
Автоматизация после сбоев/перезагрузок
Чтобы не потерять все настроенные нами параметры, добавим в crontab периодическое сохранение правил IPSet и iptables.
sudo crontab -e # Каждую первую минуту каждого часа, то есть раз в час 1 * * * * /bin/bash root ipset save > /opt/ipset.rules 1 * * * * iptables-save root > /opt/firewall.rules
И в /etc/rc.local добавим восстановление:
ipset restore < /opt/routers/ipset.rules iptables-restore < /opt/routers/iptables.rules
А теперь напишем скрипт, который будет обходить правила iprule и iproute и в случае, если чего-то не хватает, допишет недостающее. Скрипт можно сделать демоном, чтобы он постоянно висел в памяти и мониторил состояние системы, а можно запускать только при старте ОС. В целом второго варианта вполне достаточно.
Напоследок напишем скрипт, который позволит нам более удобно добавлять IP-адреса в списки IPSet, чтобы каждый раз не ломиться в консоль. Этот скрипт выглядит так:
#!/bin/bash test=$(zenity --entry --title="Добавление адреса в ipset списки " --text="Введите адрес ip или домена") initip=$(dig +short "$test" -u 1.1.1.1) if ; then zenity --password --title="Введите пароль администратора" | sudo -S ipset -exist -A vpn "$test" echo "$test" >> /opt/iptovpn.txt else zenity --password --title="Введите пароль администратора" | sudo -S ipset -exist -A vpn "$initip" echo "$initip" >> /opt/iptovpn.txt fi sudo ipset save > /opt/ipset.rules
При запуске мы вводим имя домена или сразу IP-адрес. Скрипт переварит и то и другое, после чего и запихает IP в список IPSet.
Также в архиве вы найдете скрипт add_in_file, который читает файл со списком доменов, получает IP и складывает в списки IPSet.
Предоставление доступа к сервисам на шлюзе
Предположим, что на нашем шлюзе запущен некий сервис, который должен отвечать на запросы поступающие из сети интернет. Допустим он работает на некотором TCP порту nn. Чтобы предоставить доступ к данной службе, необходимо модифицировать таблицу filter в цепочке INPUT (для возможности получения сетевых пакетов, адресованных локальному сервису) и таблицу filter в цепочке OUTPUT (для разрешения ответов на пришедшие запросы).
Итак, мы имеем , который маскарадит (заменяет адрес отправителя на врешний) пакеты во внешнюю сеть. И разрешает принимать все установленные соединения. Предоставление доступа к сервису будет осуществляться с помощью следующих разрешающих правил:
netfilter:~# iptables -A INPUT -p TCP --dport nn -j ACCEPT netfilter:~# iptables -A OUTPUT -p TCP --sport nn -j ACCEPT
Данные правила разрешают входящие соединения по протоколу tcp на порт nn и исходящие соединения по протоколу tcp с порта nn. Кроме этого, можно добавить дополнительные ограничивающие параметры, например разрешить входящие соединения только с внешнего интерфейса eth0 (ключ -i eth0) и т.п.
