
Реализация на Python
После того, как мы немного обсудили Tabula, давайте разберемся с ее реализацией на Python.
Установка библиотеки
Поскольку tabula-py – это библиотека Python с открытым исходным кодом, мы будем использовать установщик pip для установки библиотеки.
$ pip install tabula-py
Импорт библиотеки
После завершения установки мы можем проверить это, просто импортировав библиотеку, как показано ниже:
import tabula
Если программа выдает ошибку импорта, рекомендуется переустановить пакет.
Библиотека tabula-py предоставляет различные функции, такие как чтение файла PDF, чтение таблицы на определенной странице файла PDF, чтение нескольких таблиц на одной странице файла PDF или преобразование файлов PDF непосредственно в файл CSV.
Начнем с чтения PDF-файла.
Python Программа для преобразования текста в PDF
Предпосылки
- Чтобы запустить приведенный ниже скрипт Python, на вашем устройстве уже должна быть установлена последняя версия Python 3.x.
- В этом примере для создания PDF-файла используется библиотека FPDF. Поэтому установите его перед началом работы.
Шаги
Шаг 1: импортируйте класс пакета библиотеки FPDF:
Давайте перейдем к следующему шагу.
Шаг 2: Сохранение класса FPDF в переменную с именем PDF и добавление страницы:
()>
Шаг 3: Установка стиля и размера шрифта, который вы хотите использовать в PDF-файле:
Вы можете изменить шрифт и размер шрифта в соответствии с вашими потребностями.
Шаг 4: Создание двух ячеек
Шаг 5: Сохранение PDF-файла
Примечание:
Если вы погрузитесь в исходный код, то обнаружите, что пакет PyFPDF поддерживает только следующие размеры страниц:
- А3
- А4
- А5
- письмо
- законный
PyFPDF имеет набор основных шрифтов, жестко закодированных в его класс FPDF:
self.core_fonts={'courier': 'Courier',
'courierB': 'Courier-Bold',
'courierBI': 'Courier-BoldOblique',
'courierI': 'Courier-Oblique',
'helvetica': 'Helvetica',
'helveticaB': 'Helvetica-Bold',
'helveticaBI': 'Helvetica-BoldOblique',
'helveticaI': 'Helvetica-Oblique',
'symbol': 'Symbol',
'times': 'Times-Roman',
'timesB': 'Times-Bold',
'timesBI': 'Times-BoldItalic',
'timesI': 'Times-Italic',
'zapfdingbats': 'ZapfDingbats'}
Написание всей программы в одном окне:
Выход:
Инструменты и библиотеки
Спектр доступных решений для связанных с Python инструментов, модулей и библиотек PDF немного сбивает с толку. Требуется время, чтобы понять, что к чему и какие проекты постоянно поддерживаются. Наше исследование позволило отобрать тех кандидатов, которые соответствуют современным требованиям:
- PyPDF2 — библиотека для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. PyPDF2 поддерживает как незашифрованные, так и зашифрованные документы.
- PDFQuery — позиционируется как «быстрая и удобная библиотека чистого PDF» и реализована как оболочка для PDFMiner, lxml и pyquery. Основная идея заключается в том, чтобы «надежно извлекать данные из наборов PDF‑файлов, используя как можно меньше кода».
- pdflib — расширение библиотеки Poppler, которое позволяет анализировать и конвертировать PDF‑документы. Не следует его путать с коммерческим клоном с таким же именем.
- ReportLab — амбициозная промышленная библиотека, в основном ориентированная на оздание высококачественных PDF‑документов. Доступны как свободная версия с открытым исходным кодом, так и коммерческая, улучшенная, версия ReportLab PLUS.
- pdfrw — чистый анализатор PDF на основе Python для чтения и записи PDF. Он точно воспроизводит векторные форматы без растеризации. Вместе с ReportLab он помогает повторно использовать части существующих PDF‑файлов в новых PDF‑файлах, созданных с помощью ReportLab.
В своём исследовании мы учитывали мнения Github-сообщества, а именно:
- Звёзды Github: общее количество звезд проекта, выставленных пользователям.
- Релизы Github: количество релизов каждого проекта, что отражает активность работы над проектом и его зрелость.
- Fork-и Github: количество, сделанных копий каждого проекта, что показывает популярность использования проекта в собственных работах.
| Библиотека | Использование | Github | ReleasesGithub | Github |
|---|---|---|---|---|
| PyPDF2 | Чтение | 2 972 | 10 | 751 |
| PyMuPDF | Чтение | 474 | 59 | 111 |
| pdflib | Чтение | 20 | 4 | |
| PDFTables | Чтение | 85 | 69 | |
| tabula-py | Чтение | 971 | 23 | 200 |
| PDFMiner.six | Чтение | 1 599 | 11 | 1 400 |
| PDFQuery | Чтение | 477 | 1 | 70 |
| pdfrw | Чтение, Запись/Создание | 1 145 | 4 | 187 |
| Reportlab | Запись/Создание | 31 | 48 | 22 |
| PyX | Запись/Создание | 23 | 26 | 7 |
| PyFPDF | Запись/Создание | 457 | 7 | 174 |
Читать это руководство, не прорабатывая приведённые в нём примеры, бессмысленно. Поэтому, вооружимся IDLE Python и воспользуемся менеджером пакетов pip или pip3 для установки PyPDF2 и PyMuPDF. Наберём в командной строке (Windows):
pip3 install pypdf2 pip3 install pymupdf
Для того, что бы не запутаться создадим папочку для своего проекта. Как видите местом для неё выбрана папка «Документы» стандартной установки Windows.![]() Вот так это выглядит в Windows
Вот так это выглядит в Windows
Папки и будем использовать для записи результатов работы своих программ, а в папке храним исходные PDF‑файлы, сами скрипты будем хранить в корне. Кстати, все примеры этой серии статей о работе с PDF‑файлами есть на Github, откуда их можно забрать и использовать в качестве «кирпича» для своих упражнений
Скачать TeXlive
Две ссылки, показанные ниже, перейдут на ту же страницу доступности TeX Live. Я скачал установщик последней версии TeXlive2018.
