующее окно.
Если нам необходимо поменять перенос строки на пробел, то в строке «Найти» необходимо ввести перенос строки, для этого встаньте в поле «Найти», затем нажмите на клавишу ALT , не отпуская ее наберите на клавиатуре 010 — это код переноса строки, он не будет виден в данном поле.
После этого в поле «Заменить на» введите пробел или любой другой символ на который вам необходимо поменять и нажмите «Заменить» или «Заменить все».
Кстати, в Word это реализовано более наглядно.
Если вам необходимо поменять символ переноса строки на пробел, то в поле «Найти» вам необходимо указать специальный код «Разрыва строки», который обозначается как ^l В поле «Заменить на:» необходимо сделать просто пробел и нажать на «Заменить» или «Заменить все».
Вы можете менять не только перенос строки, но и другие специальные символы, чтобы получить их соответствующий код, необходимо нажать на кнопку «Больше >>», «Специальные» и выбрать необходимый вам код. Напоминаю, что данная функция есть только в Word, в Excel эти символы не будут работать.
Как поменять перенос строки на пробел или наоборот в Excel с помощью VBA
Рассмотрим пример для выделенных ячеек. То есть мы выделяем требуемые ячейки и запускаем макрос
1. Меняем пробелы на переносы в выделенных ячейках с помощью VBA
Sub ПробелыНаПереносы() For Each cell In Selection cell.Value = Replace(cell.Value, Chr(32) , Chr(10) ) Next End Sub
2. Меняем переносы на пробелы в выделенных ячейках с помощью VBA
Sub ПереносыНаПробелы() For Each cell In Selection cell.Value = Replace(cell.Value, Chr(10) , Chr(32) ) Next End Sub
Код очень простой Chr(10) — это перенос строки, Chr(32) — это пробел. Если требуется поменять на любой другой символ, то заменяете просто номер кода, соответствующий требуемому символу.
Коды символов для Excel
Ниже на картинке обозначены различные символы и соответствующие им коды, несколько столбцов — это различный шрифт. Для увеличения изображения, кликните по картинке.
↑ Ответы с пояснением
Приняли – принять решение, сделать выбор, вывод, дело
Роль – играть роль, но иметь значение
Принесли – принести славу, дать возможность, ощущение, уверенность и т.д.
Значения – иметь значение, играть роль
Симпатизирует – Симпатизировать – хорошо относиться к кому-либо, импонировать – производить положительное впечатление.
Оказать – нельзя дать поддержку, можно ее оказать, найти, обеспечить, получить
Взгляд – бросить взгляд
Победу – одержать победу, завоевать первенство
Совершать – совершать поступки, делать вывод, глупости , движения
Зрения – быть в поле зрения, в центре внимания
Предшествующих
Поднимается – нельзя стремительно ползти
Дать – дать ответ, выразить благодарность, мнение, мысль
Низкие – низкие цены, дешевые товары
Косяк – косяк рыб, стая птиц
Придавал – придавать значение, уделять внимание
Увеличить – увеличить выпуск продукции, повысить уровень качества
Вину – загладить вину, брать ответственность
Заслужить – заслужить уважение
Играли – играть первую скрипку
Проявить – проявить заботу, оказать внимание
Создает – создавать условия, творить дела, добро, чудеса
Неожиданным- неожиданный, внезапный отъезд, скоропостижная смерть
Выдвинуть – выдвинуть гипотезу
Нанести – нанести вред, оказать влияние
Произведений – отрывки из произведений
Принимать – принимать во внимание
Закадычный – закадычный друг, заядлый картежник
Значения – иметь значение, играть роль
Принимать – принимать/принять решение, оказать воздействие
Предложил – предложить руку и сердце
Табун – табун лошадей, рой пчел
Совершить – совершить нападение, произвести осмотр, замену, впечатление
Высказать – высказать догадку, выдвинуть гипотезу
Победу – одержать победу, первенство принадлежит к.-л.