Как использовать Tor как прозрачный прокси
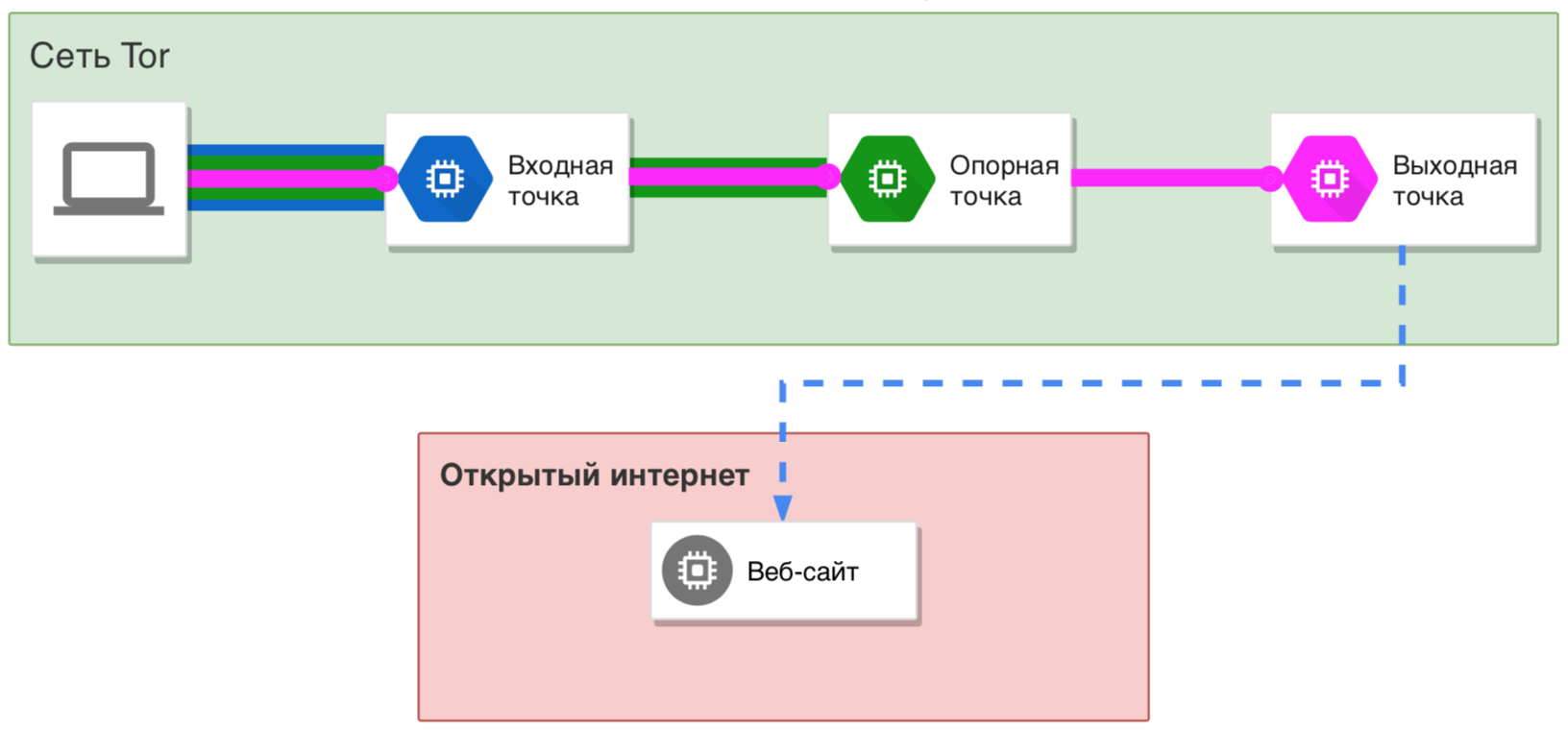
Сеть Tor, в первую очередь, предназначена для обеспечения анонимности пользователей при выходе в Интернет за счёт сокрытия их реального IP адреса. Передаваемые по сети данные шифруются, но на выходном узле, который делает непосредственный запрос к сайту и получает от него ответ, трафик находится в своём исходном состоянии (то есть тот трафик, который шифруется сторонними средствами, например, HTTPS — он зашифрован, а трафик, передаваемый в виде простого текста, доступен для выходной ноды в незашифрованном виде).
Сеть Tor в первую очередь предназначена для доступа к веб-сайтам, по этой причине, а также чтобы избежать сбора отпечатков пользователя (например, о версии операционной системы по особенностям сетевых пакетов), сеть Tor поддерживает очень ограниченный набор передаваемого трафика. Например, через сеть Tor можно сделать запрос к веб-сайту (протокол TCP), но невозможно передать UDP пакеты или сырые пакеты (запрещено всё, кроме полноценного подключения к сайту).
Сеть Tor подходит для:
- сокрытия IP от сайта, к которому вы подключаетесь
- обход блокировок сайтов
- DNS запросов через Tor (DNS нужен для получения IP адресов сайтов — ваш браузер и система постоянно отправляют эти запросы). При этом не используются UDP пакеты, а данные передаются в зашифрованном виде
- для сканирования открытых портов методом создания полного подключения (более медленный и более заметный по сравнению с методом полуоткрытых соединений)
По этой причине, когда мы говорим «перенаправление всего трафика через Tor» на самом деле имеется ввиду «перенаправление всего трафика, поддерживаемого этой сетью, через Tor».
