
Как оценивают соблюдение ESG-принципов
Бизнес, который претендует на хорошую ESG-оценку, должен соответствовать стандартам развития в трех категориях: социальной, управленческой и экологической.
Экологические принципы определяют, насколько компания заботится об окружающей среде и как пытается сократить ущерб, который наносится экологии.
Например, бренд обуви Timberland сотрудничает с производителем шин Omni United и делает подошвы ботинок из переработанных шин.
Социальные принципы показывают отношение компании к персоналу, поставщикам, клиентам, партнерам и потребителям. Чтобы соответствовать стандартам, бизнес должен работать над качеством условий труда, следить за гендерным балансом или инвестировать в социальные проекты.
Например, американский бренд верхней одежды Patagonia не владеет фабриками, которые шьют его продукцию, поэтому не может влиять на размер зарплаты рабочих. Чтобы это исправить, в рамках программы «Честная торговля» бренд направляет часть средств с продажи продукции на фабрики, чтобы поднять зарплату сотрудников до уровня прожиточного минимума.
![]()
К 2019 году бренду Patagonia удалось поднять зарплату рабочим до прожиточного минимума на 11 из 31 фабрики
(Фото: Patagonia)
Управленческие принципы затрагивают качество управления компаниями: прозрачность отчетности, зарплаты менеджмента, здоровую обстановку в офисах, отношения с акционерами, антикоррупционные меры.
По словам Евгения Хилинского, директора управления анализа инструментов с фиксированной доходностью Газпромбанка, для устойчивого развития компания должна соблюдать баланс между всеми критериями. Но их значимость может различаться в зависимости от деятельности разных компаний. Например, для энергетики особую роль играют экологические критерии, для сектора услуг — социальные, а для финансов — управленческие.
Решение
Таблицы кучи в SQL Server
Базовый синтаксис кучи в SQL Server
CREATE TABLE TestData (TestId integer, TestName varchar(255), TestDate date,
TestType integer, TestData1 integer,
TestData2 varchar(100), TestData3 XML,
TestData4 varbinary(max), TestData4_FileType varchar(3));
ALTER TABLE TestData REBUILD;
DROP TABLE TestData;
Кластеризованный индекс в SQL Server
Основной синтаксис кластеризованного индекса в SQL Server
CREATE CLUSTERED INDEX IX_TestData_TestId ON dbo.TestData (TestId); ALTER INDEX IX_TestData_TestId ON TestData REBUILD WITH (ONLINE = ON); DROP INDEX IX_TestData_TestId on TestData WITH (ONLINE = ON);
Некластеризованный индекс в SQL Server
Основной синтаксис некластеризованного индекса в SQL Server
CREATE INDEX IX_TestData_TestDate ON dbo.TestData (TestDate); ALTER INDEX IX_TestData_TestDate ON TestData REBUILD WITH (ONLINE = ON); DROP INDEX IX_TestData_TestDate on TestData;
Индексы поколоночного хранения в SQL Server
Основной синтаксис поколоночных индексов в SQL Server
CREATE CLUSTERED COLUMNSTORE INDEX CIX_TestData_TestType ON TestData.TestType WITH (DATA_COMPRESSION = COLUMNSTORE); ALTER INDEX CIX_TestData_TestType ON TestData REORG IX_TestData_TestDate; DROP INDEX CIX_TestData_TestType;
XML индексы в SQL Server
Основной синтаксис индекса XML в SQL Server
-- первичный индекс CREATE PRIMARY XML INDEX PXML_TestData_TestData3 ON TestData (TestData3); -- вторичные индексы CREATE XML INDEX XMLPATH_TestData_TestData3 ON TestData (TestData3) USING XML INDEX PXML_TestData_TestData3 FOR PATH; CREATE XML INDEX XMLPROPERTY_TestData_TestData3 ON TestData (TestData3) USING XML INDEX PXML_TestData_TestData3 FOR PROPERTY; CREATE XML INDEX XMLVALUE_TestData_TestData3 ON TestData (TestData3) USING XML INDEX PXML_TestData_TestData3 FOR VALUE;
Полнотекстовые индексы в SQL Server
Основной синтаксис полнотекстового индекса в SQL Server
