
Почему ИНДЕКС/ПОИСКПОЗ лучше, чем ВПР?
Решая, какую формулу использовать для вертикального поиска, большинство гуру Excel считают, что ИНДЕКС/ПОИСКПОЗ намного лучше, чем ВПР. Однако, многие пользователи Excel по-прежнему прибегают к использованию ВПР, т.к. эта функция гораздо проще. Так происходит, потому что очень немногие люди до конца понимают все преимущества перехода с ВПР на связку ИНДЕКС и ПОИСКПОЗ, а тратить время на изучение более сложной формулы никто не хочет.
Далее я попробую изложить главные преимущества использования ПОИСКПОЗ и ИНДЕКС в Excel, а Вы решите – остаться с ВПР или переключиться на ИНДЕКС/ПОИСКПОЗ.
4 главных преимущества использования ПОИСКПОЗ/ИНДЕКС в Excel:
1. Поиск справа налево. Как известно любому грамотному пользователю Excel, ВПР не может смотреть влево, а это значит, что искомое значение должно обязательно находиться в крайнем левом столбце исследуемого диапазона. В случае с ПОИСКПОЗ/ИНДЕКС, столбец поиска может быть, как в левой, так и в правой части диапазона поиска. Пример: покажет эту возможность в действии.
2. Безопасное добавление или удаление столбцов. Формулы с функцией ВПР перестают работать или возвращают ошибочные значения, если удалить или добавить столбец в таблицу поиска. Для функции ВПР любой вставленный или удалённый столбец изменит результат формулы, поскольку требует указывать весь диапазон и конкретный номер столбца, из которого нужно извлечь данные.
Например, если у Вас есть таблица A1:C10, и требуется извлечь данные из столбца B, то нужно задать значение 2 для аргумента col_index_num (номер_столбца) функции ВПР, вот так:
Если позднее Вы вставите новый столбец между столбцами A и B, то значение аргумента придется изменить с 2 на 3, иначе формула возвратит результат из только что вставленного столбца.
Используя ПОИСКПОЗ/ИНДЕКС, Вы можете удалять или добавлять столбцы к исследуемому диапазону, не искажая результат, так как определен непосредственно столбец, содержащий нужное значение. Действительно, это большое преимущество, особенно когда работать приходится с большими объёмами данных. Вы можете добавлять и удалять столбцы, не беспокоясь о том, что нужно будет исправлять каждую используемую функцию ВПР.
3. Нет ограничения на размер искомого значения. Используя ВПР, помните об ограничении на длину искомого значения в 255 символов, иначе рискуете получить ошибку #VALUE! (#ЗНАЧ!). Итак, если таблица содержит длинные строки, единственное действующее решение – это использовать ИНДЕКС/ПОИСКПОЗ.
Предположим, Вы используете вот такую формулу с ВПР, которая ищет в ячейках от B5 до D10 значение, указанное в ячейке A2:
Формула не будет работать, если значение в ячейке A2 длиннее 255 символов. Вместо неё Вам нужно использовать аналогичную формулу ИНДЕКС/ПОИСКПОЗ:
4. Более высокая скорость работы. Если Вы работаете с небольшими таблицами, то разница в быстродействии Excel будет, скорее всего, не заметная, особенно в последних версиях. Если же Вы работаете с большими таблицами, которые содержат тысячи строк и сотни формул поиска, Excel будет работать значительно быстрее, при использовании ПОИСКПОЗ и ИНДЕКС вместо ВПР. В целом, такая замена увеличивает скорость работы Excel на 13%.
Влияние ВПР на производительность Excel особенно заметно, если рабочая книга содержит сотни сложных формул массива, таких как . Дело в том, что проверка каждого значения в массиве требует отдельного вызова функции ВПР. Поэтому, чем больше значений содержит массив и чем больше формул массива содержит Ваша таблица, тем медленнее работает Excel.
С другой стороны, формула с функциями ПОИСКПОЗ и ИНДЕКС просто совершает поиск и возвращает результат, выполняя аналогичную работу заметно быстрее.
ВПР по нескольким критериям с применением массивов — способ 2.
