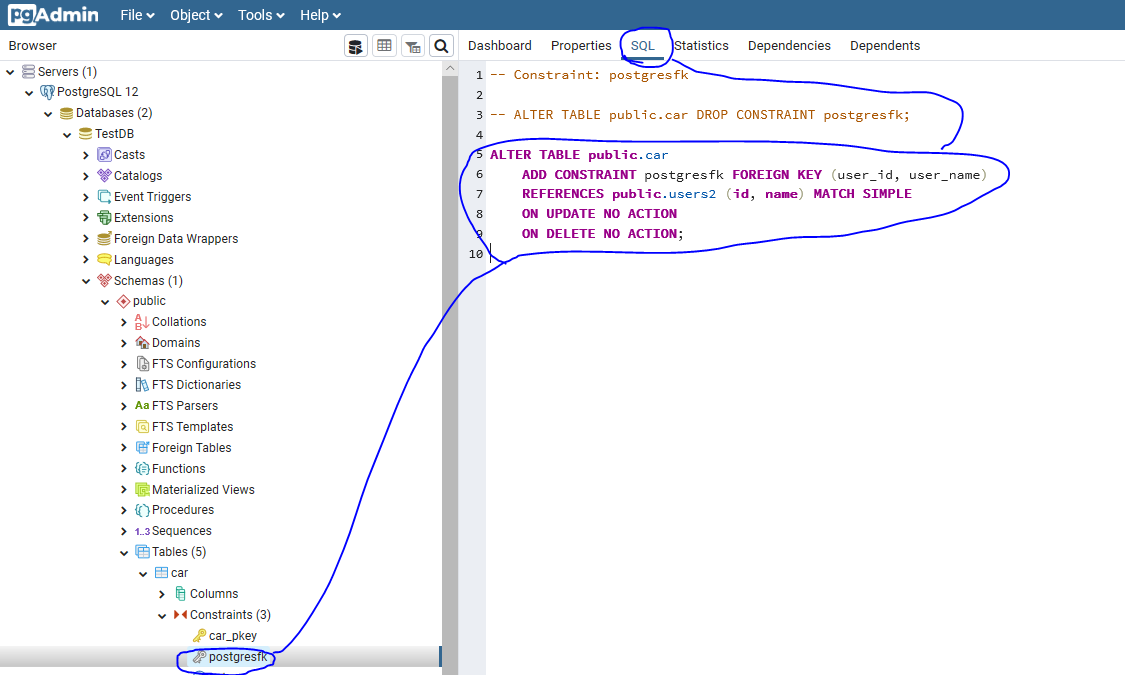
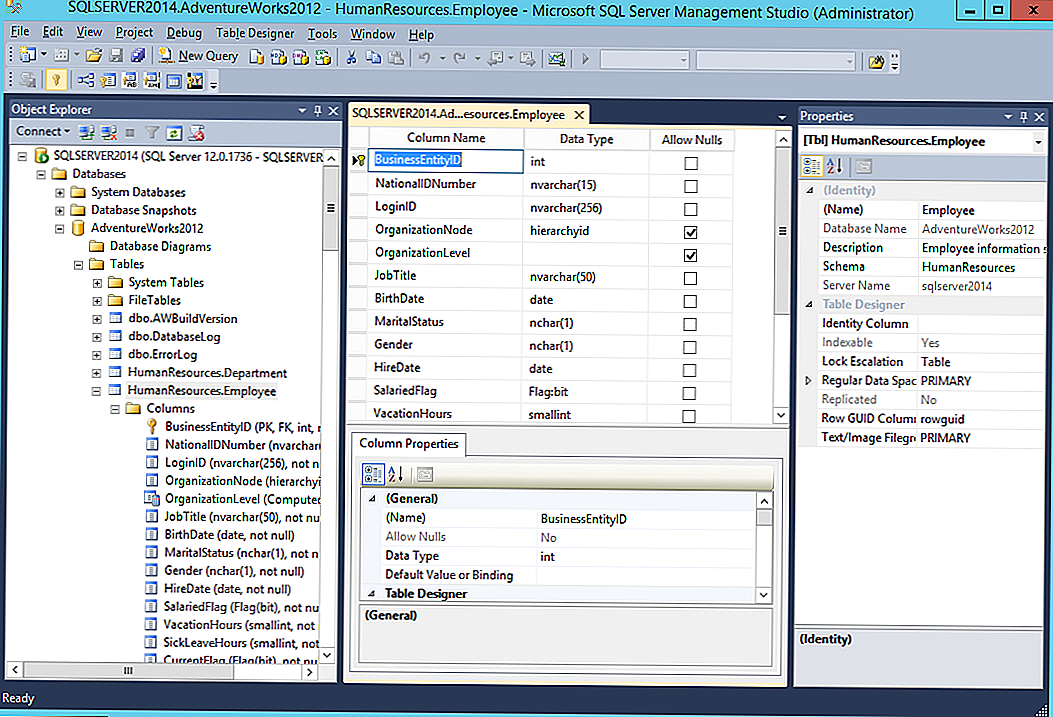
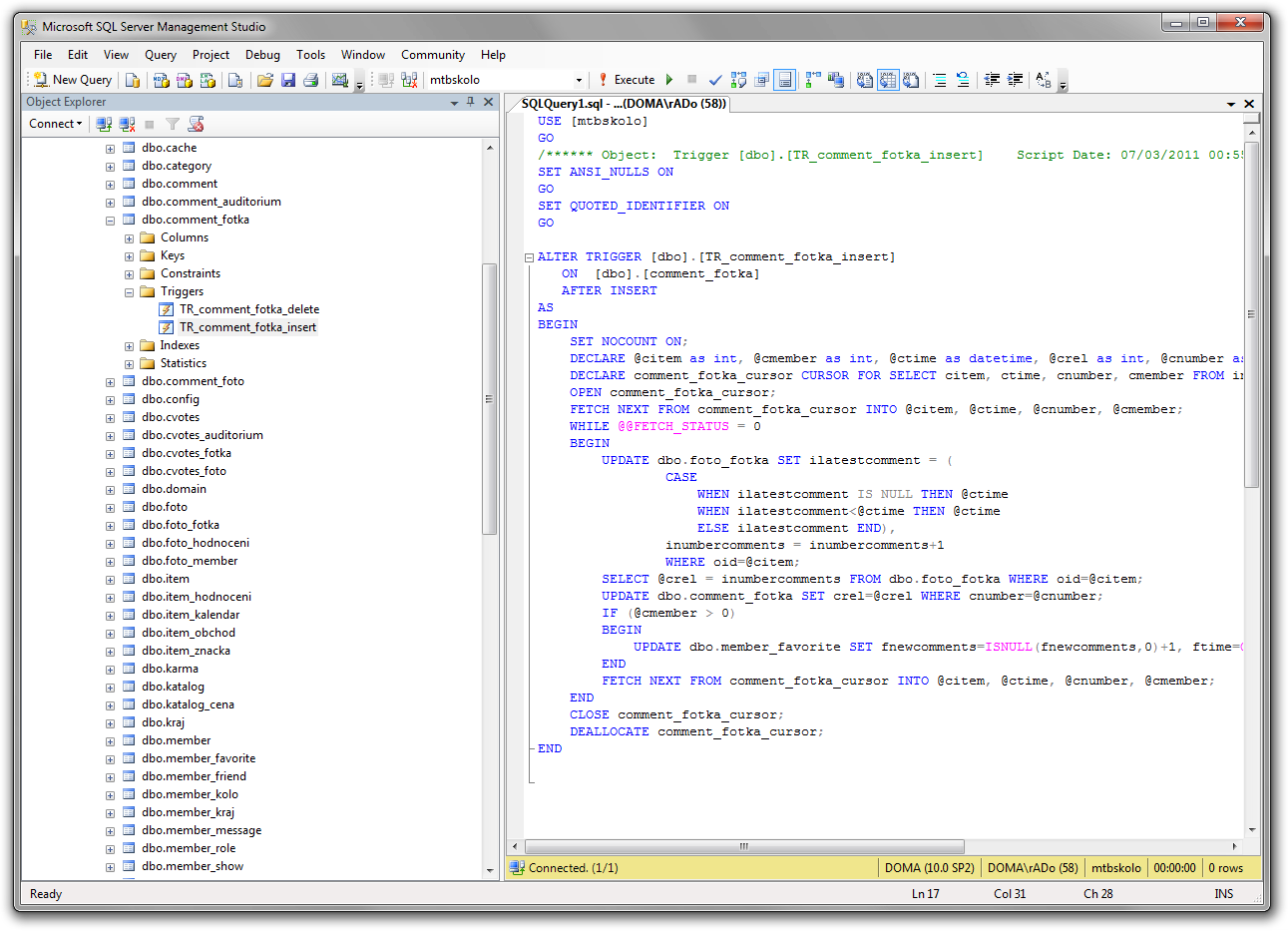
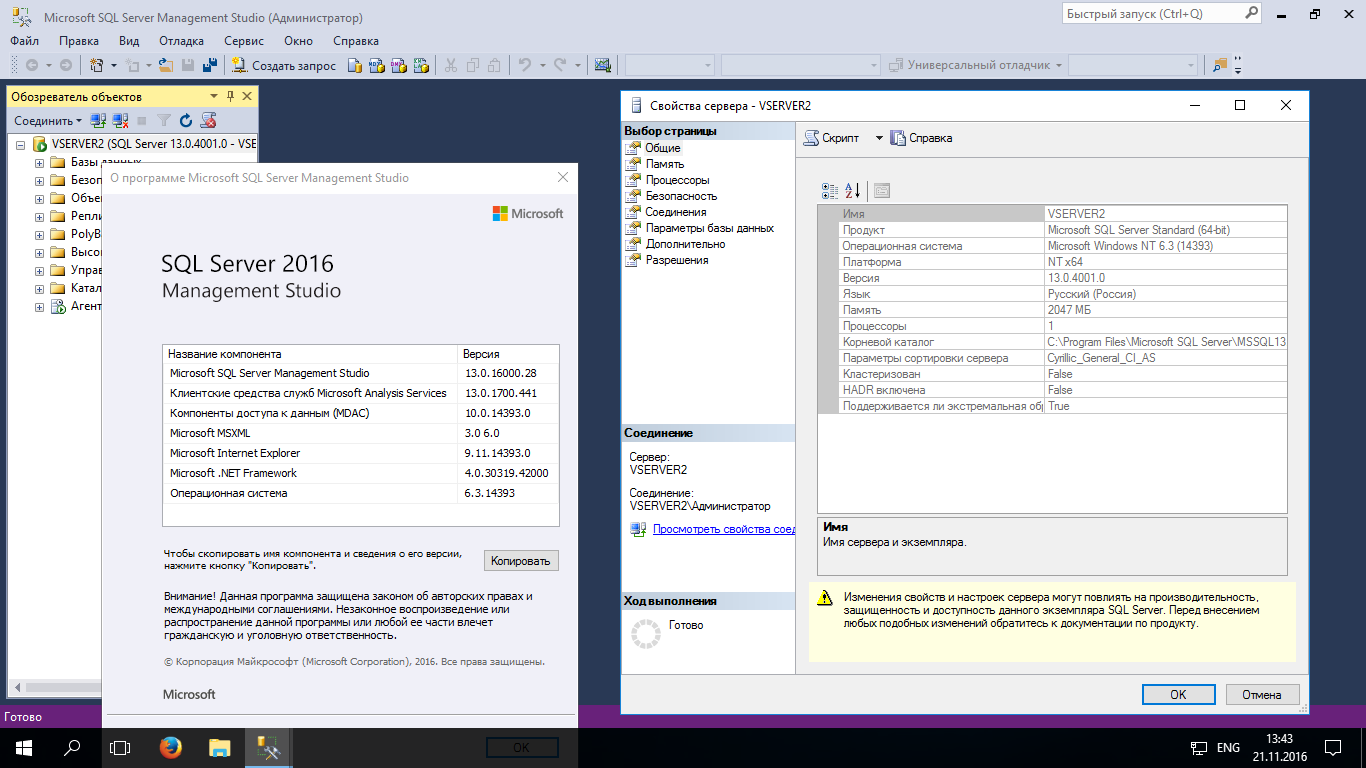
Распространенные ошибки при выборе типа данных в T-SQL
В начале статьи я говорил, что выбор неоптимального типа данных может сказаться на размере базы данных, так вот одной из самых распространенных ошибок при проектировании таблицы является выбор для столбца, который должен содержать тип данных Boolean (т.е. 0 или 1), тип SMALLINT или INT. Как Вы уже поняли, такого типа данных как Boolean в T-SQL нет, поэтому для этих целей разработчики используют похожие (подходящие) типы данных и в большинстве случаев их выбор неправильный. Если Вам нужно хранить только значения 0 или 1 (т.е. как Boolean), то в T-SQL существует специальный тип данных BIT, SQL сервер выделяет для хранения всего 1 байт, но в отличие от типа TINYINT, под который также отводится 1 байт, SQL сервер оптимизирует хранение бит столбцов. Если таблица содержит не больше 8 бит столбцов, столбцы хранятся как 1 байт, если таких столбцов от 9 до 16, то 2 байта и т.д.
Для сравнения давайте посмотрим на разницу.
Таблица 1
--В строке 16 байт
CREATE TABLE TestTable1 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled INT NOT NULL, --4 байта
IsTest INT NOT NULL, --4 байта
)
Таблица 2 (с использованием BIT столбцов)
--В строке 9 байт