-- перед созданием индекса требуется создать каталог CREATE FULLTEXT CATALOG fulltextCatalog AS DEFAULT; CREATE FULLTEXT INDEX ON dbo.TestData (TestData4 TYPE COLUMN TestData4_FileType) KEY INDEX PK_TestData WITH STOPLIST = SYSTEM; ALTER FULLTEXT CATALOG fulltextCatalog REBUILD; DROP FULLTEXT INDEX ON dbo.TestData;
Вариации индексов в SQL Server
Индекс на базе функций SQL Server (вычисляемые столбцы)
ALTER TABLE TestData ADD TestDatePlus7Days AS DATEADD(DAY,7,TestDate) PERSISTED; CREATE NONCLUSTERED INDEX IX_TestData_TestDate_Plus7Days ON TestData (TestDatePlus7Days);
Покрывающий индекс SQL Server
CREATE INDEX IX_TestData_TestDate_TestType_AllData on TestData (TestDate,TestType) INCLUDE (TestData1,TestData2,TestData3,TestData4); SELECT TestData1,TestData2,TestData3,TestData4 FROM TestData WHERE TestDate > current_timestamp-1 and TestType=1;
Обслуживание индексов в SQL Server
SELECT t.name AS TableName,i.name AS IndexName,
ROUND(avg_fragmentation_in_percent,2) AS avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ips
INNER JOIN sys.tables t on t. = ips.
INNER JOIN sys.indexes i ON (ips.object_id = i.object_id) AND (ips.index_id = i.index_id)
ORDER BY avg_fragmentation_in_percent DESC;
| REBUILD | REORG |
|---|---|
| требуется достаточно пространства для создания нового индекса | работает на месте, поэтому никакого дополнительного пространства не требуется |
| если процесс прерывается, требуется начинать заново | может продолжиться с того места, на котором процесс прервался |
| может выполняться онлайн или офлайн | всегда выполняется онлайн |
| генерирует больше записей в журнал, чем reorg | записывает в журнал только блоки, которые были реорганизованы |
| статистика обновляется автоматически | обновление статистики должно быть выполнено вручную |
Что такое ESG и почему это актуально
Аббревиатуру ESG можно расшифровать как «экология, социальная политика и корпоративное управление». В широком смысле это устойчивое развитие коммерческой деятельности, которое строится на следующих принципах:
- ответственное отношение к окружающей среде (англ., E — environment);
- высокая социальная ответственность (англ., S — social);
- высокое качество корпоративного управления (англ., G — governance).
В современном виде ESG-принципы впервые сформулировал бывший генеральный секретарь ООН Кофи Аннан. Он предложил управленцам крупных мировых компаний включить эти принципы в свои стратегии, в первую очередь для борьбы с изменением климата.
Явление стало популярным только в последние пару лет, но уже закрепилось за рубежом. По словам вице-президента Тинькофф Нери Толлардо, в ближайшем будущем мировые фонды перестанут инвестировать в компании, которые игнорируют принципы устойчивого развития.
![]()
В начале 2000-х годов в США насчитывалось всего 20 компаний с ESG-рейтингом. Как видно по графику, к 2020 году их количество выросло почти до 800. Средний рейтинг ESG за 20 лет удвоился, что связывают с ростом объема, качества и доступности данных
(Фото: Factor Research)
В России принципы ESG менее распространены, чем за рубежом, но их уже постепенно внедряют в бизнес. Одной из актуальных тем на Петербургском международном экономическом форуме (ПМЭФ) в 2021-м стала защита окружающей среды.
Участники ПМЭФ-2021 обсуждали снижение выбросов углекислого газа при добыче и переработке топлива, а также развитие новых источников энергии. В рамках нацпроекта «Экология» поставлена задача к 2030 году отправлять на сортировку 100% отходов и вдвое сократить объем захоронения мусора.
![]()
Зеленая экономика
Власти готовят поправки в нацпроект «Экология». Как сильно он изменится?
Кроме того, треть крупнейших банков страны уже внедрила в кредитный процесс ESG-оценку компаний, еще 20% — планируют. Это значит, что банки будут тестировать каждого заемщика на соблюдение принципов устойчивого развития.