Значительная часть трафика просто не может быть отправлена через сеть Tor, например, пинг, некоторые методы трассировки, сканирование полуоткрытыми соединениями, DNS запросы по UDP протоколу и т. д. Исходя из этого возникает другой вопрос — что делать с трафиком, который невозможно передать через сеть Tor: отправлять к целевому хосту минуя сеть Tor или блокировать?
Таблицы ipatables
Над цепочками правил в iptables есть еще один уровень абстракции, и это таблицы. В системе есть несколько таблиц, и все они имеют стандартный набор цепочек input, forward и output. Таблицы предназначены для выполнения разных действий над пакетами, например для модификации или фильтрации
Сейчас это для вас не так важно и будет достаточно знать что фильтрация пакетов iptables осуществляется в таблице filter. Но мы рассмотрим их все:
- raw — предназначена для работы с сырыми пакетами, пока они еще не прошли обработку;
- mangle — предназначена для модификации пакетов;
- nat — обеспечивает работу nat, если вы хотите использовать компьютер в качестве маршрутизатора;
- filter — основная таблица для фильтрации пакетов, используется по умолчанию.
С теорией почти все, теперь давайте рассмотрим утилиту командной строки iptables, с помощью которой и выполняется управление системой iptables.
Пример ACL
Данный список доступа обеспечивает простой и в тоже время вполне реальный пример обычных записей, требуемых в списке ACL для транзитного трафика. Эти базовые списки ACL необходимо сопоставлять с элементами локальных конфигураций, характерных для каждого из узлов.
Примечание. Не забывайте об этих советах при использовании списка ACL для транзитного трафика
-
Ключевое слово log может быть использовано для получения дополнительной информации об источниках и назначениях для данного протокола. Кроме того, данное ключевое слово предоставляет подробное объяснение использования списка управления доступом, успешный выход к записям в списке ACL, который использует ключевое слово log для повышения коэффициента использования CPU. Влияние регистрации на производительность системы зависит от платформы.
-
Сообщения о недоступности ICMP генерируются для пакетов, которые в административном порядке запрещены списком ACL. Это может повлиять на производительность маршрутизатора и канала. Используйте команду no ip unreachables для отключения сообщений IP-недоступности в интерфейсе, где развернут транзитный (граничный) список ACL.
-
Этот ACL может быть внутренне развернут с помощью всех операторов permit для проверки того, что законный бизнес-трафика не отклоняется. Как только законный бизнес-трафик определен и рассчитан, могут быть настроены специальные элементы deny.
Видео
https://youtube.com/watch?v=feYZqq7gFrM
Онлайн курс «SRE практики и инструменты»
Если у вас есть желание научиться строить и поддерживать высокодоступные и надежные системы, рекомендую познакомиться с онлайн-курсом «SRE практики и инструменты» в OTUS. Курс не для новичков, для поступления нужны базовые знания по сетям и Linux. Обучение длится 3 месяц, после чего успешные выпускники курса смогут пройти собеседования у партнеров.
На курсе вы узнаете как:
- Внедрить SRE практики в своей организации
- Управлять надежностью, доступностью и эффективностью сервисов
- Управлять изменениями
- Осуществлять мониторинг
- Реагировать на инциденты и производительность
- Работать со следующим технологическим стеком: Linux, AWS, GCP, Kubernetes, Ansible, Terraform, Prometheus, Go, Python.
Проверьте себя на вступительном тесте и смотрите подробнее программу по .
Показать статус.
Примерный вывод команды для неактивного файрвола:
Chain INPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain FORWARD (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination
Для активного файрвола:
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 state INVALID
394 43586 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
93 17292 ACCEPT all -- br0 * 0.0.0.0/0 0.0.0.0/0
1 142 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- br0 br0 0.0.0.0/0 0.0.0.0/0
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 state INVALID
0 0 TCPMSS tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp flags:0x06/0x02 TCPMSS clamp to PMTU
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
0 0 wanin all -- vlan2 * 0.0.0.0/0 0.0.0.0/0
0 0 wanout all -- * vlan2 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- br0 * 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT 425 packets, 113K bytes)
pkts bytes target prot opt in out source destination
Chain wanin (1 references)
pkts bytes target prot opt in out source destination
Chain wanout (1 references)
pkts bytes target prot opt in out source destination
Где:
-L : Показать список правил.