Многие блогеры говорят, что этот метод очень медленный, но из моего опыта работы с различными установками программного обеспечения, сжатие и распаковка этого метода установки программного обеспечения подвержены ошибкам. Новички часто тратят много времени на настройку и отладку, или Будет задействован более профессиональный контент конфигурации. Разные учебники иногда имеют разную конфигурацию контента, что приводит людей в замешательство. Неофициальный пакет сжатия веб-сайтов не может даже гарантировать его подлинность и безопасность. Поэтому при установке TeXlive рекомендуется использовать установщик, ведь рекомендуемые должны иметь причины его преимуществ.
Обработка PDF документов
В Linux для работы с файлами PDF всё проще, есть мощные инструменты командной строки, такие как и . Но, поскольку, PDF — межплатформенный открытый формат электронных документов, хотелось бы с таким же удобством работать и в Windows, и в macOS. При этого нужна фантазия и усилия разработчика. Вот и совсем недавно встретилась задачка переноса информации из PDF‑файла в базу данных. Естественно, задача автоматизации здесь имеет свою уникальную специфику и без разработки здесь ну совсем никак.
Это руководство — начало небольшой серии, где будут рассмотрены полезные для разработчика библиотеки, позволяющие создавать собственные скрипты Python для решения рутинных задач автоматизации
В первой части внимание сконцентрировано на манипулировании существующими PDF‑файлами. Вы узнаете, как читать и извлекать содержимое (текст и изображения) и разбивать документы на отдельные страницы
Вторая часть будет посвящена наложению водяных знаков в документ. Третья часть посвящена исключительно написанию/созданию PDF‑файлов, а также удалению и повторному объединению отдельных страниц в новый документ.
Чтение файла PDF
Библиотека tabula-py позволяет пользователям читать PDF-файл с помощью функции, известной как read_pdf().
Синтаксис:
obj = tabula.read_pdf(filename, args[])
Параметры:
filename: Параметр filename – это имя файла pdf, данные которого мы хотели бы прочитать.
Давайте преобразуем следующую таблицу данных pdf в фрейм данных pandas.
Имя файла: Marksheet_table.py
| Имя | Английский | Физика | Химия | Биология | Итог |
|---|---|---|---|---|---|
| А | 86 | 54 | 65 | 83 | 288 |
| B | 56 | 45 | 80 | 55 | 236 |
| C | 34 | 66 | 73 | 90 | 263 |
| D | 77 | 75 | 46 | 34 | 232 |
| E | 74 | 82 | 55 | 77 | 288 |
| F | 69 | 76 | 82 | 46 | 273 |
| G | 53 | 33 | 29 | 45 | 160 |
| H | 70 | 41 | 67 | 23 | 201 |
| I | 80 | 43 | 88 | 28 | 239 |
| J | 90 | 37 | 45 | 71 | 243 |
| K | 98 | 55 | 88 | 81 | 322 |
| L | 90 | 54 | 67 | 37 | 248 |
| M | 87 | 76 | 88 | 54 | 305 |
| N | 86 | 69 | 82 | 66 | 303 |
| О | 67 | 74 | 54 | 65 | 260 |
| P | 75 | 96 | 53 | 67 | 291 |
| Q | 45 | 87 | 80 | 45 | 257 |
| R | 44 | 66 | 49 | 78 | 237 |
| S | 78 | 39 | 78 | 80 | 275 |
| Т | 56 | 54 | 76 | 86 | 273 |
| U | 43 | 90 | 64 | 77 | 274 |
| V | 95 | 88 | 66 | 55 | 304 |
| W | 64 | 67 | 86 | 80 | 297 |
| X | 82 | 56 | 45 | 65 | 248 |
| Y | 79 | 65 | 70 | 54 | 268 |
| Z | 83 | 54 | 40 | 75 | 252 |
Вот пример, приведенный ниже, который демонстрирует, как извлечь данные из PDF.
Пример:
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 1) # printing the table print(mytable)
Выход:
Name English Physics Chemistry Biology Total 0 A 86 54 65 83 288 1 B 56 45 80 55 236 2 C 34 66 73 90 263 3 D 77 75 46 34 232 4 E 74 82 55 77 288 5 F 69 76 82 46 273 6 G 53 33 29 45 160 7 H 70 41 67 23 201 8 I 80 43 88 28 239 9 J 90 37 45 71 243 10 K 98 55 88 81 322 11 L 90 54 67 37 248 12 M 87 76 88 54 305 13 N 86 69 82 66 303 14 O 67 74 54 65 260 15 P 75 96 53 67 291 16 Q 45 87 80 45 257 17 R 44 66 49 78 237 18 S 78 39 78 80 275 19 T 56 54 77 86 273 20 U 43 90 64 77 274 21 V 95 88 66 55 304 22 W 64 67 86 80 297 23 X 82 56 45 65 248 24 Y 79 65 70 54 268 25 Z 83 54 40 75 252
Объяснение:
В приведенном выше примере мы импортировали необходимую библиотеку и определили переменную, в которой хранится адрес файла данных pdf. Затем мы использовали функцию read_pdf(), чтобы прочитать данные из PDF и распечатать их для пользователей. В результате таблица данных была успешно прочитана.
Примечание. Мы использовали параметр pages в функции read_pdf() для чтения данных с указанных страниц.