Выше мы уже рассматривали, как при помощи формулы массива можно организовать поиск ВПР с несколькими условиями. Предлагаем еще один способ.
Условия возьмем те же, что и в предыдущем примере.
Формулу в С4 введем такую:
Естественно, не забываем нажать CTRL+Shift+Enter.
Теперь давайте пошагово разберем, как это работает.
Наше задача здесь – также создать дополнительный столбец для работы функции ВПР. Только теперь мы создаем его не на листе рабочей книги Excel, а виртуально.
Как и в предыдущем примере, мы ищем текст из объединенных в одно целое условий поиска.
Далее определяем данные, среди которых будем искать.
Конструкция вида A7:A20&B7:B20&C7:C20;D7:D20 создает 2 элемента. Первый – это объединение колонок A, B и C из исходных данных. Если помните, то же самое мы делали в нашем дополнительном столбце. Второй D7:D20 – это значения, одно из которых нужно в итоге выбрать.
Функция ВЫБОР позволяет из этих элементов создать массив. {1,2} как раз и означает, что нужно взять сначала первый элемент, затем второй, и объединить их в виртуальную таблицу – массив.
В первой колонке этой виртуальной таблицы мы будем искать, а из второй – извлекать результат.
Таким образом, для работы функции ВПР с несколькими условиями мы вновь используем дополнительный столбец. Только создаем его не реально, а виртуально.
LEFT
Задачу обрезание лишних символов из начала строки можно было бы решить и с использованием функции LEFT, которая возвращает указанное количество символов, начиная с 1-го. Функции нужно передать следующие два параметра:
- Поле, подстроку которого нужно получить;
- Количество символов.
Следующий пример формирует ФИО, в котором имя и отчество сокращены:
SELECT vcFamil+' '+left(vcName, 1)+'. '+left(vcSurName, 1)+'.' FROM tbPeoples
Поле «vcFamil» выводится полностью, а вот от имени и отчества выводится только один левый (первый) символ.
Теперь посмотрим, как можно было использовать LEFT для обрезания префикса ‘mr.’:
UPDATE tbPeoples
SET vcFamil=(case LEFT(vcFamil, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
Оператор SQL DELETE и удаление данных с условием
Оператор SQL DELETE предназначен для удаления данных из таблицы. Он имеет следующий синтаксис:
DELETE FROM ИМЯ_ТАБЛИЦЫ
WHERE УСЛОВИЕ
Если не указывать условие, из таблицы будут удалены все строки. Кроме того, следует помнить,
что могут быть удалены лишь строки с первичными ключами, на которые не ссылаются внешние ключи в других
таблицах (более подробно об ограничениях удаления — в ).
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
А скрипт для создания базы данных «Портал объявлений 1», её таблицы и заполения таблицы данных —
в файле по этой ссылке.
Пример 1. Итак, есть база портала объявлений. В ней есть таблица Ads, содержащая
данные о объявлениях, поданных за неделю (более подробно — в , пример 7).
Таблица выглядит так:

| Id | Category | Part | Units | Money |
| 1 | Транспорт | Автомашины | 110 | 17600 |
| 2 | Недвижимость | Квартиры | 89 | 18690 |
| 3 | Недвижимость | Дачи | 57 | 11970 |
| 4 | Транспорт | Мотоциклы | 131 | 20960 |
| 5 | Стройматериалы | Доски | 68 | 7140 |
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
| 10 | Недвижимость | Дома | 47 | 9870 |
| 11 | Досуг | Музыка | 117 | 7605 |
| 12 | Досуг | Игры | 41 | 2665 |
Требуется удалить из таблицы строку, имеющую идентификатор 4. Для этого
пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS
WHERE Id=4
Пример 2. Можно удалить и несколько строк, если в условии применить
оператор сравнения «больше» или «меньше» (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS
WHERE Id>4
В результате в таблице останутся лишь следующие строки:
| Id | Category | Part | Units | Money |
| 5 | Стройматериалы | Доски | 68 | 7140 |
| 6 | Электротехника | Телевизоры | 127 | 8255 |
| 7 | Электротехника | Холодильники | 137 | 8905 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
| 9 | Досуг | Книги | 96 | 6240 |
| 10 | Недвижимость | Дома | 47 | 9870 |
| 11 | Досуг | Музыка | 117 | 7605 |
| 12 | Досуг | Игры | 41 | 2665 |
Пример 3. Аналогично можно удалять строки с заданными значениями
любого столбца. Удалим, например, строки об объявлениях, за которые выручено менее 10000 денежных единиц