Глаз – не смыкать глаз
Приятное – приятное впечатление
Установлено – установить рекорд, завоевать уважение, доверие, популярность
Расширить – расширить кругозор, повысить уровень знаний
Вызвал – вызвать реакцию, создать образ, условия, видимость
Преодолевать – преодолевать трудности, беда постигла
Врожденный – врожденный талант, прирожденный ум
Вызывать – вызывать аллергические реакции, навлекать беду
Выдвинуть – выдвинуть гипотезу, высказать мнение
Старом – старый сад, преклонный возраст
Открыть – открыть закон, обнаружить большое количество, пропажу
Успехи – достигнутые успехи
Присутствием – почтить присутствием
Коллекционером – коллекционер — тот, кто собирает коллекции, селекционер – человек, выводящий и совершенствующий сорта растений, породу животных или штаммы
Выгула – выгул собак, выпас овец
Бросились – броситься врассыпную
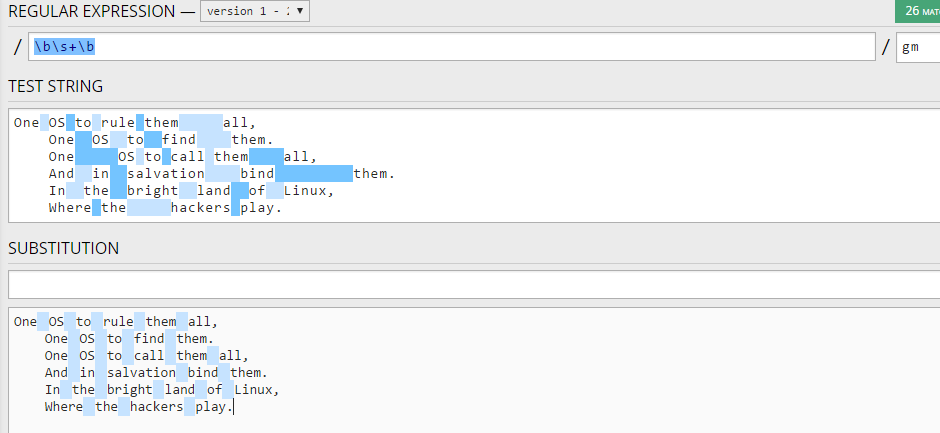
Поиск целого и обособленного слова используя шаблоны с boundaries
Я не помню что бы я использовал это на практике, но в Powershell есть возможность искать целое слово по шаблону или его часть. Такая возможность называется границами.
Представим, что нам нужно найти имя Ян в следующем предложении:
Если искать просто ‘Ян’ — мы получим неверный результат. Мы так же можем не знать, что имя упоминается с восклицательным знаком (мы можем искать это в 100 файлах). Использование точки (обозначает любой следующий символ) тоже никак не поможет:
![]()
Избежать таких ситуаций можно поместив слово между метасимволами ‘\b’, которые позволяют искать не часть, а целое слово:
![]()
Противоположный вариант, когда мы ищем не отдельное, а часть слова — в таких случаях строка экранируется в ‘\B’. В отличие от предыдущего случая этот метасимвол ставится там, где мы ожидаем продолжение или окончание слова. Хороший пример это окончания:
![]()
Эти метасимволы можно сочетать вместе для того что бы указать, где слово заканчивается и где начинается:
![]()
Сводка по грамматике
В следующей таблице приведены возможности, доступные в различных грамматиках регулярных выражений:
| Элемент | basic | extended | ECMAScript | grep | egrep | awk |
|---|---|---|---|---|---|---|
| чередование с помощью | + | + | + | + | ||
| чередование с помощью | + | + | ||||
| привязка | + | + | + | + | + | + |