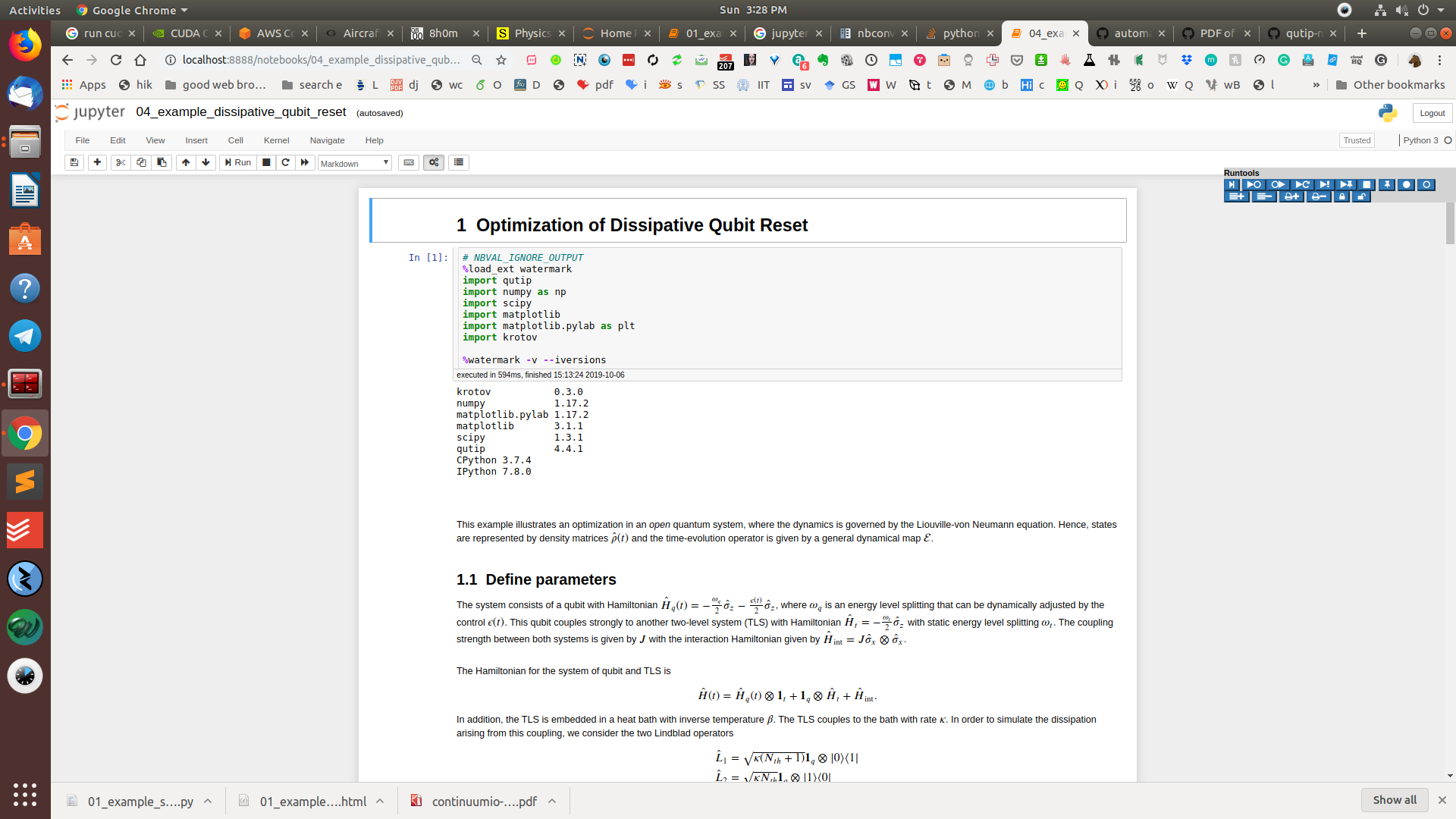
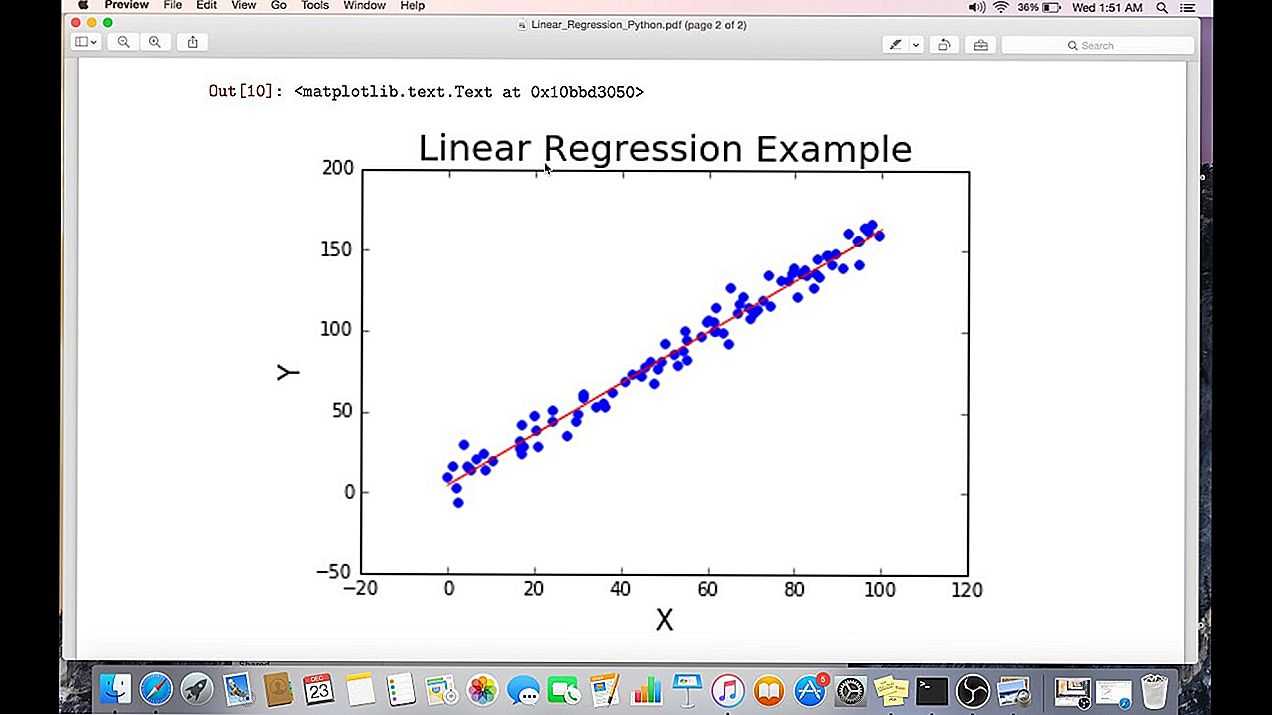
Давайте рассмотрим другой пример печати таблиц с определенной страницы, скажем, страницы номер 2.