(запрос на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ADS
WHERE Money
В результате в таблице останутся лишь следующие строки:
| Id | Category | Part | Units | Money |
| 1 | Транспорт | Автомашины | 110 | 17600 |
| 2 | Недвижимость | Квартиры | 89 | 18690 |
| 3 | Недвижимость | Дачи | 57 | 11970 |
| 4 | Транспорт | Мотоциклы | 131 | 20960 |
| 8 | Стройматериалы | Регипс | 112 | 11760 |
Оператор SQL DELETE и удаление всех данных из таблицы
Для удаления всех строк из таблицы применяется оператор SQL DELETE без условий, заданных в секции WHERE и
без любых других ограничей и условий, например, диапазона удаляемых строк. Таким образом, для удаления
всех строк синтаксис оператора DELETE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
DELETE FROM ИМЯ_ТАБЛИЦЫ
Пример 4. Чтобы удалить все данные из таблицы ADS, достаточно
написать следующий запрос:
DELETE FROM ADS
Если после выполнения этого запроса обратиться к таблице ADS при помощи оператора
SELECT, применяемого для получения выборки данных, то будет выведено сообщение о том, что эта
таблица не содержит данных.
Оператору DELETE без условий и ограничений аналогичен оператор TRUNCATE TABLE. Он
также удаляет из таблицы все строки, но выполняется намного быстрее.
Пример 5. Запрос на удаление всех данных из таблицы ADS
при помощи оператора TRUNCATE TABLE будет следующим (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
TRUNCATE TABLE ADS
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об
операторах INSERT, UPDATE, HAVING и UNION.
Поделиться с друзьями
| Назад | Листать | Вперёд>>> |
group_concat()
Для каждого пользователя с помощью group_concat() составляется список идентификаторов его сообщений, отсортированный по убыванию даты. Используя substring_index(), вырезаем первые 3 значения post_id, и по ним извлекается вся строка.
select t1.* from posts t1 join(select user_id, substring_index(group_concat(post_id order by date_added desc), ‘,’, 3) x from posts t2 group by user_id) ton t.user_id = t1.user_id and find_in_set(t1.post_id,x);
К сожалению, MySQL не умеет решать уравнения, поэтому для поиска по условию с find_in_set будет просканирована вся таблица сообщений. Есть обходной путь: используя строковые функции и union all, вырезать id сообщений из списка и объединить их в один столбец. Тогда оптимизатор сможет использовать их для поиска нужных строк в таблице сообщений, а не наоборот.
with cte as (select substring_index(group_concat(post_id order by date_added desc), ‘,’, 3) x from posts group by user_id)select posts.* from (select substring_index(x,’,’,1) post_id from cteunion allselect substring_index(substring_index(x,’,’,2),’,’,-1) from cteunion allselect substring_index(x,’,’,-1) from cte) tjoin posts on t.post_id = posts.post_id;
Будет ли такой трюк эффективным зависит от:
- сколько строк из группы нужно выбрать
- есть ли возможность использовать with (доступны с MariaDB 10.2 / MySQL 8). Если в явном виде дублировать from-подзапрос, то каждый из них будет материализован в отдельную временную таблицу.
Этот способ можно применять для выборки 3 случайных сообщений каждого пользователя. Для этого достаточно указать иной вид сортировки внутри group_concat: order by rand() вместо order by date_added desc.
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
![]()
Текст запроса
SELECT NameProduct, price, category,
rank() over (order by price desc) ,
ROW_NUMBER() over (order by price desc) as
FROM selling
![]()
Текст запроса
SELECT NameProduct, price, category,
rank() over (partition by category order by price desc) ,
ROW_NUMBER() over (partition by category order by price desc) as
FROM selling
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример
![]()
Текст запроса
SELECT NameProduct, price, category,
NTILE(3)over (order by price desc)
FROM selling
В заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой
![]()
Текст запроса
SELECT NameProduct, price, category,
ROW_NUMBER() over (order by price desc) as ,
rank() over (order by price desc) ,
DENSE_RANK () over (order by price desc) ,
NTILE(3)over (order by price desc)
FROM selling
На этом я думаю по ранжирующим функциям достаточно, в следующих статьях мы продолжим изучение Transact-SQL, а на этом пока все. Удачи!