CREATE TABLE TestTable2 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled BIT NOT NULL, --1 байта
IsTest BIT NOT NULL, --0 байта
)
Сравнение
| Количество строк | Размер в мегабайтах (MB) | ||
| Таблица 1 | Таблица 2 (с использованием BIT столбцов) | Разница | |
| 1 000 | 0,02 | 0,01 | 0,01 |
| 10 000 | 0,15 | 0,09 | 0,07 |
| 100 000 | 1,53 | 0,86 | 0,67 |
| 1 000 000 | 15,26 | 8,58 | 6,68 |
| 10 000 000 | 152,59 | 85,83 | 66,76 |
| 100 000 000 | 1525,88 | 858,31 | 667,57 |
Как видите, после добавления нескольких миллионов строк разница будет ощутимая, и это на простой, маленькой, тестовой таблице.
Про типы данных Microsoft SQL Server у меня все, надеюсь, материал был Вам полезен! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Нравится8Не нравится1
Аргументы
table_type_definition
То же подмножество данных, которое используется для определения таблицы с помощью инструкции CREATE TABLE. Декларация таблицы включает определения столбцов, имен, типов данных и ограничений. К допустимым типам ограничений относятся только PRIMARY KEY, UNIQUE KEY и NULL.
Дополнительные сведения о синтаксисе см. в статьях CREATE TABLE (Transact-SQL), CREATE FUNCTION (Transact-SQL) и DECLARE @local_variable (Transact-SQL).
collation_definition