Пример:
# importing the library import tabula # address of the file myfile = 'marksheet_table.pdf' # using the read_pdf() function mytable = tabula.read_pdf(myfile, pages = 2) # printing the table print(mytable)
Выход:
Name Final Scores 0 A 288 1 B 236 2 C 263 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 3 D 232 4 E 288 5 F 273 6 G 160 7 H 201 8 I 239 9 J 243 10 K 322 11 L 248 12 M 305 13 N 303 14 O 260 15 P 291 16 Q 257 17 R 237 18 S 275 19 T 273 20 U 274 21 V 304 22 W 297 23 X 248 24 Y 268 25 Z 252
Объяснение:
В приведенном выше примере мы выполнили ту же процедуру, что и ранее. Однако мы присвоили параметру страниц значение 2 и распечатали первую таблицу указанной страницы. В результате таблица нулевого индекса на странице 2 была успешно напечатана.
Теперь давайте разберемся, что происходит, когда на одной странице файла данных PDF находится более одной таблицы.
Преобразование текстового файла в PDF-файл на Python
Сохранив сгенерированный сценарием текстовый файл в формате PDF, теперь давайте преобразуем локально доступный текстовый файл в форму PDF с помощью модуля fpdf.
Для этого нам нужно использовать функцию file.open (), чтобы открыть текстовый файл в режиме “чтение”. После этого мы проходим через данные в цикле for, а затем используем функцию cell() для хранения этих пройденных данных в форме PDF.
Наконец, мы используем функцию output() для создания спроектированного PDF-файла в указанном месте с указанным именем.
Пример:
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size = 25)
# create a cell
file = open("data.txt", "r")
# insert the texts in pdf
for g in file:
pdf.cell(200, 10, txt = g, ln = 1, align = 'C')
pdf.output("PDF.pdf")
Выход:
Временное решение в приложении «Файлы»
Если у вас не установлен Word, есть обходной путь, связанный с приложением «Файлы», которое вы можете использовать для преобразования документов DOCX в PDF. Звучит интересно, правда? Давай узнаем, как ты это делаешь.
Примечание: Если на вашем устройстве iOS установлен Word, вы не можете использовать следующий обходной путь.
Шаг 1: Откройте приложение «Файлы» и перейдите в папку с файлом DOCX.
![]()
![]()
Шаг 2: Коснитесь файла. Приложение «Файлы» должно использовать встроенную функцию предварительного просмотра PDF в iOS, чтобы открыть файл.
После этого коснитесь значка «Поделиться» в правом верхнем углу окна, а затем коснитесь «Сохранить PDF в iBooks».
![]()
![]()
Примечание: Еще раз, если у вас установлен Word, приложение «Файлы» запускает файл в Word вместо его предварительного просмотра.
Шаг 3: Теперь файл должен конвертироваться и открываться в iBooks без проблем.
Но теперь возникает проблема. Хотя вы можете работать с PDF-файлом в iBooks и сохранять любые изменения локально, ваши возможности совместного использования ограничены использованием AirDrop, электронной почты или печати.
![]()
![]()
И хуже всего во всей сделке то, что вы не можете получить доступ к файлам, хранящимся в iBooks, через приложение Files. Очевидно, это затрудняет перенос PDF-файлов в другие приложения.
Если вы используете iPad, вы можете легко преодолеть это ограничение с помощью разделенного просмотра, где простое перетаскивание — это все, что вам нужно для перемещения файлов между приложениями. К сожалению, iPhone не поддерживает многозадачность, поэтому вам на самом деле нужно сначала отправить файл из iBooks себе по электронной почте в качестве вложения, а затем загрузить и сохранить его в приложении «Файлы» — после этого вы можете делать с файлом все что угодно. вы считаете нужным.
Укажите формат PDF
Мы можем указать различные параметры, которые являются параметрами в вышеупомянутых трех методах. Конкретные настройки см. вhttps://wkhtmltopdf.org/usage/wkhtmltopdf.txt Содержание внутри. Здесь мы приводим только каштан:
По умолчанию pdfkit покажет все выходные данные. Если вы не хотите его использовать, вы можете установить его на вполне:
Мы также можем передать любые теги HTML, такие как:
улучшать
Имея указанные выше знания, мы можем попробовать это. Если мы изменим предыдущий метод save_file, мы сможем достичь цели загрузки PDF. Мы изменили имя метода на save_to_pdf и напрямую вернули str (div) в метод get_body вместо div.text. код шоу, как показано ниже:
Ха-ха, это успех. После загрузки очень многих PDF-файлов просто оглянись назад.