Нравится15Не нравится
пользовательские переменные
Та же идея, что и в предыдущем варианте, только реализована с помощью пользовательских переменных (user variables). Актуально для версий, в которых нет оконных функций.


select post_id, user_id, date_added, post_text from(select posts.*, if(@gr=user_id, @i:=@i+1, @i:=1 + least(@gr:=user_id,)) xfrom posts, (select @i:=, @gr:=) t order by user_id, date_added desc) t1 where x <=3;
Как и в примере с row_number(), мы нумеруем сообщения каждого пользователя в порядке убывания даты добавления (только делаем это с помощью пользовательских переменных), затем оставляем только те строки, у которых № меньше или равен 3.
Способ можно применять и для выборки нескольких случайных сообщений юзера. Однако простая замена сортировки по убыванию даты на случайную не даст нужного эффекта.
select post_id, user_id, date_added, post_text from(select t2.*, if(@gr=user_id, @i:=@i+1, @i:=1 + least(@gr:=user_id,)) xfrom (select posts.*, rand() q, @z:=1 from posts) t2, (select @i:=, @gr:=) t order by user_id, q) t1 where x <=3
Обратите внимание на добавление ещё одной переменной @z:=1, которая более нигде не применяется. С некоторых пор оптимизатор научился упрощать тривиальные с его точки зрения from-подзапросы, перенося условия из них во внешний запрос
Однако, если в подзапросе используются переменные, то пока оптимизатор материализует такие подзапросы.
В общем, пользовательские переменные — мощный инструмент написания и оптимизации запросов, но нужно быть очень внимательными при работе с ними, понимать на каком эффекте основан, используемый вами трюк, и проверять работоспособность в новых версиях. Подробнее см Оптимизация запросов MySQL с использованием пользовательских переменных
Строковые функции в Python
Python предоставляет различные встроенные функции, которые используются для работы со строками.
| Метод | Описание |
|---|---|
| Выводит первый символ строки заглавными буквами. Эта функция устарела в python3 | |
| Возвращает версию строки, пригодную для сравнений без регистра. | |
| Возвращает строку, заполненную пробелами, причем исходная строка центрируется с равным количеством пробелов слева и справа. | |