| обратная ссылка | + | + | + | |||
| выражение в квадратных скобках | + | + | + | + | + | + |
| Группа записи с помощью | + | + | + | + | ||
| Группа записи с помощью | + | + | ||||
| управляющая escape-последовательность | + | |||||
| escape-символ DSW | + | |||||
| escape-выражение формата файлов | + | + | ||||
| шестнадцатеричная escape-последовательность | + | |||||
| escape-последовательность удостоверения | + | + | + | + | + | + |
| отрицательное утверждение | + | |||||
| отрицательное утверждение границы слова | + | |||||
| группа незахвата | + | |||||
| «нежадное» повторение | + | |||||
| восьмеричная escape-последовательность | + | |||||
| обычный символ | + | + | + | + | + | + |
| положительное утверждение | + | |||||
| повторение с помощью | + | + | + | + | ||
| повторение с помощью | + | + | ||||
| повторение с помощью | + | + | + | + | + | + |
| повторение с помощью и | + | + | + | + | ||
| escape-последовательность Юникода | + | |||||
| знак подстановки | + | + | + | + | + | + |
| утверждение границы слова | + |
Замена значений строк и чисел с replace
Наиболее частая задача для регулярных значений это найти и заменить какое-то значение используя шаблоны. Для таких операций используется replace, который может работать и по точному совпадению:
![]()
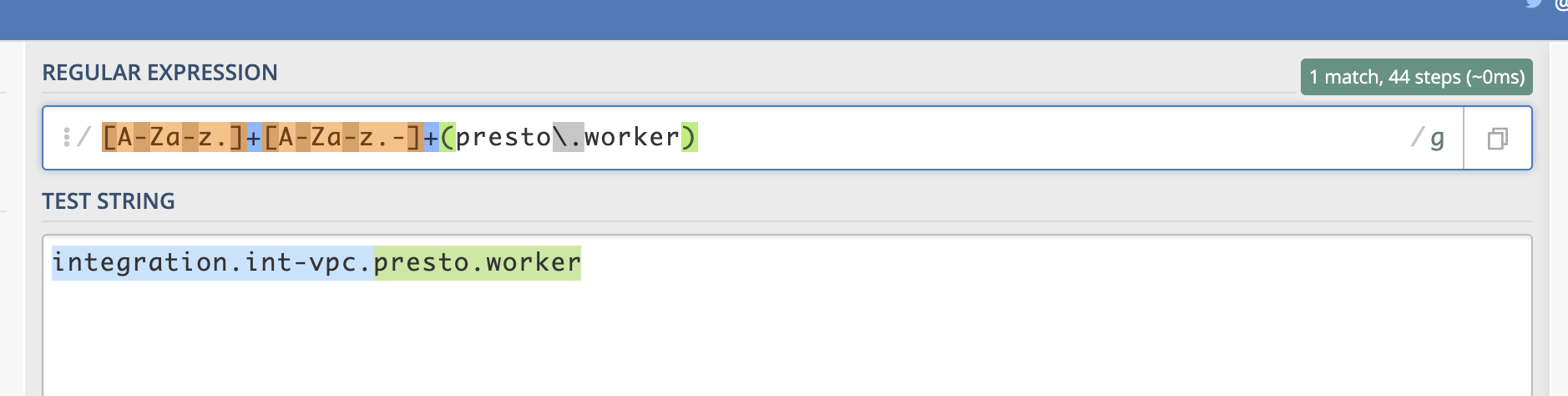
Более реальный пример — это замена ip адресов или битых ссылок. У нас может быть множество конфигурационных файлов, где используется идентификатор сети, который нужно заменить. Старые идентификаторы сети ‘192.168.3.0’ и ‘192.178.4.0’ и их нужно заменить на ‘10.10.5.0’. Следующий шаблон может сработать иначе с другими примерами:


![Regexp [айти бубен]](https://fuzeservers.ru/wp-content/uploads/0/a/c/0acd9d8e5df9148eaadfd37cb57851c0.png)

![]()
Такой шаблон сомнительное решение так как у нас может быть и DNS типа ‘192.168.5.1’ и его не нужно менять. К тому же в начале статьи было написано, что точка в регулярных выражениях обозначает любой символ, а значит следующий пример тоже сработает:
![]()
Экранирование делается через обратный слэш. В этом примере мы сделаем так, что бы у нас искалась именно точка:
![]()
По аналогии с match у replace тоже есть дополнительный параметр:
creplace — замена с учетом регистра.