Распространенные ошибки:
Python использует pdfkit. Если вы используете pdfkit.from_url или pdfkit.from_string и т. Д., Появится ошибка выше. И если вы установили его с помощью pipwkhtmltopdfЭта проблема все еще будет возникать: Так что вам нужно установить версию для Windowswkhtmltopdf Введите URL для загрузки здесь После завершения установки вам необходимо добавить в код следующее:
Если эта ошибка возникает, PDFKit не может обработать ввод. Вы можете попробовать запустить команду сразу после сообщения об ошибке, чтобы увидеть, что вызвало эту ошибку (некоторые версии wkhtmltopdf могут вызвать сбой обработки из-за segfault
=============================================== 1. Во-первых, используйте Google Chrome, чтобы открыть страницу для сохранения, например, я открыл веб-страницу для изучения Python. 2. В правом верхнем углу браузера перейдите на вкладку «Настройка и управление Google Chrome» и выберите «Печать» во всплывающем меню, либо используйте сочетание клавиш «Crtl + P» для настройки Из этого меню. 3. На всплывающей странице параметров печати и предварительного просмотра нажмите «Изменить» в пункте «Целевой принтер» в правой части страницы. По умолчанию установлен фактический подключенный принтер. 4. Во всплывающем окне «Выбор принтера» выберите параметр «Сохранить как PDF» в окне управления локального целевого принтера. 5. После этого вы также можете установить параметры печати, такие как «номер страницы», «макет», «размер бумаги», «поля» и «опция».
-
После настройки нажмите кнопку «Сохранить», введите имя файла во всплывающем окне, и вы сможете сохранить его.
ссылка:https://www.cnblogs.com/xingzhui/p/7887212.html https://blog.csdn.net/sinat_20280061/article/details/51674605 https://jingyan.baidu.com/article/546ae1853b1eb51148f28c6e.html
Найти все страницы, содержащие текст
Этот вариант использования весьма практичен и работает аналогично pdfgrep. Используя PyMuPDF, скрипт возвращает все номера страниц, которые содержат заданную строку поиска. Страницы загружаются одна за другой, и с помощью метода searchFor() обнаруживаются все вхождения строки поиска. В случае совпадения соответствующее сообщение выводится на стандартный вывод.
Листинг 5:
#!/usr/bin/python
import fitz
filename = "example.pdf"
search_term = "invoice"
pdf_document = fitz.open(filename):
for current_page in range(len(pdf_document)):
page = pdf_document.loadPage(current_page)
if page.searchFor(search_term):
print("%s found on page %i" % (search_term, current_page))
На рисунке 5 ниже показан результат поиска по запросу «Debian GNU или Linux» в 400-страничной книге.
![]()
Разделение PDF-файлов на страницы с помощью PyPDF2
В этом примере сначала необходимо импортировать классы PdfFileReader и PdfFileWriter. Затем мы открываем PDF-файл, создаем объект-читатель и просматриваем все страницы в цикле, используя метод getNumPages объекта-читателя.
Внутри цикла for мы создаем новый экземпляр PdfFileWriter, который пока не содержит никаких страниц. Затем мы добавляем текущую страницу к нашему объекту записи, используя метод pdfWriter.addPage(). Этот метод принимает объект страницы, который мы получаем с помощью метода PdfFileReader.getPage().
Следующим шагом является создание уникального имени файла, что мы делаем, используя исходное имя файла плюс слово «страница» плюс номер страницы. Мы добавляем 1 к текущему номеру страницы, потому что PyPDF2 считает номера страниц, начиная с нуля.
Наконец, мы открываем новое имя файла в режиме «двоичной записи» (режим wb) и используем метод write() класса pdfWriter для сохранения извлеченной страницы на диск.
Пример 4:
#!/usr/bin/python
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "example.pdf"
pdf = PdfFileReader(pdf_document)
for page in range(pdf.getNumPages()):
pdf_writer = PdfFileWriter
current_page = pdf.getPage(page)
pdf_writer.addPage(current_page)
outputFilename = "example-page-{}.pdf".format(page + 1)
with open(outputFilename, "wb") as out:
pdf_writer.write(out)
print("created", outputFilename)
![]()
8 ответов
Лучший ответ
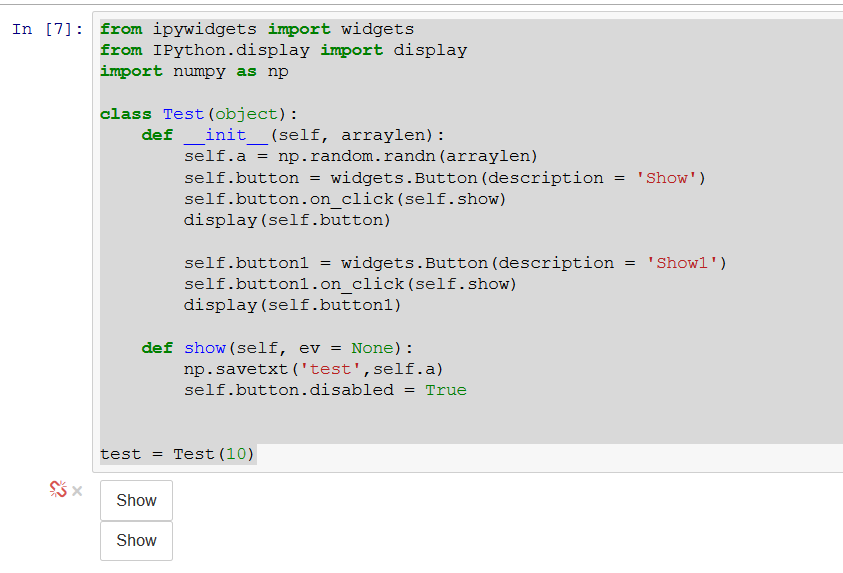
Из меню записной книжки вы можете сохранить файл непосредственно как скрипт Python. Перейдите к опции «Файл» в меню, затем выберите «Загрузить как» и там вы увидите опцию «Python (.py)».