| Подсчитывает количество вхождений подстроки в строку между начальным и конечным индексом. | |
| Декодирует строку. | |
| Кодирование строки. Кодировка по умолчанию — . | |
| Возвращает булево значение, если строка заканчивается заданным суффиксом между begin и end. | |
| Определяет табуляцию в строке до нескольких пробелов. По умолчанию количество пробела равно 8. | |
| Возвращает значение индекса строки, в которой найдена подстрока между начальным и конечным индексами. | |
| Возвращает форматированную версию строки, используя переданное значение. | |
| Выбрасывает исключение, если строка не найдена. Работает так же, как и метод . | |
| Возвращает true, если символы в строке являются буквенно-цифровыми, т.е. алфавитами или цифрами, и в ней есть хотя бы один символ. В противном случае возвращается . | |
| Возвращает , если все символы являются алфавитными и есть хотя бы один символ, иначе . | |
| Возвращает , если все символы строки являются десятичными. | |
| Возвращает , если все символы являются цифрами и есть хотя бы один символ, иначе . | |
| Возвращает , если строка является действительным идентификатором. | |
| Возвращает , если символы строки находятся в нижнем регистре, иначе . | |
| Возвращает , если строка содержит только числовые символы. | |
| Возвращает , если все символы строки являются печатными или строка пустая, в противном случае возвращает . | |
| Возвращает , если символы строки находятся в верхнем регистре, иначе . | |
| Возвращает , если символы строки являются пробелами, иначе . | |
| Возвращает , если строка имеет правильный заголовок, и в противном случае. Заголовок строки — это строка, в которой первый символ в верхнем регистре, а остальные символы в нижнем регистре. | |
| Он объединяет строковое представление заданной последовательности. | |
| Возвращает длину строки. | |
| Возвращает строки, заполненные пробелами, с исходной строкой, выровненной по левому краю до заданной ширины. | |
| Он преобразует все символы строки в нижний регистр. | |
| Удаляет все пробелы в строке, а также может быть использован для удаления определенного символа из строки. | |
| Он ищет разделитель в строке и возвращает часть перед ним, сам разделитель и часть после него. Если разделитель не найден, возвращается кортеж в виде переданной строка и двух пустых строк. | |