-v : Отображать дополнительную информацию. Эта опция показывает имя интерфейса, опции, TOS маски. Также отображает суффиксы ‘K’, ‘M’ or ‘G’.
-n : Отображать IP адрес и порт числами (не используя DNS сервера для определения имен. Это ускорит отображение).
Списки ACL и фрагментированные пакеты
Списки ACL имеют ключевое слово fragments, которое активирует специальный режим обработки фрагментированных пакетов. В общем случае, на неначальные фрагменты, совпадающие с операторами уровня 3 (протокол, адрес источника и адрес назначения) – независимо от информации уровня 4 в списке управления доступом – оказывают влияние оператор permit или deny совпадающих записей
Обратите внимание на то, что использование ключевого слова fragments может привести к большей степени структурированности запрещенных или разрешенных неначальных фрагментов
Фильтрация фрагментов добавляет дополнительный уровень защиты от атаки DoS (отказ от обслуживания), которая использует только неначальные фрагменты (когда FO > 0). Использование оператора deny для неначальных фрагментов в начале ACL закрывает доступ в маршрутизатор всем неначальным фрагментам. В редких случаях допустимая операция может потребовать фрагментации и, таким образом, будет отфильтрована при наличии в списке ACL оператора deny fragment. К условиям, вызывающим фрагментацию, можно отнести использование аутентификации цифровых сертификатов для ISAKMP, а также просмотр IPSec NAT.
В качестве примера рассмотрим неполный список ACL.
Добавление этих записей в начало списка управления доступом закрывает доступ в сеть всем неначальным фрагментам, в то время как нефрагментированные пакеты или исходные фрагменты передаются в следующие строки списка ACL (оператор deny fragment на них не действует). Предыдущий фрагмент списка ACL также способствует классификации атаки, поскольку каждый протокол – UDP, TCP и ICMP – увеличивает отдельные счетчики в ACL.
Поскольку большинство атак основано на волновом распространении фрагментированных пакетов, фильтрация входящих фрагментов во внутреннюю сеть обеспечивает дополнительные защитные меры и помогает удостовериться в том, что атака не может внедриться во фрагмент простым совпадением правил уровня 3 в списке ACL.
Более подробно параметры рассмотрены в документе Списки управления доступом и IP-фрагменты.
Проброс портов
Если в вашей внутренней сети есть сервер, который должен быть доступен извне, можно воспользоваться целевым действием -j DNAT цепочки PREROUTING в таблице NAT и указать IP-адрес и порт места назначения, на которые будут перенаправляться входящие пакеты, запрашивающие соединение с вашей внутренней службой. Например, если нужно перенаправлять входящие HTTP-запросы по порту 80 на выделенный HTTP-сервер Apache по адресу 172.31.0.23, выполните команду:
sudo iptables -t nat -A PREROUTING -i eth0 -p tcp --dport 80 -j DNAT --to 172.31.0.23:80
Данное правило определяет использование встроенной цепочки PREROUTING в таблице NAT для перенаправления входящих HTTP-запросов на порт 80 указанного IP-адреса 172.31.0.23. Такой способ трансляции сетевых адресов называется перенаправлением или пробросом портов.
torctl
Далее рассматриваемые программы очень схожи, они все используют Tor + iptables, но все чуть по-разному.
Начнём с самой многофункциональной программы torctl.
Эта программа написана для BlackArch, но довольно легко портируется на другие дистрибутивы.