Другой вариант — использовать nbconvert из командной строки:
Посмотрите .
67
kikocorreoso
13 Июн 2016 в 21:12
- Перейдите на страницу https://jupyter.org/.
- нажмите на nbviewer
- Введите местоположение вашего файла и визуализируйте его.
- Нажмите на вид в виде кода (отображается как >)
1
Blade
7 Апр 2019 в 01:50
Согласно https://ipython.org/ipython-doc/3/notebook/nbconvert .html вы ищете команду nbconvert с параметром сценария —to.
21
Kush
13 Июн 2016 в 21:05
Вкратце: . Этот параметр командной строки преобразует в код:
примечание: это отличается от выше ответа. был переименован в . старое исполняемое имя (ipython) устарело.
Подробнее: В командной строке есть аргумент , который помогает конвертировать файлы записной книжки в различные другие форматы.
Вы даже можете преобразовать его в любой из этих форматов, используя ту же команду, но с другой опцией :
- asciidoc
- обычай
- html
- латекс. (Отлично, если вы хотите вставить код в конференции / журнальные статьи).
- уценка
- ноутбук
- питон
- первый
- сценарий
- слайды . (Ух! Конвертировать в слайды для удобства презентации )
Та же команда
Подробнее см. . Есть обширные варианты этого. Вы даже можете выполнить код перед преобразованием, другие параметры уровня журнала и т. Д.
8
Srikar Appalaraju
14 Дек 2018 в 20:01
Ну, прежде всего вам нужно установить этот пакет ниже:
Доступны два варианта: —to python или —to = python. Мой метод работает следующим образом: jupyter nbconvert —to python while.ipynb
Преобразование блокнота while.ipynb в python Запись 758 байтов в while.py
Если у вас ничего не получится, попробуйте pip3.
3
sebuhi
22 Фев 2019 в 21:53
Вы определенно можете добиться этого с помощью nbconvert, используя следующую команду:
Однако, используя его лично, я бы посоветовал против этого по нескольким причинам:
- Одно дело иметь возможность преобразовывать в простой код Python, а другое — иметь все нужные абстракции, доступ к классам и настроенные методы. Если весь смысл того, что вы конвертируете код своей записной книжки в Python, доходит до состояния, когда ваш код и записные книжки могут обслуживаться в течение долгого времени, тогда одного nbconvert будет недостаточно. Единственный способ сделать это — вручную пройти по базе кода.
- Записные книжки по своей природе способствуют написанию кода, который не подлежит сопровождению https://docs.google.com/presentation/d/1n2RlMdmv1p25Xy5thJUhkKGvjtV-dkAIsUXP-AL4ffI/edit#slide=id.g3d7fe085e7_0_21 ) . Использование nbconvert сверху может оказаться просто бандой. Конкретными примерами того, как он продвигает не так обслуживаемый код, является то, что импорт может быть разбросан повсюду, жестко закодированные пути не в одном простом месте для просмотра, абстракции классов могут отсутствовать и т. Д.
- nbconvert все еще смешивает код выполнения и код библиотеки.
- Комментариев до сих пор нет (вероятно, не было в записной книжке).
- По-прежнему не хватает юнит-тестов и т. Д.
Итак, подведем итог: нет хорошего способа конвертировать записные книжки Python в готовый к работе, надежный модульный код Python, единственный способ — сделать операцию вручную.
user1460675
10 Дек 2019 в 03:53
Вы можете использовать следующий скрипт, чтобы конвертировать блокнот jupyter в скрипт Python или просмотреть код напрямую.
Для этого запишите следующее содержимое в файл , затем .
Тогда вы можете использовать
Или показать это с помощью напрямую
1
Syrtis Major
4 Янв 2019 в 08:06
Jupytext допускает такое преобразование в командной строке, и важно, что вы можете снова вернуться из сценария в блокнот (даже в выполненный блокнот). См
здесь.
Wayne
2 Янв 2020 в 19:16
Разделение четных и нечетных страниц с помощью PyPDF2
Следующий пример использует PyPDF2 и разделяет файл на четные и нечетные страницы, сохраняя четные страницы в файле Documentation-Python-even.pdf и нечетные страницы в Documentation-Python-odd.pdf. Этот скрипт Python начинается с определения двух выходных файлов, Documentation-Python-even.pdf и Documentation-Python-odd.pdf, а также соответствующие им объекты для записи pdf_writer_even и pdf_writer_odd. Затем в цикле for скрипт просматривает весь файл PDF и читает одну страницу за другой. Страницы с четными номерами страниц добавляются в поток pdf_writer_even с помощью addPage(), а нечетные номера добавляются в поток pdf_writer_odd. В конце два потока сохраняются на диск в отдельных файлах, как определено ранее. Сам код:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_document = "source/ YourFile.pdf "
pdf = PdfFileReader(pdf_document)
# Выходные файлы для новых PDF-файлов
output_filename_even = "dist/ YourFile -even.pdf"
output_filename_odd = "dist/ YourFile -odd.pdf"
pdf_writer_even = PdfFileWriter()
pdf_writer_odd = PdfFileWriter()
# Получить досягаемую страницу и добавить ее в соответствующую
# выходной файл на основе номера страницы
for page in range(pdf.getNumPages()):
current_page = pdf.getPage(page)
if page % 2 == 0:
pdf_writer_odd.addPage(current_page)
else:
pdf_writer_even.addPage(current_page)
# Записать данные на диск
with open(output_filename_even, "wb") as out:
pdf_writer_even.write(out)
print("created", output_filename_even)
# Записать данные на диск
with open(output_filename_odd, "wb") as out:
pdf_writer_odd.write(out)
print("created", output_filename_odd)
Способ 2: Overleaf
Overleaf — еще один популярный редактор LaTeX онлайн, в котором поддерживается древовидное оформление проектов и есть целый ряд шаблонов с заготовленным правильным оформлением. Процесс взаимодействия с простым проектом выглядит так:
- После перехода на сайт Overleaf зарегистрируйтесь или авторизуйтесь через аккаунт в любой поддерживаемой социальной сети.