| Возвращает таблицу перевода для использования в функции . | |
| Заменяет старую последовательность символов на новую. Если задано значение , то заменяются все вхождения. | |
| Похож на , но обходит строку в обратном направлении. | |
| Это то же самое, что и , но обходит строку в обратном направлении. | |
| Возвращает строку с пробелами, исходная строка которой выровнена по правому краю на указанное количество символов. | |
| Он удаляет все пробелы в строке, а также может быть использован для удаления определенного символа. | |
| Он аналогичен функции , но обрабатывает строку в обратном направлении. Возвращает список слов в строке. Если разделитель не указан, то строка разделяется в соответствии с пробелами. | |
| Разделяет строку в соответствии с разделителем . Строка разделяется по пробелу, если разделитель не указан. Возвращает список подстрок, скомпонованных с разделителем. | |
| Он возвращает список строк в каждой строке с удаленной строкой. | |
| Возвращает булево значение, если строка начинается с заданной строки между и . | |
| Он используется для выполнения функций и над строкой. | |
| Он инвертирует регистр всех символов в строке. | |
| Он используется для преобразования строки в заглавный регистр, т.е. строка будет преобразована в . | |
| Он переводит строку в соответствии с таблицей перевода, переданной в функцию . | |
| Он преобразует все символы строки в верхний регистр. | |
| Возвращает исходную строку, дополненную нулями минимального количества символов (параметр ); предназначена для чисел, сохраняет любой заданный знак (за вычетом одного нуля). | |
| Ищет последнее вхождение указанной строки и разбивает строку на кортеж, содержащий три элемента (часть перед указанной строкой, саму строку и часть после нее). |
Сводка
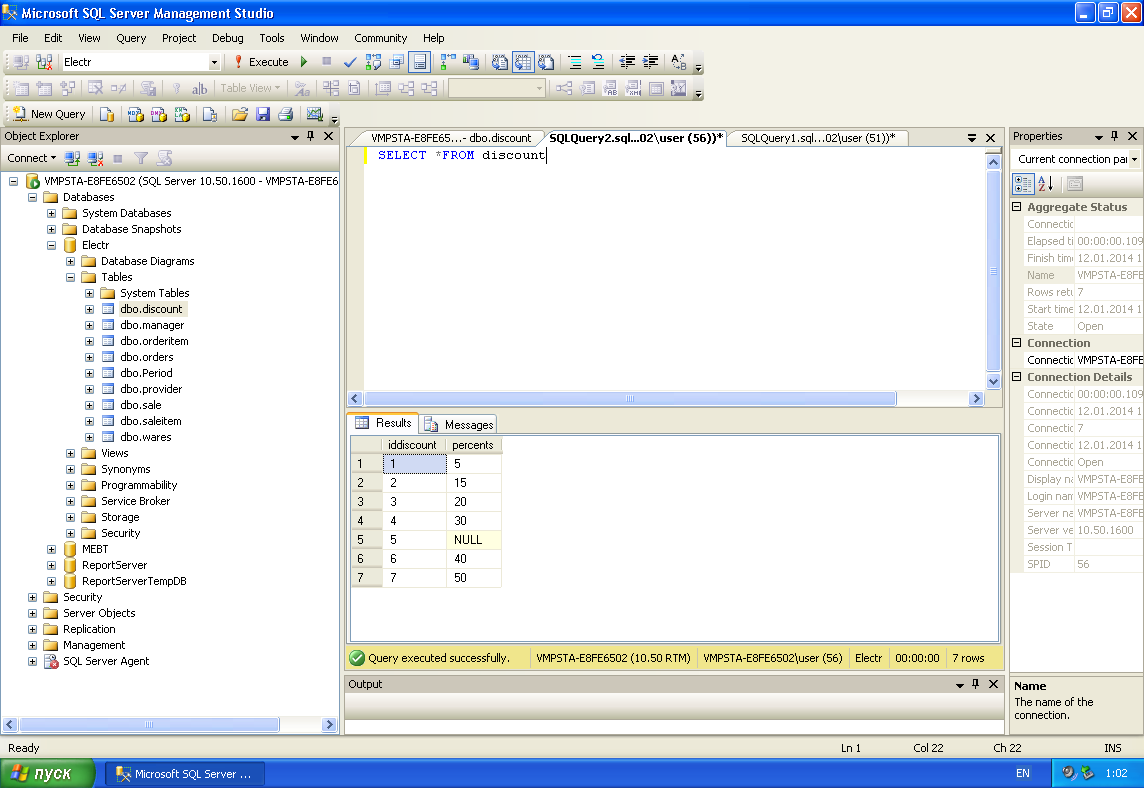
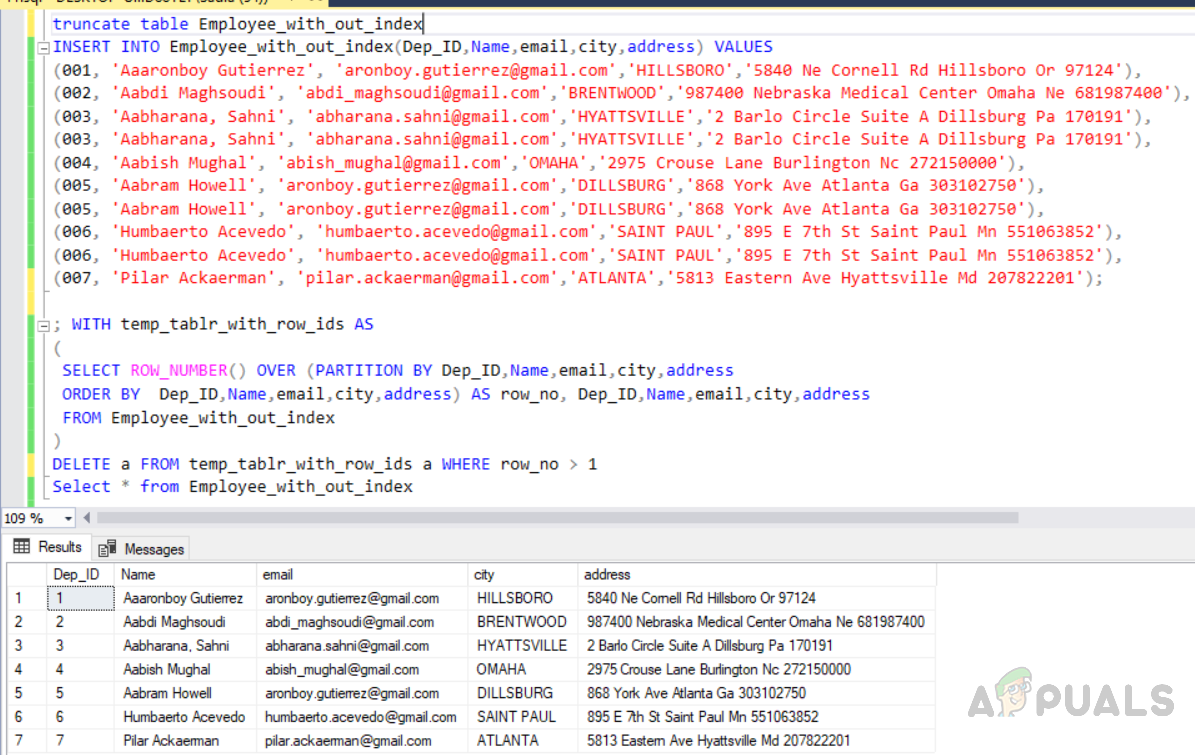
Существует два распространенных метода, которые можно использовать для удаления дублирующихся записей из SQL Server таблицы. Для демонстрации сначала создайте пример таблицы и данных:
Затем попробуйте следующие методы, чтобы удалить дублирующиеся строки из таблицы.