Часто бывает так, что нужно заменить токи или другой зарезервированный метасимвол. Для успешной замены такие символы нужно экранировать:
![]()
Скобочные группы ― ()
a(bc) создаём группу со значением bc -> тестa(?:bc)* оперетор ?: отключает группу -> тестa(?<foo>bc) так, мы можем присвоить имя группе -> тест
Этот оператор очень полезен, когда нужно извлечь информацию из строк или данных, используя ваш любимый язык программирования. Любые множественные совпадения, по нескольким группам, будут представлены в виде классического массива: доступ к их значениям можно получить с помощью индекса из результатов сопоставления.
Если присвоить группам имена (используя ), то можно получить их значения, используя результат сопоставления, как словарь, где ключами будут имена каждой группы.
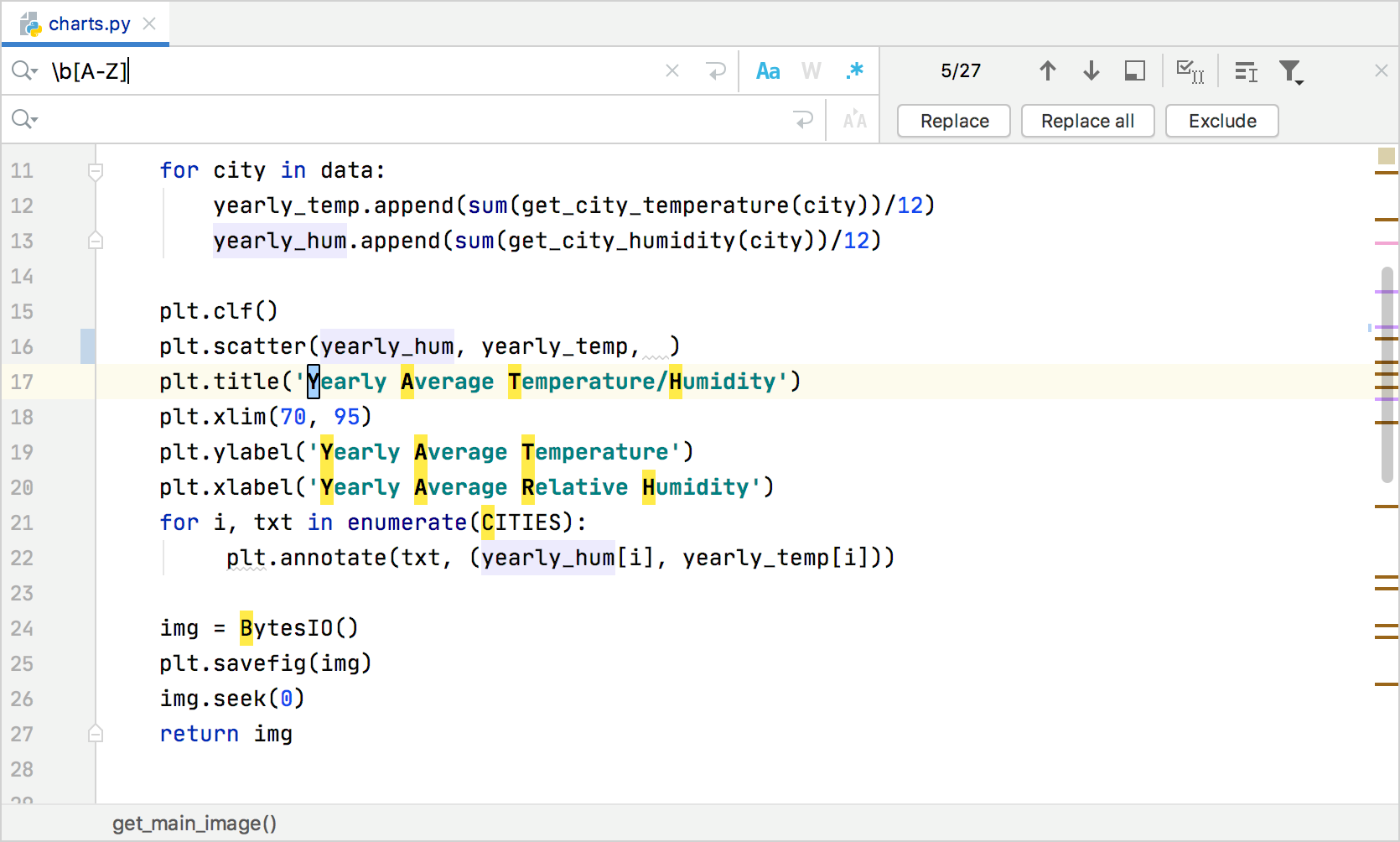
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Поиск совпадений одного из нескольких символов
Когда мы не уверены в конкретном символе — мы можем указать несколько использовав квадратные скобки [] . Значения, которые будут помещены в эти скобки будут соответствовать одному значению:
![]()
В примере выше ищутся совпадения либо по букве R или P. Можно указывать диапазон значений. Например такое написание говорит, что мы ищем цифры от 1 до 9. Если написать у нас будут искаться числа с 5 до 9, затем с 6 по 9 и т.д.
Ниже мы ищем значения, где есть буквы от ‘с’ до ‘я’, после которых есть буква ‘е’. Во втором примере мы ищем элементы массива, которые начинаются с букв ‘д’ до ‘с’:
![]()
Можно использовать любые метасимволы. В примере ниже у нас идет поиск числа или буквы, затем пробела и опять число-буквенное значение:
![]()
Вы часто можете увидеть написание похоже на следующее, что обозначает любую букву а A до z, от 0 до 9:
Альтернативы¶
Выражения в списке альтернатив разделяются .