![]()
На панели управления слева нажмите «New Project».
![]()
После отображения выпадающего меню найдите там подходящую заготовку или создайте пустой проект.
![]()
При использовании шаблонов можно ознакомиться с разными вариантами, определяя подходящий.
![]()
На странице детального описания шаблона нажмите «Open as Template» для перехода к редактированию.
![]()
Основное содержимое находится в файле формата TEX, а редактор открывается нажатием по правой стрелке, находящейся левее блока предпросмотра.
![]()
Единственным недостатком Overleaf можно считать отсутствие синтаксически оформленных формул и других символов, которые вставляются в документ, поэтому оформлять каждый стиль придется самостоятельно.
![]()
На помощь придет продвинутый режим под названием «Rich Text».
![]()
Здесь есть ряд основных элементов форматирования, которые помогут выделить параграфы, сделать текст жирным или курсивом и добавить некоторые специфические знаки.
![]()
Слева находится древовидная структура проекта, где в отдельных папках располагаются используемые изображения и другие объекты. Изменяйте их или добавляйте свои в любом порядке.
![]()
В окне предпросмотра есть кнопка «Recompile», клик по которой запускает повторную сборку проекта после внесения изменений. Там и ознакомьтесь с полученным результатом.
![]()
Нажмите по кнопке «Download», если проект готов к загрузке на компьютер в виде PDF-файла.
![]()
Полученный файл нельзя редактировать должным образом, поэтому заранее удостоверьтесь в том, что все содержимое там выполнено в правильном формате.
![]()
Добавление штампов с pdfrw
pdfrw — это библиотека Python и утилита, которая читает и записывает PDF файлы. И перед тем как выполнять данное задание, эту библиотеку необходимо будет установить. После этого, мы из данного пакета импортируем три класса — PdfReader PdfWriter и PageMerge. Устанавливаем соответственно объекты чтения/записи, для доступа как к содержимому PDF, так и к нашему изображению. Для каждой страницы в исходном документе вы продолжаем создавать объекты PageMerge, к которому добавляем водяной знак и который отображается всё это с помощью метода render(). Сам код:
from pdfrw import PdfReader, PdfWriter, PageMerge
input_file = "source/ YourFile.pdf "
output_file = "dist/ YourFile-pages-image.pdf"
watermark_file = "source/mshe-logo-512x512.pdf "
# определяем объекты чтения и записи
reader_input = PdfReader(input_file)
writer_output = PdfWriter()
watermark_input = PdfReader(watermark_file)
watermark = watermark_input.pages
# просматривать страницы одну за другой
for current_page in range(len(reader_input.pages)):
merger = PageMerge(reader_input.pages)
merger.add(watermark).render()
# записать измененный контент на диск
writer_output.write(output_file, reader_input)
Результат:
Набор формул в LaTeX
Есть два стандартных окружения для ввода формул: Первый и Второй
Если вы не собираетесь ссылаться на формулу в дальнейшем, то
достаточно поставить два знака доллара $ $ , а между ними написать формулу, например:
Такую простую формулу, можно было бы и без окружения написать, но уже для
использования индексов окружение необходимо.
Чтобы LaTeX дал формуле номер (он делает это
автоматически) нужно окружение
В этом окружении также можно использовать \label{} чтобы ставить метки.
Если ваша формула очень будет занимать несколько строк окружение нужно заменить на:
Вместо слов «Ваша формула» нужно написать нужное уравнение.
Как правильно написать уравнение Вы можете узнать из параграфа:
Рисование
Пакет PyFPDF содержит ограниченную поддержку рисования. Вы можете рисовать линии, эллипсы и прямоугольники. Для начала узнаем, как рисовать линии:
Python
# draw_lines.py
from fpdf import FPDF
def draw_lines():
pdf = FPDF()
pdf.add_page()
pdf.line(10, 10, 10, 100)
pdf.set_line_width(1)
pdf.set_draw_color(255, 0, 0)
pdf.line(20, 20, 100, 20)
pdf.output(‘draw_lines.pdf’)
if __name__ == ‘__main__’:
draw_lines()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# draw_lines.py fromfpdf importFPDF defdraw_lines() pdf=FPDF() pdf.add_page() pdf.line(10,10,10,100) pdf.set_line_width(1) pdf.set_draw_color(255,,) pdf.line(20,20,100,20) pdf.output(‘draw_lines.pdf’) if__name__==’__main__’ draw_lines() |
Здесь мы вызываем метод line, чтобы передать ему две пары координат x и y. Ширина линии по умолчанию – 0.2мм, так что мы расширим её до 1 мм для второй линии, вызывав метод set_line_width. Мы также указываем цвет второй линии, вызвав метод set_draw_color и указав значение RGB, эквивалентное красному цвету. Результат выглядит следующим образом:
![]()
Теперь мы можем перейти к рисованию нескольких фигур:
Python
# draw_shapes.py
from fpdf import FPDF
def draw_shapes():
pdf = FPDF()
pdf.add_page()
pdf.set_fill_color(255, 0, 0)
pdf.ellipse(10, 10, 10, 100, ‘F’)
pdf.set_line_width(1)
pdf.set_fill_color(0, 255, 0)
pdf.rect(20, 20, 100, 50)
pdf.output(‘draw_shapes.pdf’)
if __name__ == ‘__main__’:
draw_shapes()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# draw_shapes.py fromfpdf importFPDF defdraw_shapes() pdf=FPDF() pdf.add_page() pdf.set_fill_color(255,,) pdf.ellipse(10,10,10,100,’F’) pdf.set_line_width(1) pdf.set_fill_color(,255,) pdf.rect(20,20,100,50) pdf.output(‘draw_shapes.pdf’) if__name__==’__main__’ draw_shapes() |
Когда вы рисуете фигуру, вроде эллипса или прямоугольника, вам нужно передать координаты x и y, которые обозначают верхний левый угол рисунка. Далее, вам может понадобиться указать ширину и высоту фигуры.