Способ 1
Запустите следующий сценарий:
Этот скрипт принимает следующие действия в данном порядке:
- Перемещает один экземпляр любой дублирующейся строки в исходной таблице в дублирующую таблицу.
- Удаляет все строки из исходной таблицы, которые также находятся в дублирующей таблице.
- Перемещает строки в таблицу дубликатов обратно в исходную таблицу.
- Сбрасывает таблицу дубликата.
Этот метод прост. Однако для создания дублирующей таблицы в базе данных необходимо иметь достаточно места. Этот метод также накладные расходы, так как данные перемещаются.
Кроме того, если в вашей таблице есть столбец IDENTITY, при восстановлении данных в исходной таблице необходимо использовать set IDENTITY_INSERT ON.
Способ 2
Функция ROW_NUMBER, которая была представлена в Microsoft SQL Server 2005 г., значительно упрощает эту операцию:
Этот скрипт принимает следующие действия в данном порядке:
- Использует функцию для раздела данных на основе которых может быть один или несколько столбцов, разделенных запятой.
- Удаляет все записи, которые получили значение больше 1. Это значение указывает на то, что записи являются дубликатами.
Из-за выражения скрипт не сортировать разделимые данные на основе каких-либо условий. Если в логике удаления дубликатов необходимо выбрать, какие записи удалять, а какие хранить в соответствии с порядком сортировки других столбцов, для этого можно использовать выражение ORDER BY.
LTRIM и RTRIM
Функция LTRIM убирает все символы пробела в начале строки, а RTRIM убирает пробелы в конце строки. Допустим, что пользователь при вводе фамилии в самом начале случайно зацепил клавишу пробела. Получилось, что в базе хранится две фамилии:
Иванов Иванов
Когда смотришь на эти фамилии, то видно, что вторая строка сдвинута вправо за счет пробела вначале. Это значит, что база данных будет воспринимать эти значения по-разному. Чтобы избавится от лишних пробелов, как раз используют функции LTRIM и RTRIM. Например:
SELECT *
FROM tbPeoples
WHERE LTRIM(vcFamil)=LTRIM(' Сидоров')
В этом примере поле «vcFamil» сравнивается с фамилией Сидоров, с пробелом в начале. Чтобы убрать пробел используется функция LTRIM. В следующем примере мы убираем и левые и правые пробелы:
-- Убрать лишние пробелы
SELECT *
FROM tbPeoples
WHERE vcFamil=LTRIM(RTRIM(' Сидоров '))
Если честно, то пробелы справа убираются сервером автоматически. Выполните следующий запрос и убедитесь сами:
SELECT * FROM tbPeoples WHERE vcFamil='Сидоров '
Если работник с фамилией Сидоров (без пробелов в конце) существует в таблице, и запрос отобразил его, то сервер автоматически убрал пробел.
Редактирование элементов таблицы
Иногда возникают ситуации, когда необходимо вставить в таблицу столбец или строку, изменить значение элемента или название колонки. Наша таблица — не исключение и нуждается в доработке.
Добавление строк
Добавим в таблицу данные о двух новых студентах: Иване и Олеге. Для этого необходимо создать новую структуру — список (list), В список мы по порядку вносим параметры, совпадающие со структурой таблицы (напомню, что в кавычках мы пишем нечисловые типы данных):
После, при помощи функции rbind (от англ. row bind, что дословно означает «связать строчки») мы объединим эти два списка с нашей таблицей:
Добавление столбцов
Теперь у нас в таблице два Ивана и два Олега. В данном случае хорошо было бы прописать для каждого студента свой идентификационный номер (ID), чтобы не запутаться, кто есть кто. Для этого создадим структуру, которая называется вектор (последовательность элементов одного типа). В него мы запишем последовательность от 1 до 22, так, чтобы у каждого из наших 22 студентов был свой уникальный ID:
Теперь объединим наш вектор с таблицей, воспользовавшись функцией cbind (от англ. column bind):
Не забудьте поменять тип данных нового столбца на символьный:
В качестве еще одного примера добавления новых столбцов с данными в таблицу, рассчитаем индекс массы тела (BMI) для каждого студента. Для этого, мы воспользуемся новым способом: напишем математическую формулу индекса на языке R и присвоим ей новое имя столбца «BMI» внутри нашей таблицы:
Проверьте, что получилось, используя уже знакомые нам функции head и str
Удаление строк и столбцов
Существует относительно «универсальная формула» для удаления элементов таблицы: new.data <- my.data Для того, чтобы корректно ее использовать необходимо запомнить несколько правил:
- После имени таблицы пространство внутри квадратных скобок следует разделить на две части запятой.