Какие компании входят в топ ESG-рейтингов
В мире есть множество примеров успешных корпораций, которые ориентируются на принципы ESG. По версии компании Corporate Knights, в 2021 году в первую пятерку входят:
- Французская машиностроительная компания Schneider Electric.
- Датская транснациональная энергетическая компания Ørsted A/S.
- Национальный банк Бразилии Banco do Brasil SA.
- Финская нефтегазовая компания Neste Oyj.
- Международная компания профессиональных услуг в области дизайна, архитектуры и консалтинга Stantec Inc.
Компания Corporate Knights ежегодно публикует рейтинг 100 самых устойчивых глобальных корпораций в мире. Рейтинг основан на публично раскрытых данных.
Многие российские компании тоже придерживаются ESG-принципов. Например, горнорудная компания «Полиметалл» активно развивает экологические и социальные проекты:
- Проводит мониторинг состояния флоры и фауны вблизи предприятий и разрабатывает программу по их сохранению.
- Создала некоммерческую ассоциацию «Женщины в горнодобывающей отрасли» для борьбы с гендерными стереотипами.
- Инвестирует в инфраструктуру, здравоохранение, образование и культуру города Амурска в Хабаровском крае.
- Планирует использовать только сухое складирование отходов без традиционного возведения дамб, чтобы снизить риск утечек и аварий.
В результате Полиметалл уже четвертый раз подряд становится лидером рэнкинга независимого кредитного рейтингового агентства RAEX-Europe. Рэнкинг — это часть проекта RAEX-Europe по сбору, систематизации и анализу ESG-данных компаний постсоветского пространства.
Зеленая экономика
Кто стал самой «зеленой» компанией России — ноябрьский рейтинг RAEX
RAEX-Europe обновляет ESG-рэнкинг каждый месяц: агентство переоценивает компании по мере выхода их годовых отчетов, а также включает новые, которые еще не получали оценку. Таким образом, рэнкинг охватил уже 135 российских компаний из 24 различных отраслей.
Первый в России крупный форум на тему ESG состоялся в Москве 14 октября 2021 года при поддержке медиахолдинга РБК. С итогами конгресса «ESG-(Р)Эволюция» вы можете ознакомиться на странице мероприятия.
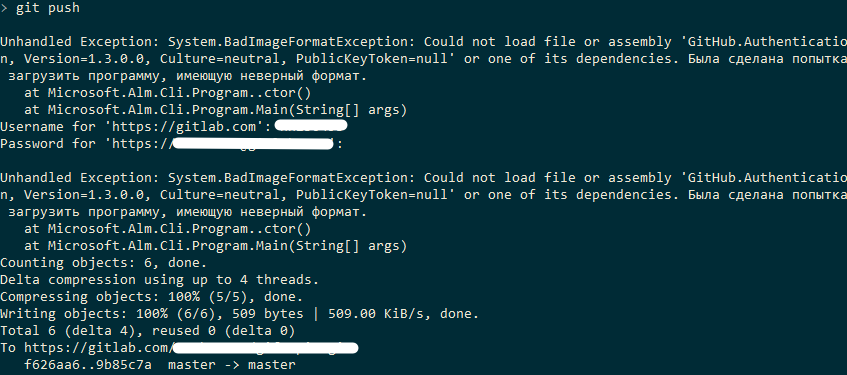
14 ответов
Лучший ответ
Если проблема связана с индексом в качестве промежуточной области для фиксации (т. Е. ), вы можете просто удалить индекс (сделать резервную копию, если хотите), а затем восстановить индекс до версия в последней фиксации:
В OSX / Linux / Windows (с Git bash):
В Windows (с CMD, а не с git bash):
(Команда выше аналогична )
В качестве альтернативы вы можете использовать водопровод более низкого уровня вместо .
Если проблема связана с индексом для packfile , вы можете восстановить его с помощью .