Таким образом, будет соответствовать любому из , или (также как и ).
Первое выражение включает в себя все от последнего разделителя шаблона (, или начало шаблона) до первого , а последнее выражение содержит все от последнего к следующему разделителю шаблона.
Звучит сложно, поэтому обычной практикой является заключение списка альтернатив в скобки, чтобы минимизировать путаницу относительно того, где он начинается и заканчивается.
Выражения в списке альтернатив пробуются слева направо, принимается первое же совпадение.
Например, регулярное выражение в строке будет соответствовать — первое же совпадение.
Также помните, что в квадратных скобках воспринимается просто как символ, поэтому, если вы напишите , это тоже самое что .
Учет регистра
По умолчанию Powershell не чувствителен к регистру, а это значит что все следующие значения будут правдивы:
![]()
В большинстве языков у нас вернулось бы только одно значение так как регулярные выражения ассоциируются с учетом регистра. Что бы это исправить это в Powershell есть два варианта. Первый — использование других параметров:
- cmatch — (case sensitive match) учет регистра;
- cnotmatch — (case sensitive not match) учет регистра и поиск не совпадающих значений;
Продолжая пример и изменив ключ мы получим верный результат:
![]()
Второй вариант — использование возможностей регулярных выражений, где:
- ‘?i’ — не учитывает регистр;
- ‘?-i’ — учитывает регистр.
Отличия от параметра cmatch в том, что он работает с места объявления:
![]()
Если использовать ключ исключающий учет регистра с cmatch, то в случае ниже вернуться все значения:
![]()
Объект RegExp
Объект типа , или, короче, регулярное выражение, можно создать двумя путями
/pattern/флаги
new RegExp("pattern")
— регулярное выражение для поиска (о замене — позже), а флаги — строка из любой комбинации символов (глобальный поиск), (регистр неважен) и (многострочный поиск).