- Все, что находится до запятой, относится к строчкам, все что после — к столбцам.
- Поставьте минус перед номером столбца или номером строки, которую собираетесь удалить.
- Если таких элементов несколько, используйте функцию c(…): внутри скобок перечисление элементов через запятую.
В нашем случае, удалять из таблицы ничего не надо, но я покажу пару примеров, назвав «укороченные» таблицы именами «trash1», «trash2», «trash3», «trash4»:
Изменение имен столбцов и данных в ячейках:
Переименуем колонку «Rhesus.factor» на укороченное «Rhesus». Для этого нужно вызвать функцию names, написать в параметрах функции имя таблицы и номер столбца, и присвоить ему новое имя:
Изменение данные в ячейках таблицы не представляет особой сложности. В квадратных скобках прописываем координаты нужной ячейки (до запятой — строка, после запятой — столбец) и присваиваем новое значение:
![]()
После всех наших манипуляций мы должны получить вот такую таблицу данных:
join + group by
Та же идея, что и в предыдущем случае, только реализована через самообъединение таблицы и группировку. Каждой строке сопоставляется набор строк с тем же user_id и большей или равной date_added, после группировки мы получаем для каждой строки (количество сообщений того же пользователя с большей датой добавления) + 1. Иными словами, если мы пронумеруем сообщения пользователя по убыванию date_added, то полученное число будет порядковым номером строки в этой нумерации.
select t1.* from
posts t1 join posts t2 on t1.user_id=t2.user_id and t2.date_added >= t1.date_addedgroup by t1.post_id having count(*) <=3;
Этот способ часто рекомендуют в интернете в качестве решения задачи (встречаются вариации с left join). Однако его производительность не самая оптимальная в сравнении с другими методами, рассмотренными в этой статье. Вероятно, причина популярности этого решения в том, что join многим интуитивно представляется более простым решением.
Обратите внимание: в режиме ONLY_FULL_GROUP_BY придется усложнять запрос: сначала выбрать нужные post_id, затем по ним дополнительным join извлечь остальные поля (подробнее см статью Группировка в MySQL). Простое перечисление всех полей в части group by в разы увеличивает время выполнения запроса
Строго говоря, этот способ как и предыдущий (с помощью зависимого подзапроса) можно использовать для выборки случайных строк из группы, но только в новых версиях, где есть поддержка обобщенных табличных выражений. Вместо исходной таблицы в запросе будет использоваться результат select posts.*, rand() new_col from posts, и сравнение не по полю date_added, а по new_col.
Будем считать, что варианты 1 и 2 не применимы для поиска случайных строк в группах, потому что:
- в старых версиях они действительно не применимы

- в новых их производительность будет существенно хуже по сравнению с иными доступными вариантами решений (см способы 4 и 6)
Заключение
Описанные выше способы редактирования данных в таблице не уникальны, существует множество других методов и команд, позволяющих получить желаемый результат. Я рассказал лишь о наиболее простых и часто используемых. Для более детального ознакомления с этой темой я хотел бы порекомендовать два источника на английском языке:
- сайт http://stackoverflow.com/ (уже подробно разобраны тысячи вопросов по этой теме)
- книгу-справочник «R book» by Michael J. Crawley (легко найти бесплатную PDF версию в интернете).
Если у Вас возникли вопросы или проблемы с редактированием таблиц данных, Вы всегда можете оставить комментарий под этой статьей, и он не останется без внимания. А в качестве продолжения, читайте следующую статью, посвященную сохранению данных в среде R.