1399
Community
1 Июн 2021 в 17:30
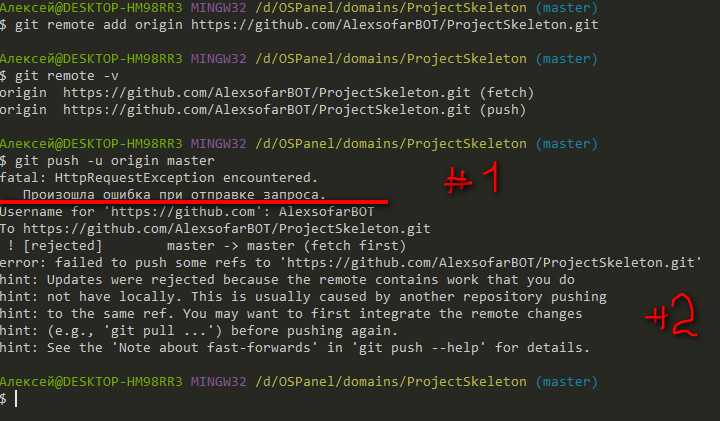
Возможно, вы случайно повредили файл .git / index с помощью sed в корне вашего проекта (возможно, рефакторинг?), Например:
Чтобы избежать этого в будущем, просто игнорируйте двоичные файлы с помощью grep / sed:
76
hobs
19 Мар 2011 в 07:57
У меня была эта проблема, и я пытаюсь исправить это:
НО это не сработало. Решение ? По какой-то причине у меня были другие папки .git в подкаталогах. Я удаляю эти папки .git (не основные) и снова . Как только они были удалены, все снова заработало.

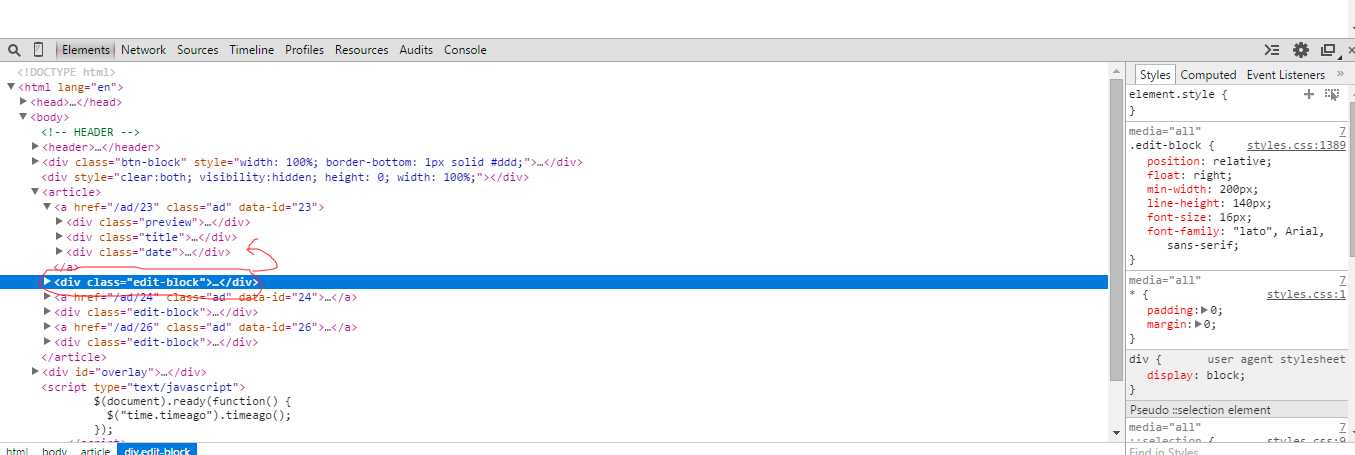

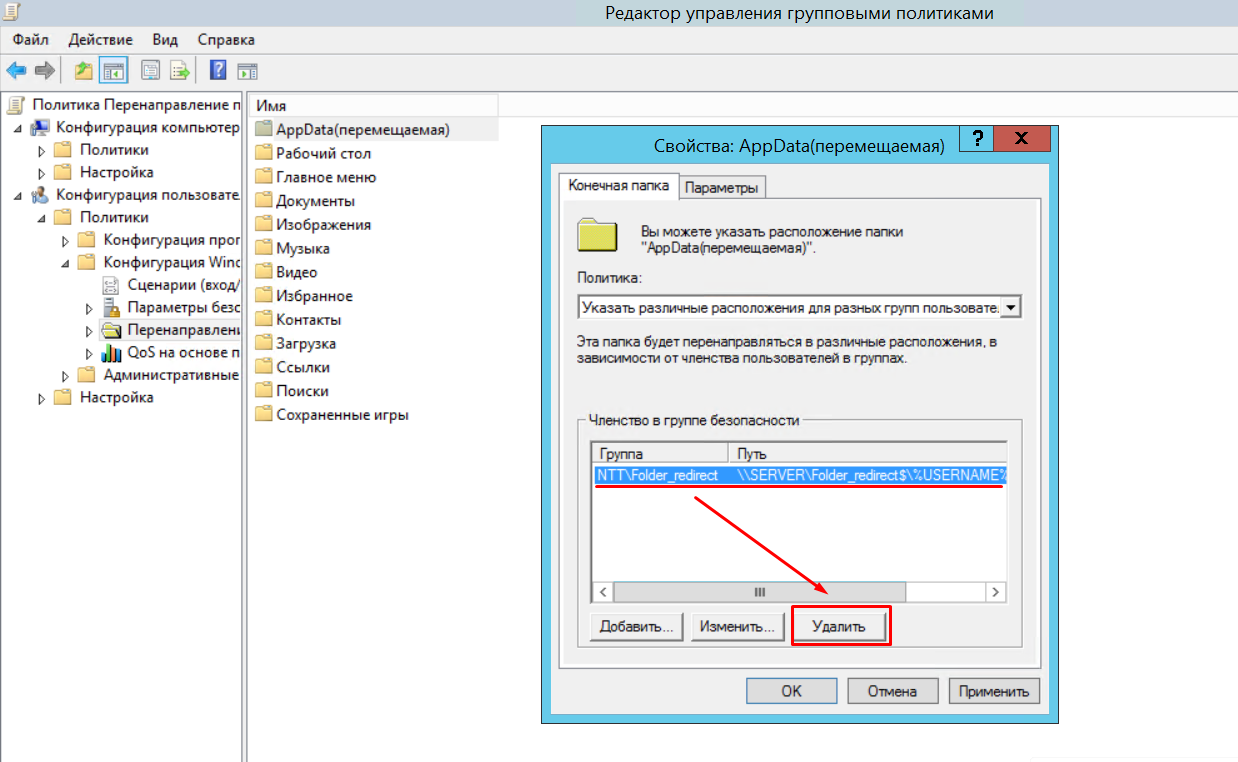
22
Cleiton Almeida
24 Июл 2015 в 13:23
Звучит как плохой клон. Вы можете попробовать следующее, чтобы получить (возможно?) Больше информации:
16
Gav
12 Июл 2009 в 11:36
Поскольку приведенные выше решения оставили у меня постоянные проблемы, я использовал это унылое решение:
- клонировать новую копию репо в другом месте
- скопируйте свежий каталог .git в (сломанный) репозиторий, содержащий изменения, которые я хотел зафиксировать.