Установка torctl в Kali Linux
sudo apt install tor macchanger secure-delete git clone https://github.com/BlackArch/torctl cd torctl sudo mv service/* /etc/systemd/system/ sudo mv bash-completion/torctl /usr/share/bash-completion/completions/torctl sed -i 's/start_service iptables//' torctl sed -i 's/TOR_UID="tor"/TOR_UID="debian-tor"/' torctl sudo mv torctl /usr/bin/torctl cd .. && rm -rf torctl/ torctl --help
Установка torctl в BlackArch
sudo pacman -S torctl
Чтобы узнать свой текущий IP, выполните:
torctl ip
Чтобы запустить Tor в качестве прозрачного прокси:
sudo torctl start
![]()
Для проверки статуса служб:
torctl status
Если вы хотите поменять IP в сети Tor:
sudo torctl chngid
Для работы с Интернетом напрямую, без Tor, запустите:
sudo torctl stop
Чтобы поменять MAC адреса на всех сетевых интерфейсах выполните команду:
sudo torctl chngmac
Чтобы вернуть исходные MAC адреса:
sudo torctl rvmac
Следующая команда добавит службу torctl в автозагрузку, то есть сразу после включения компьютера весь трафик будет пересылаться через Tor:
sudo systemctl enable torctl-autostart.service
Для удаления службы из автозагрузки выполните:
sudo systemctl disable torctl-autostart.service
Ещё вы можете включить автоматическую очистку памяти каждый раз при выключении компьютера:
sudo systemctl enable torctl-autowipe.service
Для отключения это функции:
sudo systemctl disable torctl-autowipe.service
Этот скрипт знает о существовании IPv6 трафика и успешно блокирует его. Запросы DNS перенаправляются через Tor.
Настройка netfilter/iptables для подключения нескольких клиентов к одному соединению.
Давайте теперь рассмотрим наш Linux в качестве шлюза для локальной сети во внешнюю сеть Internet. Предположим, что интерфейс eth0 подключен к интернету и имеет IP 198.166.0.200, а интерфейс eth1 подключен к локальной сети и имеет IP 10.0.0.1. По умолчанию, в ядре Linux пересылка пакетов через цепочку FORWARD (пакетов, не предназначенных локальной системе) отключена. Чтобы включить данную функцию, необходимо задать значение 1 в файле /proc/sys/net/ipv4/ip_forward:
netfilter:~# echo 1 > /proc/sys/net/ipv4/ip_forward
Чтобы форвардинг пакетов сохранился после перезагрузки, необходимо в файле /etc/sysctl.conf раскомментировать (или просто добавить) строку net.ipv4.ip_forward=1.
Итак, у нас есть внешний адрес (198.166.0.200), в локальной сети имеется некоторое количество гипотетических клиентов, которые имеют адреса из диапазона локальной сети и посылают запросы во внешнюю сеть. Если эти клиенты будут отправлять во внешнюю сеть запросы через шлюз «как есть», без преобразования, то удаленный сервер не сможет на них ответить, т.к. обратным адресом будет получатель из «локальной сети». Для того, чтобы эта схема корректно работала, необходимо подменять адрес отправителя, на внешний адрес шлюза Linux. Это достигается за счет (маскарадинг) в , в .
netfilter:~# iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A FORWARD -m conntrack --ctstate NEW -i eth1 -s 10.0.0.1/24 -j ACCEPT netfilter:~# iptables -P FORWARD DROP netfilter:~# iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Итак, по порядку сверху-вниз мы разрешаем уже установленные соединения в цепочке FORWARD, таблице filter, далее мы разрешаем устанавливать новые соединения в цепочке FORWARD, таблице filter, которые пришли с интерфейса eth1 и из сети 10.0.0.1/24. Все остальные пакеты, которые проходят через цепочку FORWARD — отбрасывать. Далее, выполняем маскирование (подмену адреса отправителя пакета в заголовках) всех пакетов, исходящих с интерфейса eth0.