Параметры сортировки столбцов, состоящие из поддерживаемых Microsoft Windows языкового стандарта и стиля сопоставления, языкового стандарта Windows и двоичной записи или параметров сортировки Microsoft SQL Server. Если значение аргумента collation_definition не задано, столбец наследует параметры сортировки текущей базы данных. Либо, если столбец определен как имеющий определяемый пользователем тип данных среды CLR, он унаследует параметры сортировки этого определяемого пользователем типа.
ограничения
Для переменных Table не предусмотрена статистика распределения. Они не будут вызывать перекомпиляцию. Во многих случаях оптимизатор строит план запроса на предположении, что у табличной переменной нет строк
По этой причине следует проявлять осторожность относительно использования табличной переменной, если ожидается большое число строк (больше 100). В этом случае временные таблицы могут быть предпочтительным решением
Для запросов, которые объединяют табличную переменную с другими таблицами, используйте указание RECOMPILE, чтобы оптимизатор использовал правильную кратность для табличной переменной.
Переменные table не поддерживаются в модели выбора на основе затрат оптимизатора SQL Server. Поэтому их не нужно использовать, если требуется принять решение на основе затрат, чтобы получить эффективный план запроса. Временные таблицы являются предпочтительными при необходимости осуществления выбора с учетом затрат. Этот план обычно включает запросы с соединениями, решения в отношении параллелизма и варианты выбора индекса.