Сделал свое дело. Кстати, я сделал в корне проекта, как догадался @hobs. Усвоил урок.
12
eskimwier
10 Фев 2017 в 22:18
Это сработало для меня. Хотя мне любопытно, почему я вообще начал получать ошибки. Когда я вчера вышел из системы, все было нормально. Авторизоваться сегодня утром не было.
7
DimaSan
27 Окт 2016 в 08:01
Примечание для пользователей подмодуля git — решения здесь не будут работать для вас как есть.
Допустим, у вас есть родительский репозиторий с именем , например, а ваш репозиторий подмодулей называется .
Если вы находитесь внутри и получаете ошибку, упомянутую в этом вопросе:
Файл НЕ будет находиться внутри папки . Фактически, даже не будет папкой — это будет текстовый документ с местонахождением реальных данных .git для этого репозитория. Скорее всего примерно так:
Итак, вместо вам нужно будет сделать следующее:
Или, в более общем плане,
6
jenming
12 Фев 2018 в 20:19
Эта проблема может возникнуть, если в одном из подкаталогов находится каталог . Чтобы исправить это, проверьте, есть ли там другие каталоги .git, удалите их и повторите попытку.
5
Eric Leschinski
16 Авг 2016 в 15:16
Ни один из существующих ответов не помог мне.