Примечание. Есть некая общая рекомендация: использовать правило -j MASQUERADE для интерфейсов с динамически получаемым IP (например, по DHCP от провайдера). При статическом IP, -j MASQUERADE можно заменить на аналогичное -j SNAT —to-source IP_интерфейса_eth0. Кроме того, SNAT умеет «помнить» об установленных соединениях при кратковременной недоступности интерфейса. Сравнение MASQUERADE и SNAT в таблице:
Кроме указанных правил так же можно нужно добавить правила для фильтрации пакетов, предназначенных локальному хосту — как описано в . То есть добавить запрещающие и разрешающие правила для входящих и исходящих соединений:
netfilter:~# iptables -P INPUT DROP netfilter:~# iptables -P OUTPUT DROP netfilter:~# iptables -A INPUT -i lo -j ACCEPT netfilter:~# iptables -A OUTPUT -o lo -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT netfilter:~# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000 netfilter:~# iptables -A OUTPUT -p TCP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A OUTPUT -p UDP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A INPUT -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A INPUT -p UDP -m state --state ESTABLISHED,RELATED -j ACCEPT
В результате, если один из хостов локальной сети, например 10.0.0.2, попытается связаться с одним из интернет-хостов, например, 93.158.134.3 (ya.ru), при , их исходный адрес будет подменяться на внешний адрес шлюза в цепочке POSTROUTING таблице nat, то есть исходящий IP 10.0.0.2 будет заменен на 198.166.0.200. С точки зрения удаленного хоста (ya.ru), это будет выглядеть, как будто с ним связывается непосредственно сам шлюз. Когда же удаленный хост начнет ответную передачу данных, он будет адресовать их именно шлюзу, то есть 198.166.0.200. Однако, на шлюзе адрес назначения этих пакетов будет подменяться на 10.0.0.2, после чего пакеты будут передаваться настоящему получателю в локальной сети. Для такого обратного преобразования никаких дополнительных правил указывать не нужно — это будет делать все та же операция MASQUERADE, которая помнит какой хост из локальной сети отправил запрос и какому хосту необходимо вернуть пришедший ответ.
Примечание: желательно негласно принято, перед всеми командами iptables очищать цепочки, в которые будут добавляться правила:
netfilter:~# iptables -F ИМЯ_ЦЕПОЧКИ
Автозагрузка правил iptables
1. Загрузка правил с помощью скрипта
Сохраненные правила с помощью утилиты iptables-save можно восстанавливать с помощью скрипта, запускаемого при каждом запуске операционной системы. Для этого необходимо выполнить следующие действия:
Сохранить набор правил межсетевого экрана с помощью команды:
Для запуска набора правил при старте операционной системы перед включением сетевого интерфейса мы создаем новый файл с помощью команды:
Заметим — в сети есть много вариантов места размещения скрипта на локальной машине, но я считаю именно размещение в папке if-pre-up.d наиболее верным, так как при этом скрипт будет выполнятся перед включением сетевого интерфейса. Добавляем в данный файл следующий скрипт:

Сохраняем файл iptables Ctrl+O. Выходим из editor Ctrl+X. Устанавливаем необходимые права для созданного файла:
Перезагружаем компьютер и проверяем результат для таблицы filter с помощью команды:
Для обеспечения безопасности необходимо, чтобы конфигурация iptables применялась до запуска сетевых интерфейсов, сетевых служб и маршрутизации. Если данные условия не будут соблюдены — появляется окно уязвимости между загрузкой операционной системы и правил защиты межсетевого экрана. Для реализации такого варианта защиты можно использовать пакет iptables-persistent.
2. Автозагрузка правил iptables-persistent
По умолчанию данный пакет не установлен в операционной системе. Данный вариант реализации автозапуска конфигурации возможен в операционных системах Debian, Ubuntu. Для установки пакета требуется выполнить команду:
Этот пакет впервые стал доступен в Debian (Squeeze) и Ubuntu (Lucid). Используемые этим пакетом правила iptables хранятся в следующих директориях:
- /etc/iptables/rules.v4 для набора правил протокола IPv4;
- /etc/iptables/rules.v6 для набора правил протокола IPv6.
Но они должны быть сохранены в понятном утилите iptables-persistent виде.
Требования к формату данных файлах не задокументированны, что создает некоторые сложности для создания этих файлов вручную. Их можно создать с помощью dpkg-reconfigure:
Или можно использовать iptables-save и ip6tables-save:
Утилита netfilter-persistent тоже позволяет управлять автозагрузкой правил. Вот её синтаксис:
sudo netfilter-persistent
Где может принимать следующие значения:
- start — вызывает все плагины с параметром start, для загрузки правил в netfilter;
- stop — если настроена конфигурация сброса настроек Netfilter при остановке плагина, сбрасывает все настройки firewall на значения по умолчанию. Иначе просто выдает предупреждение;
- flush — плагины вызываются с параметром flush, что приводит к сбросу правил межсетевого экрана на значения по умолчанию;
- save — вызывает плагины с параметром save, позволяя сохранить значения правил брандмауэра в файлы на диске;
- reload — не задокументированный параметр, возникали случаи когда параметр start не срабатывал, помогал вызов этого параметра для загрузки правил из файла на диске;
Значит, чтобы сохранить правила мы можем вызвать следующую команду:
Для загрузки же сохраненных правил мы можем использовать команду:
Замечание После установки netfilter-persistent система при использовании iptables и формата хранения файлов, связанного с ним, начинает при работе выдавать предупреждение
Это связано с наличием новой утилиты настройки и редактирования правил Netfilter — nftables, для миграцию на эту утилиту старых правил iptables можно использовать автоматический транслятор правил iptables-translate. Но это уже тема для отдельной статьи.