Запросы, изменяющие переменные table, не создают параллельных планов выполнения запроса. При изменении больших переменных table или переменных table в сложных запросах может снизиться производительность. В ситуациях с изменением переменных table мы рекомендуем использовать временные таблицы. Дополнительные сведения см. в разделе CREATE TABLE (Transact-SQL). Запросы, которые считывают переменные table, не изменяя их, могут выполняться параллельно.
Важно!
Уровень совместимости базы данных 150 повышает производительность табличных переменных с введением отложенной компиляции табличных переменных. См. дополнительные сведения об .
Для переменных table нельзя явно создавать индексы, при этом статистика для переменных table не сохраняется. Начиная с SQL Server 2014 (12.x), реализован новый синтаксис, который позволяет создавать определенные встроенные типы индекса с использованием определения таблицы. С помощью этого нового синтаксиса можно создавать индексы в переменной table как часть определения таблицы. В некоторых случаях можно добиться повышения производительности за счет использования временных таблиц, которые позволяют работать с индексами и статистикой. Дополнительные сведения о временных таблицах и создании встроенных индексов см. в руководстве по использованию CREATE TABLE (Transact-SQL).
Ограничения CHECK, значения DEFAULT и вычисляемые столбцы в объявлении типа table не могут вызывать определяемые пользователем функции.
Операция присвоения между переменными table не поддерживается.
Так как переменные table имеют ограниченную область действия и не являются частью постоянной базы данных, они не изменяются при откатах транзакций.
Табличные переменные нельзя изменить после их создания.
Взаимодействие с разработчиками
SQL Server 2019 (15.x) продолжает предоставлять удобство разработки мирового класса с улучшенными возможностями для работы с диаграммами и пространственными типами данных, поддержкой UTF-8 и новой инфраструктурой расширяемости, позволяющей разработчикам использовать выбранный ими язык для извлечения ценной информации из всех их данных.
График
| Новые функции или обновления | Сведения |
|---|---|
| Действия каскадного удаления ограничений ребер | Теперь вы можете определить каскадные действия удаления для ограничения ребер в базе данных графов. См. статью Ограничения границ. |
| Новая функция графа: | Вы можете использовать в для поиска кратчайшего пути между любыми двумя узлами в графе или выполнения обходов произвольной длины. |
| Секционированные таблицы и индексы | Графовые таблицы теперь поддерживают секционирование таблиц и индексов. |
| Использование псевдонимов производной таблицы или представления для графовых запросов MATCH | См. статью MATCH (Transact-SQL). |
Поддержка Юникода
Поддержка предприятий в разных странах и регионах, где требование предоставления глобальных приложений баз данных и служб с поддержкой нескольких языков очень важно для удовлетворения потребностей клиентов и соблюдения нормативных требований конкретного рынка
| Новые функции или обновления | Сведения |
|---|---|
| Поддержка кодировки UTF-8 | Поддержка UTF-8 для импорта и экспорта кодировки, а также как параметров сортировки на уровне столбцов и базы данных для строковых данных. Включает поддержку UTF-8 для внешних таблиц PolyBase и для Always Encrypted (если не используется с анклавами). См. раздел Поддержка параметров сортировки и Юникода. |
Расширения языка
| Новые функции или обновления | Сведения |
|---|---|
| Новый SDK для языка Java | Упрощает разработку приложений Java, которые могут выполняться из SQL Server. См. статью о пакете SDK Майкрософт для расширения возможностей Java в SQL Server. |
| Пакет SDK для языка Java реализован с открытым кодом | Пакет Microsoft SDK расширяемости для Java для Microsoft SQL Server теперь имеет открытый код и доступен на GitHub. |
| Поддержка типов данных Java | См. раздел Типы данных Java. |
| Новая среда выполнения Java по умолчанию | SQL Server теперь полностью поддерживает Zulu Embedded for Java от Azul Systems. См. статью Теперь в SQL Server 2019 доступна бесплатная поддерживаемая версия Java. |
| Расширения языка для SQL Server | Выполнение внешнего кода с помощью платформы расширяемости. См. статью о расширении языка для SQL Server. |
| Регистрация внешних языков | Новый язык описания данных (DDL), , регистрирует в SQL Server внешние языки, такие как Java. См. раздел CREATE EXTERNAL LANGUAGE. |
пространственный индекс
| Новые функции или обновления | Сведения |
|---|---|
| Новые идентификаторы пространственных ссылок (SRID) |
Australian GDA2020 предоставляет более надежный и точный элемент данных, который в большей степени подходит для глобальных навигационных систем. Ниже приведены новые идентификаторы SRID:
Определения новых идентификаторов SRID см. в представлении sys.spatial_reference_systems. |
Сообщения об ошибках
При сбое процесса извлечения, преобразования и загрузки (ETL) из-за того, что источник и назначение не имеют совпадающих типов и (или) длины данных, устранение неполадок раньше занимало много времени, особенно в больших наборах данных. SQL Server 2019 (15.x) позволяет быстрее определить причины ошибок усечения данных.