Я использовал рабочие деревья, поэтому папки .git нет.
Вам нужно будет вернуться к своему основному репо. Внутри этого удалите .git / worktrees / / index
Затем запустите git reset в соответствии с другими ответами.
1
Ash
29 Сен 2020 в 08:06
Репо может показаться поврежденным, если вы смешиваете разные версии .
Локальные репозитории, затронутые новыми версиями git, не имеют обратной совместимости со старыми версиями git. Новые репозитории git выглядят поврежденными для старых версий git (в моем случае git 2.28 сломал репозиторий для git 2.11).
Обновление старой версии git может решить проблему.
Kornel
16 Окт 2020 в 16:41
Я проделал простой трюк. Я клонирую репо в новую папку. Скопировал папку .git из новой папки в старую папку репо, заменив там .git.
-2
Astra Uvarova — Saturn’s star
1 Мар 2020 в 05:32
Дополнительная информация на https: //www.chris-shaw .com / blog / quick-fix-for-git-corrected-index.
-4
FelixSFD
18 Ноя 2017 в 16:19
Это смешно, но я только что перезагрузил свою машину (Mac), и проблема исчезла, как будто ее никогда не было. Ненавижу звучать как парень из службы поддержки …
-7
Herman Leus
28 Июн 2017 в 11:27
Вы также можете попробовать восстановить предыдущую версию файла (если вы используете ОС Windows)
-9
Shyamsundar
2 Май 2014 в 12:07
Что такое ESG-рейтинг и как он формируется
ESG-рейтинг формируют независимые исследовательские агентства — Bloomberg, S&P Dow Jones Indices, JUST Capital, MSCI, Refinitiv и другие. Они оценивают развитие компаний по трем критериям — E, S и G — и присваивают баллы по стобалльной шкале.




Например, конгломерат Kering (модные дома Gucci, Balenciaga, Saint Laurent) с 2019 года остается лидером рейтинга MSCI среди 28 компаний в сфере производства одежды и предметов роскоши. Всё благодаря его программе устойчивого развития, которая включала в том числе:
- отказ от использования токсичной пластмассы на 99,8%;
- использование «регенерированного» кашемира, который создают из отходов производства;
- запуск бесплатного онлайн-курса по сознательной моде.
MSCI делит компании на три категории: лидеры с рейтингом AA и AAA; компании со средними показателями — A, BBB, BB; и отстающие — B, CCC
(Фото: MSCI)
Единого подхода к формированию рейтинга нет. Все агентства анализируют открытые данные о компаниях, но считают баллы по-разному. Поэтому ESG-рейтинги разных агентств могут сильно различаться.
Например, MSCI присвоила розничной сети Boohoo высокий рейтинг, несмотря на расследования о том, что компания занижает зарплату сотрудникам и игнорирует локдаун во время пандемии. В то же время другие рейтинговые агентства поставили Boohoo более низкую оценку.
Составные индексы
Составные индексы используют более одной колонки в качестве ключевого значения. Создавайте составные индексы, когда две или более полей чаще всего используются для поиска в качестве ключа и если запрос ссылается только на все поля в составном индексе. Если запрос будет использовать не все поля, то индекс, скорей всего использоваться не будет.
Для примера, телефонный справочник является хорошим примером. Справочник организован по фамилии. Вместе с фамилией для поиска регулярно используется имя, потому что часто существует много записей для одной фамилии с разными именами и вполне логично создать индекс из фамилии и имени одновремнно.
Вы можете объединять до 16 колонок в составной индекс. Сумма длины всех колонок составного индекса должна быть менее 900 байт. При этом, все поля должны быть из одной таблицы.
Объявляйте сначала уникальные колонки. Первые колонки, описанные в операторе CREATE INDEX, имеют высший приоритет при сортировке. При поиске данных в таблице, ваш запрос должен будет обязательно ссылаться на первую колонку индекса, иначе индекс точно использоваться не будет.