Ключи утилиты iptables
| Ключ | Пример | Пояснения |
| -v, -verbose |
-list, -append, -insert, -delete, -replace |
Данный ключ используется для повышения информативности вывода и, как правило, используется совместно с командой -list. В случае использования с командой -list, в вывод этой команды включаются также имя интерфейса, счетчики пакетов и байт для каждого правила. Формат вывода счетчиков предполагает вывод кроме цифр числа еще и символьные множители K (x1000), M (x1,000,000) и G (x1,000,000,000). Для того чтобы заставить команду -list выводить полное число (без употребления множителей), требуется применять ключ -x, который описан ниже. Если ключ -v, -verbose используется с командами -append, -insert, -delete или -replace, то на вывод будет выдан подробный отчет о произведенной операции. |
| -x, -exact |
-list |
Для всех чисел в выходных данных выводятся их точные значения без округления и без применения множителей K, M, G. |
| -n, -numeric |
-list |
Iptables выводит IP-адреса и номера портов в числовом виде, предотвращая попытки преобразовать их в символические имена. |
| -line-numbers | -list | Ключ -line-numbers включает режим вывода номеров строк при отображении списка правил. |
| -c, -set-counters |
-insert, -append, -replace |
Этот ключ используется при создании нового правила для установки счетчиков пакетов и байт в заданное значение. Например, ключ -set-counters 20 4000 установит счетчик пакетов = 20, а счетчик байт = 4000. |
|
-modprobe |
Любая команда |
Ключ -modprobe определяет команду загрузки модуля ядра |
3 ответа
Это — иждивенец алгоритма на iptables реализации, которая позволяет направлять трафик, не разрушая исходный трафик.
я использую алгоритм подмены, когда я хочу создать виртуальный адаптер Wi-Fi и совместно использовать мой Wi-Fi.
Im, не говоря о совместном использовании соединения Ethernet через Ваш Wi-Fi, я говорю о совместном использовании соединения Wi-Fi через Ваш Wi-Fi через подмену его к виртуальному адаптеру. Это в действительности позволяет Вам совместно использовать свое соединение Wi-Fi через Wi-Fi.
Read это и прокручивают вниз для ПОДМЕНЫ: http://billauer.co.il/ipmasq-html.html
Read это для больше подробно: http://oreilly.com/openbook/linag2/book/ch11.html
Для прямого примера посещают эту страницу: http://pritambaral.com/2012/05/connectify-for-linux-wireless-hotspot/
у МЕНЯ НЕТ READ ПОСЛЕДНЯЯ ССЫЛКА!!!! , Но следующее точная выборка/пример.
мне действительно не нравится, как поисковые системы разбирают алгоритм, чтобы быть некоторым злым типом взлома.. Я использую его просто, так совместно используйте мой Интернет с моими телефонами на базе Android.
ЗАКЛЮЧИТЕЛЬНОЕ РЕДАКТИРОВАНИЕ: эта ссылка является самым лучшим http://gsp.com/cgi-bin/man.cgi?section=3&topic=libalias
ответ дан
14 December 2017 в 22:15
ПОДМЕНА является целью iptables, которая может использоваться вместо цели SNAT (источник NAT), когда внешний IP интерфейса inet не известен во время записи правила (когда сервер получает внешний IP динамично).
ответ дан
14 December 2017 в 22:15
Подмена IP также известна как Преобразование сетевых адресов (NAT) и Сетевое соединение, Совместно использующее некоторые другие популярные операционные системы. Это — в основном метод для разрешения компьютера, который не имеет общедоступного Интернета, широкий IP-адрес связывается с другими компьютерами в Интернете с помощью другого компьютера, находящегося промежуток это и Интернет.