| Новые функции или обновления | Сведения |
|---|---|
| Подробные предупреждения об усечении | Сообщение об ошибке усечения данных по умолчанию включает имена таблицы и столбца, а также усеченное значение. См. раздел . |
Параметры установки
| Новые функции или обновления | Сведения |
|---|---|
| Новые параметры настройки памяти | Задает конфигурации минимальной памяти сервера (МБ) и максимальной памяти сервера (МБ) во время установки. См. статью , а также в описаниях параметров , и в разделе . Предложенное значение соответствует рекомендациям по настройке памяти, приведенным в разделе . |
| Новые параметры настройки параллелизма | Задает параметр максимального уровня параллелизма во время установки. См. статью и в описании параметра в разделе . Значение по умолчанию соответствует рекомендациям по максимальной степени параллелизма, приведенным в разделе . |
| Предупреждение при установке ключа продукта лицензии Server/CAL | Если вводится ключ продукта лицензии Enterprise Server или CAL и при включенной технологии Hyper-Threading на компьютере установлено более 20 физических ядер или 40 логических ядер, во время установки отобразится предупреждение. Пользователи по-прежнему могут подтвердить ограничение и продолжить установку, или ввести ключ лицензии, поддерживающий максимальное число процессоров операционной системы. |
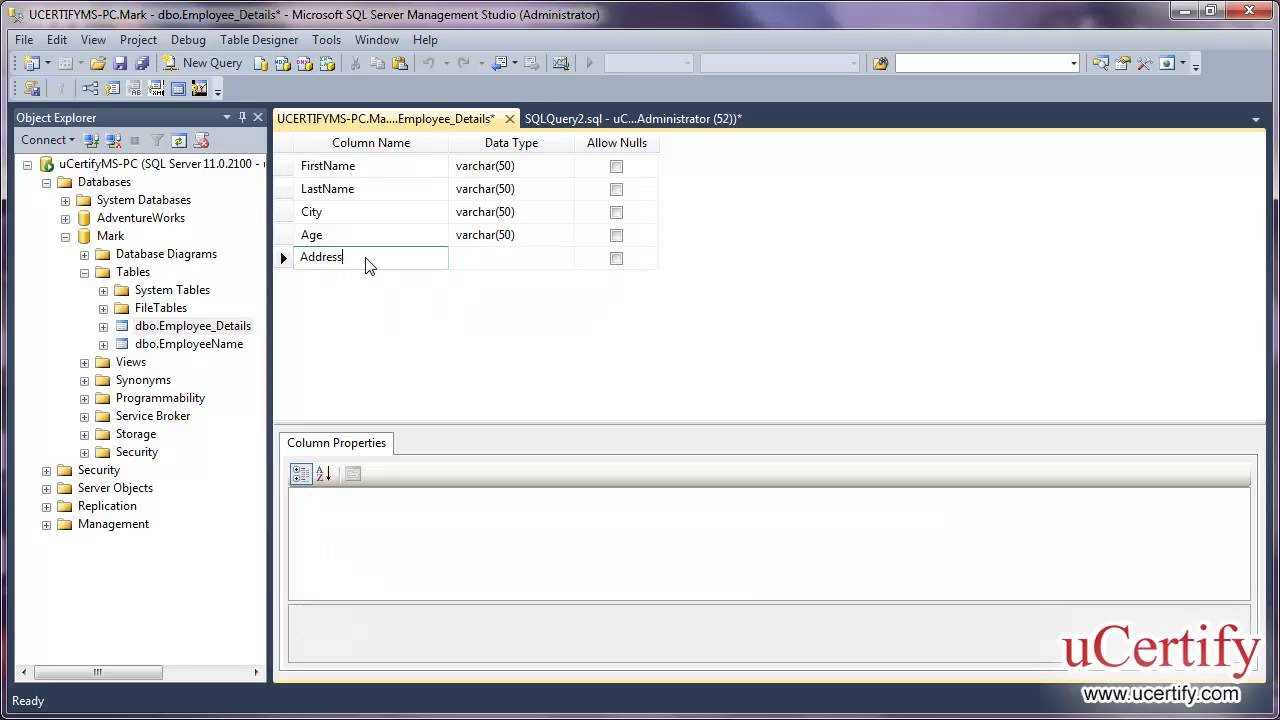
Табличные функции в Transact-SQL – описание и примеры создания
Раньше мы уже знакомились с функциями, которые возвращают таблицу, правда, на языке PL/pgSQL для сервера PostgreSQL (Написание табличной функции на PL/pgSQL). Теперь пришло время поговорить о такой реализации на Transact-SQL.
Вспомним, а для чего нам вообще нужны такие функции. Самый простой ответ на этот вопрос это то, что в таких функциях можно программировать (объявлять переменные, выполнять какие-то расчеты) и передавать параметры внутрь этой функции, как в обычных скалярных функциях, а результат получать в виде таблицы. И это хорошо, ведь в представлениях (вьюхах) этого делать нельзя, а процедура ничего не возвращает (можно сделать, чтобы возвращала, но это в большинстве случае не очень удобно).
Пример создания простой табличной функции
Итак, приступим, для начала приведем самый простой вариант реализации такой функции. Допустим, нам нужно выбрать несколько полей из таблицы по определенному критерию.
Примечание! Данный пример можно реализовать и с помощью представления. Но мы пока только учимся писать такие функции.
--название нашей функции
CREATE FUNCTION .
(
--входящие параметры и их тип
@id INT
)
--возвращающее значение, т.е. таблица
RETURNS TABLE
AS
--сразу возвращаем результат
RETURN
(
--сам запрос
SELECT * FROM table WHERE id = @id
)
GO
В итоге мы создали функцию, в которую будем передавать один параметр id, его мы используем в условии исходного SQL запроса.