Индекс на поля «Фамилия» и «Имя» это не то же самое, что индекс на поля «Фамилия» и «Имя». Эти индексы имеют разный порядок полей. Например, для первого случая сортировка будет следующей:
Фамилия Имя ----------------------------------------- Иванов Андрей Иванов Сергей Петров Андрей Петров Василий
Те же самые поля, но с индексом «Имя» и «Фамилия» будут отсортированы следующим образом:
Фамилия Имя ----------------------------------------- Иванов Андрей Петров Андрей Петров Василий Иванов Сергей
В данном случае главным является имя, и именно оно сортируется первым.
Составной индекс позволяет повысить производительность запросов и уменьшить количество индексов на таблицу. Производительность повышается за счет того, что сервер для поиска необходимых данных сканирует только один индекс.
Следующий пример создает не кластерный составной индекс для таблицы телефонного справочника
Обратите внимание, что поле «Фамилия» описывается первой, потому что она чаще всего является основой при выборке данных из таблицы:
CREATE UNIQUE NONCLUSTERED INDEX I_NCL_Фамилия_Имя ON (Фамилия, Имя)
Так как индекс уникальный, в таблицу нельзя будет записать двух людей с фамилией и именем Иванов Андрей.
Сервер SQL предлагает опции, которые могут ускорить создание индекса, а также увеличить производительность индексов.
Эффективность индексов
Хотя индексы и позволяют повысить поиск, но с каждым индексом связаны дополнительные накладные расходы. Каждый раз когда в коллекцию добавляется документ, его также нужно добавить во все индексы связанные с этой коллекцией. Получается если над коллекцией построено 10 индексов, то при добавлении документа, нужно изменить 10 разных структур данных. И это относится к любой операции записи, добавления, удаления, обновления полей документа, которые проиндексированы. Для приложений ориентированных на чтение, затраты на индексы почти всегда оправданы. Следите за тем, чтобы индексы которые есть использовались, а если не используются то удаляйте их.
Чтобы удалить индекс пользуйтесь командой:
db.collection.dropIndex("catIdx");
Где это название индекса. Чтобы посмотреть все индексы которые относятся к коллекции, нужно воспользоваться командой:
db.collection.getIndexes();// В ответе мы получим следующее
Также мы можем удалить все индексы сразу:
Сопоставление в индексах
Вы можете думать об этом как о способе сортировать и сравнивать строки относительно языковых особенностей. Представьте, что мы добавили два документа в коллекцию:
db.users.insertMany()
И в какой то параллельной вселенной это пишется и так и так. И чтобы выполнить поиск по данным поля максимально просто в MongoDB есть который позволяет по специфики языка искать в строках относительно некоторого количества символов, к примеру создадим следующий запрос:
db.cities.find( { name: 'San Jose' }).collation({ locale: 'en_US', strength: 1 })
будет игнорировать диакритические знаки. Мы там же можешь отсортировать документ по чувствительности к регистру.
db.words.find({}) .sort({ v: 1 }) .collation({ locale: 'en_US', caseLevel: true })
Поэкспериментируйте со своими данными сами и посмотрите как они меняются.
db.files.find() .sort({ name: 1 }) .collation({ locale: 'en_US', numericOrdering: true })
Также в порядке возрастания строк которые имею цифры в значении
Например, коллекция имеет индекс поля строки с локализацией сортировки .
db.myColl.createIndex( { name: 1 }, { collation: { locale: "fr" } })
Следующая операция запроса, которая указывает ту же строку, что и индекс, может использовать индекс:
db.myColl.find( { category: "cafe" } ).collation( { locale: "fr" } )
Однако следующая операция запроса, которая по умолчанию использует «простой» двоичное сравнение, не может использовать индекс:
db.myColl.find( { category: "cafe" } )
Для составного индекса, где ключи префикса индекса не являются строками, массивами и вложенными документами, операция, которая задает другое сравнение, все равно может использовать индекс для поддержки сопоставлений с ключами префикса индекса.