Последний аргумент, который передается методу style – это «D», или пустая строка (default), «F» для заливки, «DF» — для заливки и рисунка. В данном примере мы зальем эллипс и используем default для прямоугольника. Результат будет выглядеть следующим образом:
![]()
Теперь поговорим о поддержке изображений.
Извлечение текста с помощью PyPDF2 и PyMuPDF
Сначала сделаем извлечение текста двумя методами. Первый – используя библиотеку PyPDF2, а второй – PyMuPDF. Что это вообще за библиотеки? PyPDF2 – это библиотека для извлечения информации и содержимого документов, постраничного разделения документов, объединения документов, обрезки страниц и добавления водяных знаков. А PyMuPDF (известный как fitz) — привязка Python для MuPDF, который является облегченным средством просмотра PDF и XPS. Именно поэтому, первым делом мы устанавливаем эти библиотеки: pip3 install pypdf2, pip3 install pymupdf. Далее, в папке с проектом мы создаем еще три дополнительные папки: images, source и dist. Папки images и dist будем использовать для записи результатов работы своих программ, а в папке source храним исходные PDF файлы (которые надо будет заранее туда положить), сами скрипты будем хранить в корне. После всех этих действий, приступаем к извлечению текста с помощью PyPDF2:
from PyPDF2 import PdfFileReader
pdf_document = "source/YourFile.pdf"
with open(pdf_document, "rb") as filehandle:
pdf = PdfFileReader(filehandle)
info = pdf.getDocumentInfo()
pages = pdf.getNumPages()
print("Количество страниц в документе: %i\n\n" % pages)
print("Мета-описание: ", info)
for i in range(pages):
page = pdf.getPage(i)
print("Стр.", i, " мета: ", page, "\n\nСодержание;\n")
print(page.extractText())
В данном коде мы импортируем PdfFileReader, помня о том, что пакет уже установлен. Задаём имя файла из папки source, открывает документ и получаем информацию о документе, используя метод getDocumentInfo() и общее количество страниц getNumPages(). Далее в цикле for читаем каждую страницу, получаем содержимое page.extractText() и печатаем в stdout
Обратите внимание, что PyPDF2 начинает считать страницы с 0, и поэтому вызов pdf.getPage(i) при i = 0 извлекает первую страницу документа. Результат:
Если использовать библиотеку PyMuPDF, то код выполняется аналогично предыдущему методу, единственный момент заключается в том, что импортируемый модуль имеет имя fitz, что соответствует имени PyMuPDF в ранних версиях:
import fitz
pdf_document = "./source/ YourFile.pdf "
doc = fitz.open(pdf_document)
print("Исходный документ: ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
for current_page in range(len(doc)):
page = doc.loadPage(current_page)
page_text = page.getText("text")
print("Стр. ", current_page+1, "\n\nСодержание;\n")
print(page_text)
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF документе. Результат:
Извлечение текста из PDF-страниц
import PyPDF2
with open('Python_Tutorial.pdf', 'rb') as pdf_file:
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
# printing first page contents
pdf_page = pdf_reader.getPage(0)
print(pdf_page.extractText())
# reading all the pages content one by one
for page_num in range(pdf_reader.numPages):
pdf_page = pdf_reader.getPage(page_num)
print(pdf_page.extractText())
- Метод getPage (int) PdfFileReader возвращает экземпляр PyPDF2.pdf.PageObject.
- Мы можем вызвать метод extractText() для объекта страницы, чтобы получить текстовое содержимое страницы.
- ExtractText() не возвращает двоичных данных, таких как изображения.
Многостраничные документы
Пакет PyFPDF включает в себя поддержку многостраничных документов по умолчанию. Добавив достаточное количество клеток в странице, автоматически будет создана новая страница, так что вы сможете продолжать ваш новый текст. Вот простой пример:
Python
# multipage_simple.py
from fpdf import FPDF
def multipage_simple():
pdf = FPDF()
pdf.set_font(«Arial», size=12)
pdf.add_page()
line_no = 1
for i in range(100):
pdf.cell(0, 10, txt=»Line #{}».format(line_no), ln=1)
line_no += 1
pdf.output(«multipage_simple.pdf»)
if __name__ == ‘__main__’:
multipage_simple()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# multipage_simple.py fromfpdf importFPDF defmultipage_simple() pdf=FPDF() pdf.set_font(«Arial»,size=12) pdf.add_page() line_no=1 foriinrange(100) pdf.cell(,10,txt=»Line #{}».format(line_no),ln=1) line_no+=1 pdf.output(«multipage_simple.pdf») if__name__==’__main__’ multipage_simple() |
Все, что здесь происходит – это создание 100 строк текста с помощью функции range. Когда я запустил этот код, то получил 4 страницы текста.