, Как Вы знаете, IP-адрес используется в Интернете для идентификации машин. Учитывая пакет с IP-адресом, каждый маршрутизатор, который составляет Интернет, знает, куда отправить тот пакет для получения его его месту назначения. Теперь, существует также несколько диапазонов IP-адресов, которые были зарезервированы для личного пользования в Локальных сетях и других сетях, которые непосредственно не подключены к Интернету. Эти частные адреса, как гарантируют, не будут использоваться в общедоступном Интернете.
Это вызывает проблемы для машин, которые подключены к частным сетям, использование частные IP-адреса, потому что они не могут быть подключены непосредственно к Интернету. У них нет IP-адреса, которому позволяют использоваться в общедоступном Интернете. Подмена IP решает эту проблему, позволяя машину с частным IP-адресом общаться с Интернетом, одновременно изменяя пакеты машины для использования допустимого общедоступного IP-адреса вместо исходного частного IP-адреса. Пакеты, возвращающиеся из Интернета, изменяются назад для использования исходного IP-адреса прежде, чем достигнуть частной машины IP.
Примечание , что это не ограничено подменой/NAT интеллектуальной сети, может использоваться для маршрутизации трафика от одной сети до, другие позволенные говорят, что 10.0.0.0/24 и правило подмены 192.168.0.0/24
Iptables могут быть заменены правилом
SNAT =
И подмена и snat требуют , ip_forward включил на уровне ядра с эхом или постоянно путем редактирования нано файла настроек .
IP Вперед заставляет машину действовать как маршрутизатор и таким образом перенаправление/передачи пакетов от всего активного интерфейса логически целенаправленной сетью (local/net/other/etc) или следующим таблица маршрутизации
Обратите внимание, что включение ip_forward может представить важную угрозу безопасности, если ip_forward нельзя избежать, это должно контролироваться/защищаться дополнительными правилами iptables/route
ответ дан
18 April 2019 в 20:59
Заключение
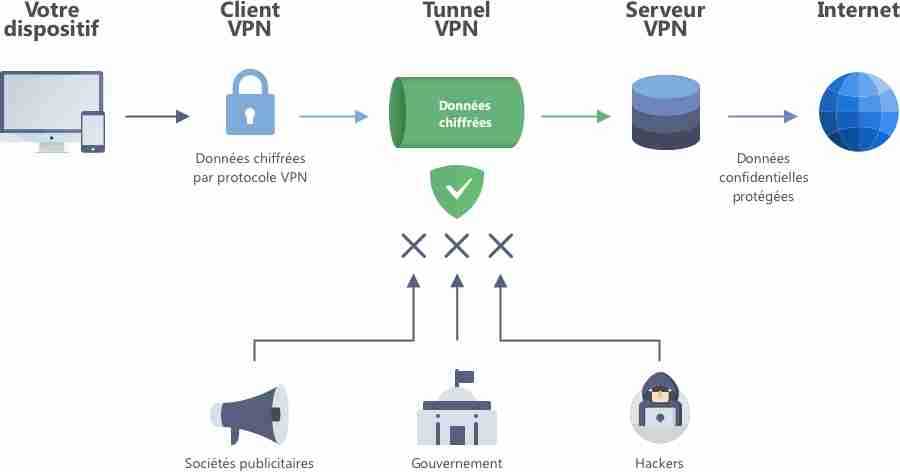
Итак, что у нас получилось? А вот что. Мы подняли зашифрованный, «белый» с точки зрения провайдера канал HTTPS. Внутри у него ходит наш OpenVPN. Клиент заворачивает туда то, что нам нужно, и не отправляет того, что не нужно. В принципе, можно написать еще пару правил iptables, в которых указано, кому можно ходить по адресам из заданного списка, а кому нет. Можно указать источники запросов для большей безопасности и для того, чтобы туда, не дай бог, не залез любознательный пользователь. Это реализуется с помощью второго списка IPSet, где придется вбить доверенные хосты, которые будут пользоваться доступом.
При желании всю эту не слишком навороченную архитектуру можно развернуть на Raspberry Pi с «Линуксом» и таскать его с собой в качестве маленького маршрутизатора. Он где угодно обеспечит вам надежное, безопасное и шифрованное соединение, до которого никто не доберется.