Получить данные из этой функции можно следующим образом:
SELECT * FROM dbo.fun_test_tabl (1)
Как видите все проще простого. Теперь давайте создадим функцию уже с использованием программирования в этой функции.
Пример создания табличной функции, в которой можно программировать
--название нашей функции
CREATE FUNCTION .
(
--входящие параметры
@number INT
)
--возвращающее значение, т.е. таблица с перечислением полей и их типов
RETURNS @tabl TABLE (id INT, number INT, summa MONEY)
AS
BEGIN
--объявляем переменные
DECLARE @var MONEY
--выполняем какие-то действия на Transact-SQL
IF @number >=0
BEGIN
SET @var=1000
END
ELSE
SET @var=0
--вставляем данные в возвращающий результат
INSERT @tabl
SELECT id, number, summa
FROM tabl
WHERE summa > @var
--возвращаем результат
RETURN
END
Здесь мы уже программируем и можем выполнять любые действия как в обычных функциях и процедурах, при этом получая результат в виде таблицы. В этом примере мы передаем один параметр внутрь нашей функции (их может быть несколько!), внутри функции мы уже смотрим, что за параметр к нам пришел, и на основе этого уже формируем условие для запроса. Как Вы понимаете это тоже простой пример, но можно писать очень и очень сложные алгоритмы как в процедурах, именно поэтому, и созданы эти табличные функции.
Теперь давайте обратимся к нашей функции, например, вот так
SELECT * FROM dbo.fun_test_tabl_new (1)
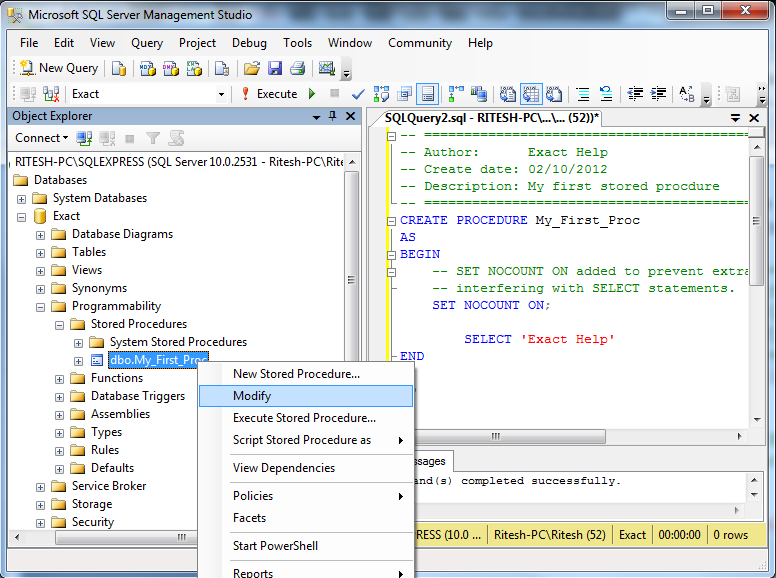
Процедуры
Процедуры DECLARE SQL — это процедуры, полностью реализованные с использованием SQL, которые могут использоваться для инкапсуляции логики. Та же в свою очередь может быть вызвана как подпрограмма программирования.
![]()
В архитектуре базы данных существует много полезных приложений SQL-процедур. Они используются для создания простых сценариев для быстрого запроса на преобразование и обновление данных, генерации базовых отчетов, повышения производительности и модуляции приложений, а также для улучшения общего проектирования и обеспечения безопасности баз данных.
Существует множество функций процедур, которые делают их мощным инструментом обработки
Прежде чем принять решение о внедрении процедуры SQL, важно понять, какие аналоги находятся в контексте подпрограмм, как они реализованы и как их можно использовать
Хранимая процедура sp_executesql в T-SQL
sp_executesql – это системная хранимая процедура Microsoft SQL Server, которая выполняет SQL инструкции. Эти инструкции могут содержать параметры, тем самым делая их динамическими.
Процедура sp_executesql имеет несколько параметров, первым параметром указывается текст SQL инструкции, вторым объявляются переменные, третий и все последующие — это передача значений для переменных в процедуру и, соответственно, подстановка в нашу инструкцию.
Все параметры процедуры sp_executesql необходимо передавать в формате Unicode (тип данных строк должен быть NVARCHAR).