Например, коллекция имеет составной индекс для числовых полей и строковое поле ; индекс создается с локализацией сортировки для сравнения строк:
db.myColl.createIndex( { score: 1, price: 1, category: 1 }, { collation: { locale: "fr" } } )
Следующие операции, которые используют ‘простое’ двоичное сравнение для строк, могут использовать индекс:
db.myColl.find( { score: 5 } ).sort( { price: 1 } )db.myColl.find( { score: 5, price: { $gt: NumberDecimal( "10" ) } } ).sort( { price: 1 } )
Следующая операция которая использует ‘простое’ бинарное сравнение для строк на индексируемом поле . Мы можем использовать индекс, чтобы выполнить только запрос:
db.myColl.find( { score: 5, category: "cafe" } )
Пошаговое руководство
Чтобы продемонстрировать процесс и, надеюсь, понять, что мы делаем, я собираюсь вручную пройти по каждой части.
Выполнение команды 1 возвратит результаты, аналогичные приведенным ниже. В этом примере для краткости используются только 16 файлов. всегда используйте 32 для Windows 2008 и более поздних операционных систем и 9 для Windows 2003 R2


Пример данных, возвращаемых PowerShell
| Название | Длина |
| File5.zip | 10286089216 |
| archive.zip | 6029853696 |
| BACKUP.zip | 5751522304 |
| file9.zip | 5472683008 |
| MENTOS.zip | 5241586688 |
| File7.zip | 4321264640 |
| file2.zip | 4176765952 |
| frd2.zip | 4176765952 |
| BACKUP.zip | 4078994432 |
| File44.zip | 4058424320 |
| file11.zip | 3858056192 |
| Backup2.zip | 3815138304 |
| BACKUP3.zip | 3815138304 |
| Current.zip | 3576931328 |
| Backup8.zip | 3307488256 |
| File999.zip | 3274982400 |
Как использовать эти данные для определения минимального размера промежуточной области:
- Name = имя файла.
- Длина = байт
- Один гигабайт = 1073741824 байт
Сначала необходимо суммировать общее число байтов. Далее разделите итог на 1073741824. я предлагаю использовать Excel или электронную таблицу для выполнения математических действий.
Пример
В примере выше общее число байтов = 75241684992. Чтобы получить минимальную квоту промежуточной области, необходимо разделить 75241684992 на 1073741824.
На основе этих данных я настроил промежуточную область на 71 ГБ, если округлить до ближайшего целого числа.
Реальный сценарий:
Хотя пошаговое руководство является интересным, это, скорее всего, не самое лучшее в использовании время для самостоятельного выполнения математических операций. Чтобы автоматизировать процесс, используйте команду 3 из приведенных выше примеров. Результаты будут выглядеть следующим образом:
Используя пример команды 3 без каких-либо дополнительных усилий, за исключением округления до ближайшего целого числа, я могу определить, что для д:\докс. требуется квота промежуточной области в 6 ГБ.
Индексы с реверсированным ключом
Индексы с реверсированным ключом – это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым, меняется только порядок байтов. Самое большое преимущество применения индексов с реверсивным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Отмена последней фиксации
Чтобы отменить последнюю фиксацию без потери изменений, внесенных вами в локальные файлы и индекс, вызовите с параметром за которым следует :
— это переменная, указывающая на предыдущую фиксацию. Приведенная выше команда перемещает текущую ветвь назад на одну фиксацию, эффективно отменяя последнюю фиксацию. Если вы запустите команду , вы увидите, что измененные файлы перечислены как незафиксированные изменения.
Чтобы обновить указатель для сброса индекса, запустите с или без параметра:
Измененные файлы сохраняются, но, в отличие от предыдущего примера, теперь изменения не ставятся для фиксации.
Если вы не хотите сохранять изменения, внесенные в файлы, вызовите команду с параметром :
Перед выполнением аппаратного сброса убедитесь, что вам больше не нужны изменения.
Добавление файла в Git
По правилу Android Studio пометит файлы в вашем каталоге в соответствии с их статусом в git.
- Когда имя отображается синим цветом, это означает, что файл изменен.
- Когда имя отображается зеленым цветом, это означает, что файл является новым и был добавлен в набор файлов, отслеживаемых git.
- Когда имя отображается красным, это означает, что файл не отслеживается.
- Когда имя отображается белым / серым цветом, это означает, что файл не изменен.
![]()
Если вы видите, что некоторые имена файлов в вашем репозитории отображаются красным цветом, вы можете: , и они будут отслеживаться git, и вы сможете увидеть их, когда попытаетесь зафиксировать.