Первый способ используется часто, второй — иногда. Например, два таких вызова эквивалентны:
var reg = /ab+c/i
var reg = new RegExp("ab+c", "i")
При втором вызове — т.к регулярное выражение в кавычках, то нужно дублировать
// эквивалентны
re = new RegExp("\\w+")
re = /\w+/
При поиске можно использовать большинство возможностей современного PCRE-синтаксиса.
Вложенные условия с математическими выражениями.
Вот еще одна типичная задача: цена за единицу товара изменяется в зависимости от его количества. Ваша цель состоит в том, чтобы написать формулу, которая вычисляет цену для любого количества товаров, введенного в определенную ячейку. Другими словами, ваша формула должна проверить несколько условий и выполнить различные вычисления в зависимости от того, в какой диапазон суммы входит указанное количество товара.


Эта задача также может быть выполнена с помощью нескольких вложенных функций ЕСЛИ. Логика та же, что и в приведенном выше примере, с той лишь разницей, что вы умножаете указанное количество на значение, возвращаемое вложенными условиями (т.е. соответствующей ценой за единицу).
Предполагая, что количество записывается в B8, формула будет такая:
И вот результат:
Как вы понимаете, этот пример демонстрирует только общий подход, и вы можете легко настроить эту вложенную функцию в зависимости от вашей конкретной задачи.
Например, вместо «жесткого кодирования» цен в самой формуле можно ссылаться на ячейки, в которых они указаны (ячейки с B2 по B6). Это позволит редактировать исходные данные без необходимости обновления самой формулы:
Проверка позиций и зависимостей
Если нужно найти слово рядом с другим, то мы можем это сделать с помощью специальных символов:
- (?=Слово) — поиск слова слева;
- (?<=Слово) — поиск слова справа;
- (?!Слово) — не совпадает со словом слева;
- (?<!Слово) — не совпадает со словом слева.
Для примера мы знаем, что после слова ‘зарплату’ будут идти числа и мы хотим узнать их:
![]()
Шаблон выше обозначает:
- (?<=зарплата) — поиск слова справа от ‘зарплата’;
- \s — затем содержится символ пробела;
- \w+ — содержится число или буква один или множество раз;
- \b — слово закачивается.
Аналогичное можно сделать и со словом ‘руб’:
![]()
В этом шаблоне:
- \d+ — говорит, что у нас есть число повторяющееся один или более раз;
- \s — после числа следует пробел;
- (?=руб) — после пробела находится слово ‘руб’.
Остальные варианты нужны, когда вам нужно исключить совпадения по определенному значению.
Unicode категории (category)¶
В стандарте Unicode есть именованные категории символов (Unicode category). Категория обозначается одной буквой, и еще одна добавляется, чтобы указать подкатегорию. Например «L» это буква в любом регистре, «Lu» — буквы в верхнем регистре, «Ll» — в нижнем.
- Cc — Control
- Cf — Формат
- Co — Частное использование
- Cs — Заменитель (Surrrogate)
- Ll — Буква нижнего регистра
- Lm — Буква-модификатор
- Lo — Прочие буквы
- Lt — Titlecase Letter
- Lu — Буква в верхнем регистре
- Mc — Разделитель
- Me — Закрывающий знак (Enclosing Mark)
- Mn — Несамостоятельный символ, как умляут над буквой (Nonspacing Mark)
- Nd — Десятичная цифра
- Nl — Буквенная цифра — например, китайская, римская, руническая и т.д. (Letter Number)
- No — Другие цифры
- Pc — Connector Punctuation
- Pd — Dash Punctuation
- Pe — Close Punctuation
- Pf — Final Punctuation
- Pi — Initial Punctuation
- Po — Other Punctuation
- Ps — Open Punctuation
- Sc — Currency Symbol
- Sk — Modifier Symbol
- Sm — Математический символ
- So — Прочие символы
- Zl — Разделитель строк
- Zp — Разделитель параграфов
- Zs — Space Separator
Метасимвол это один символ указанной Unicode категории (category). Синтаксис: или если категория обозначается одним символом, для 2-символьных категорий.
Метасимвол это символ не из Unicode категории (category).