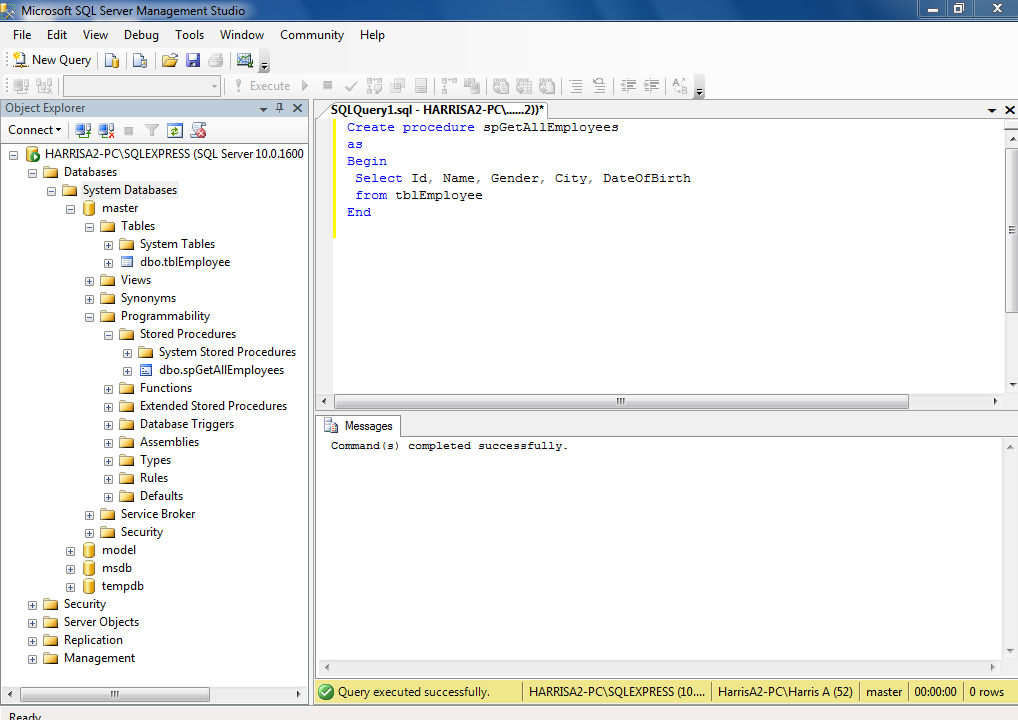
Пример использования sp_executesql в T-SQL
В этом примере итоговый результат у нас будет точно таким же, как и в примере с EXEC, только динамические значения, у нас это переменная @Var1, мы объявим и передадим в виде параметров хранимой процедуры sp_executesql.
--Объявляем переменные
DECLARE @SQL_QUERY NVARCHAR(200);
--Формируем SQL инструкцию
SELECT @SQL_QUERY = N'SELECT * FROM TestTable WHERE ProductID = @Var1;';
--Смотрим на итоговую строку
SELECT @SQL_QUERY AS
--Выполняем текстовую строку как SQL инструкцию
EXEC sp_executesql @SQL_QUERY,--Текст SQL инструкции
N'@Var1 AS INT', --Объявление переменной @Var1
@Var1 = 1 --Передаем значение для переменной @Var1
![]()
У меня на этом все, надеюсь, материал был Вам интересен и полезен, если Вас интересуют другие возможности языка T-SQL, то рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения специально для начинающих, пока!
Нравится19Не нравится1
4 ответа
Лучший ответ
Временные таблицы похожи на обычные таблицы по большинству характеристик, за исключением того, что они входят в TempDB вместо текущей базы данных и исчезают после ограниченной области (в зависимости от того, являются ли они глобальными временными таблицами на основе сеанса или являются глобальными. Но все изменения данных в временных таблицах являются регистрируется в журнале транзакций, со всеми вытекающими отсюда последствиями для производительности. otoh, вы также можете добавить во временную таблицу столько же индексов, или представлений, или триггеров, или чего угодно еще, что вы хотите, точно так же, как и в обычную таблицу.
Табличные переменные — это своего рода сокращенная таблица в памяти (они также используют временную БД). Изменения в них не регистрируются (это повышает производительность). Но вы можете получить для них только один индекс (поскольку индексы не могут быть созданы после оператора начального объявления, единственный индекс, который вы можете создать для табличной переменной, — это тот, который может быть включен в начальное объявление переменной таблицы …
Из-за этих характеристик временные таблицы лучше подходят для больших таблиц (широких и с большим количеством строк) и / или которые будут подвергаться более чем одному шаблону доступа в течение их срока службы, в то время как переменные таблицы лучше всего подходят, когда вам нужна очень узкая таблица ( только таблица ключей или ключ только с одним столбцом данных), к которому всегда будет обращаться этот индексированный ключ …
12
Charles Bretana
10 Июн 2011 в 12:25
-
Табличные переменные имеют четко определенную область видимости. Они будут автоматически очищены в конце пакета (то есть текущего пакета операторов), тогда как временная таблица будет видна для текущего сеанса и вложенных хранимых процедур. Глобальная временная таблица будет видна всем сессиям.
-
Табличные переменные создаются с помощью оператора Declare. Мы не можем создать табличную переменную с помощью оператора
Но мы можем создать временную таблицу, используя оператор Create table, а также оператор
-
Начиная с SQL Server 2008, мы можем передавать табличную переменную в качестве параметра хранимым процедурам. Но мы не можем передать временную таблицу в качестве параметра хранимой процедуре.
-
Мы можем использовать табличную переменную внутри UDF (пользовательская функция), но мы не можем использовать временную таблицу внутри UDF.
1
Andrew Barber
4 Апр 2013 в 04:05
- Нет журнала для табличных переменных
- Табличные переменные имеют только локальную область видимости (вы не можете получить доступ к одной и той же табличной переменной из разных процедур)
- Процедуры с временными таблицами не могут быть предварительно скомпилированы
Дополнительные сведения см. В этой теме.
1
abatishchev
5 Апр 2012 в 07:23
Это довольно хороший справочник по различным временным таблицам.
5
CSharpAtl
20 Окт 2009 в 21:13
службы SQL Server Analysis Services
В этом выпуске появились новые функции и улучшения производительности, управления ресурсами и поддержки клиентов.
| Новые функции или обновления | Сведения |
|---|---|
| Группы вычисления в табличных моделях | Группы вычисления могут значительно сократить количество избыточных мер за счет группировки общих выражений мер в соответствии с вычисляемыми элементами. Дополнительные сведения см. в разделе Группы вычисления в табличных моделях. |
| Чередование запросов | Чередование запросов — это табличный режим системной конфигурации, который может уменьшить время отклика запросов пользователей в сценариях с высоким уровнем параллелизма. Дополнительные сведения см. в статье о чередовании запросов. |
| Связи «многие ко многим» в табличных моделях | Позволяет устанавливать связи «многие ко многим» между неуникальными столбцами в разных таблицах. Дополнительные сведения см. в разделе Отношения в табличных моделях. |
| Настройка свойств для регуляции ресурсов | Этот выпуск включает новые параметры для управления памятью: Memory\QueryMemoryLimit, DbpropMsmdRequestMemoryLimit и OLAP\Query\RowsetSerializationLimit для управления ресурсами. Дополнительные сведения см. в разделе Настройки памяти. |
| Параметр управления для обновлений кэша Power BI | В этом выпуске представлено свойство ClientCacheRefreshPolicy, которое переопределяет кэширование данных для плитки панели мониторинга и данных отчета для начальной загрузки отчетов Live Connect с помощью службы Power BI. Дополнительные сведения см. в разделе Общие свойства. |
| Интерактивное подключение | Такое подключение можно использовать для синхронизации реплик только для чтения в локальных средах масштабирования запросов. Дополнительные сведения см. в разделе . |
Работа с индексами SQL Server
Советы по созданию кластерных индексов
- Первичный ключ не всегда должен быть кластерным индексом. Если Вы создаете первичный ключ, тогда SQL сервер автоматически делает первичный ключ кластерным индексом. Первичный ключ должен быть кластерным индексом, только если он отвечает одной из нижеследующих рекомендаций.
- Кластерные индексы идеальны для запросов, где есть выбор по диапазону или вы нуждаетесь в сортированных результатах. Так происходит потому, что данные в кластерном индексе физически отсортированы по какому-то столбцу. Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
- Кластерные индексы хороши для запросов, которые ищут запись с уникальным значением (типа номера служащего) и когда Вы должны вернуть большую часть данных из записи или всю запись. Так происходит потому, что запрос покрывается индексом.
- Кластерные индексы хороши для запросов, которые обращаются к столбцам с ограниченным числом значений, например столбцы, содержащие данные о странах или штатах. Но если данные столбца мало отличаются, например, значения типа «да/нет», «мужчина/женщина», то такие столбцы вообще не должны индексироваться.
- Кластерные индексы хороши для запросов, которые используют операторы GROUP BY или JOIN.
- Кластерные индексы хороши для запросов, которые возвращают много записей, потому что данные находятся в индексе, и нет необходимости искать их где-то еще.
- Избегайте помещать кластерный индекс в столбцы, в которых содержатся постоянно возрастающие величины, например, даты, подверженные частым вставкам в таблицу (INSERT). Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.
Советы по выбору некластерных индексов
- Некластерные индексы лучше подходят для запросов, которые возвращают немного записей (включая только одну запись) и где индекс имеет хорошую селективность (более чем 95 %).
- Если столбец в таблице не содержит по крайней мере 95% уникальных значений, тогда очень вероятно, что Оптимизатор Запроса SQL сервера не будет использовать некластерный индекс, основанный на этом столбце. Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
- Постарайтесь сделать ваши индексы как можно меньшего размера (особенно для многостолбцовых индексов). Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
- Если возможно, создавайте индексы на столбцах, которые имеют целочисленные значения вместо символов. Целочисленные значения имеют меньше потерь производительности, чем символьные значения.
- Если Вы знаете, что ваше приложение будет выполнять один и тот же запрос много раз на той же самой таблице, рассмотрите создание покрывающего индекса на таблице. Покрывающий индекс включает все столбцы, упомянутые в запросе. Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
- Индекс полезен для запроса только в том случае, если оператор WHERE запроса соответствует столбцу (столбцам), которые являются крайними левыми в индексе. Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
- Любая операция над полем в предикате поиска, которое лежит под индексом, сводит на нет его использование. where isnull(field,’’) = ‘’ здесь индекс не используется, where field = ‘’ and field is not null — здесь используется.
Бывает ли слишком много индексов?
Да. Проблема с лишними индексами состоит в том, что SQL сервер должен изменять их при любых изменениях таблицы (INSERT, UPDATE, DELETE).
Лучшим решением ставить сомнительный индекс или нет, будет подождать и собрать статистику по работе индексов.
Лучшие кандидаты на установку индекса
- Это поля, по которым идет Join
- Поля связи, участвующие в подзапросах
- Поля, по которым идет фильтрация в where
- Поля, по которым выполняется сортировка.
Что такое тип данных в SQL Server?
Тип данных – это характеристика, определяющая, какого рода данные будут храниться в объекте. Например: целые числа, числовые данные с плавающей запятой, данные денежного типа, дата, время, текст, двоичные данные и так далее. У каждого столбца, выражения, переменной или параметра есть определенный тип данных. В Microsoft SQL Server существует набор системных типов данных, который и определяет все доступные по умолчанию типы данных для использования. У разработчиков также существует возможность создавать псевдонимы типов данных основанные на системных типах, а также собственные пользовательские типы данных, о том, как реализовать псевдоним типа данных, мы разговаривали в материале – «Создание псевдонима типа данных в Microsoft SQL Server на T-SQL».
Типы данных в MS SQL Server делятся на следующие категории:
- Точные числа;
- Приблизительные числа;
- Символьные строки;
- Символьные строки в Юникоде;
- Дата и время;
- Двоичные данные;
- Прочие типы данных.