Типы данных SQL
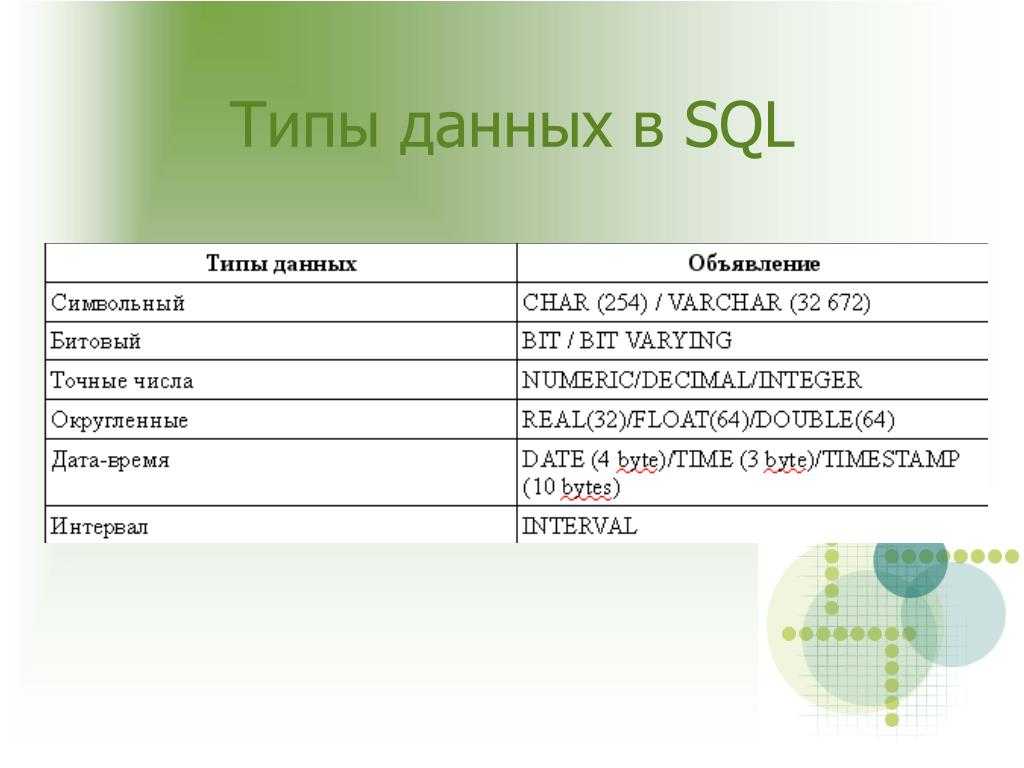
Типы данных SQL разделяются на три группы:
— строковые;
— с плавающей точкой (дробные числа);
— целые числа, дата и время.
-
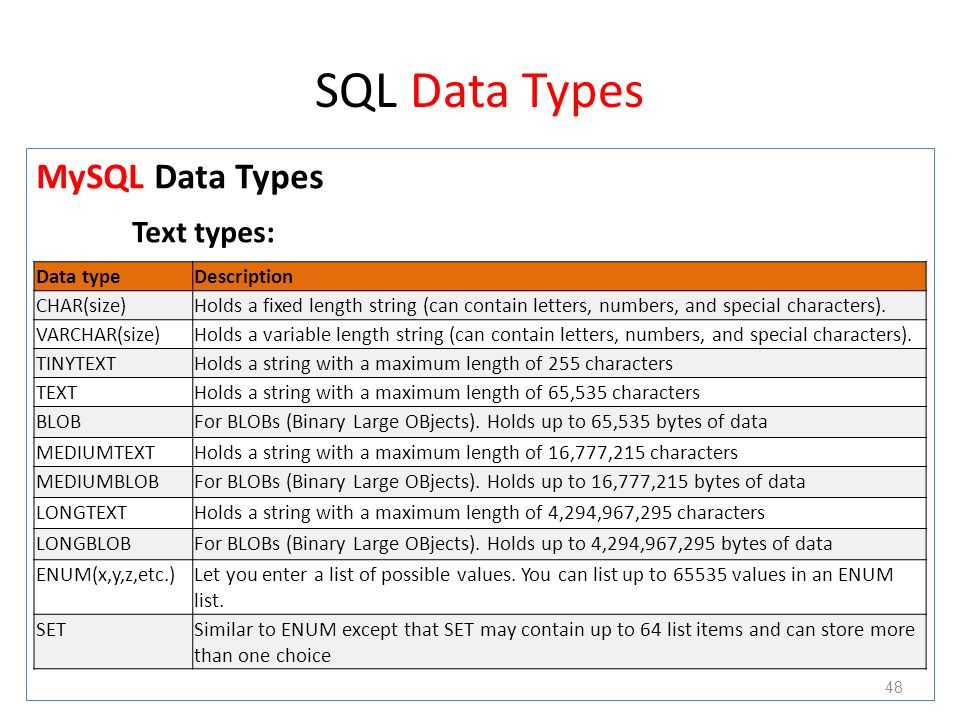
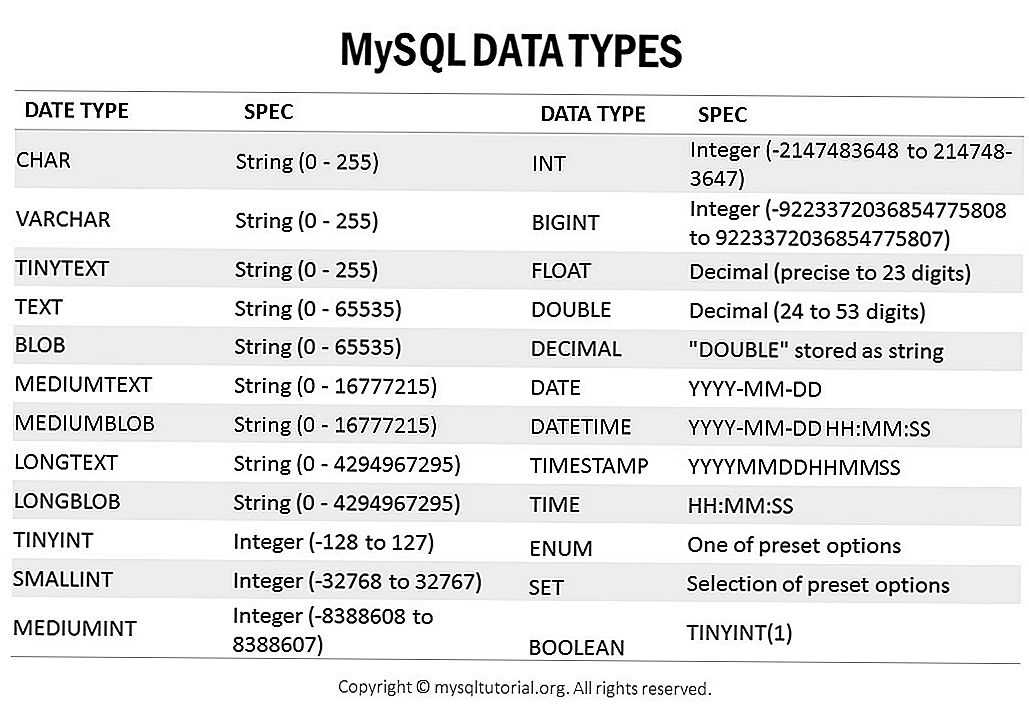
Типы данных SQL строковые
Типы данных SQL Описание Строки фиксированной длиной (могут содержать буквы, цифры и специальные символы). Фиксированный размер указан в скобках. Можно записать до 255 символов Может хранить не более 255 символов. Может хранить не более 255 символов. Может хранить не более 65 535 символов. Может хранить не более 65 535 символов. Может хранить не более 16 777 215 символов. Может хранить не более 16 777 215 символов. Может хранить не более 4 294 967 295 символов. Может хранить не более 4 294 967 295 символов. Позволяет вводить список допустимых значений. Можно ввести до 65535 значений в SQL Тип данных ENUM список. Если при вставке значения не будет присутствовать в списке ENUM, то мы получим пустое значение.
Ввести возможные значения можно в таком формате:SQL Тип данных SET напоминает ENUM за исключением того, что SET может содержать до 64 значений. -
Типы данных SQL с плавающей точкой (дробные числа) и целые числа
Типы данных SQL Описание Может хранить числа от -128 до 127 Диапазон от -32 768 до 32 767 Диапазон от -8 388 608 до 8 388 607 Диапазон от -2 147 483 648 до 2 147 483 647 Диапазон от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 Число с плавающей точкой небольшой точности. Число с плавающей точкой двойной точности. Дробное число, хранящееся в виде строки. -
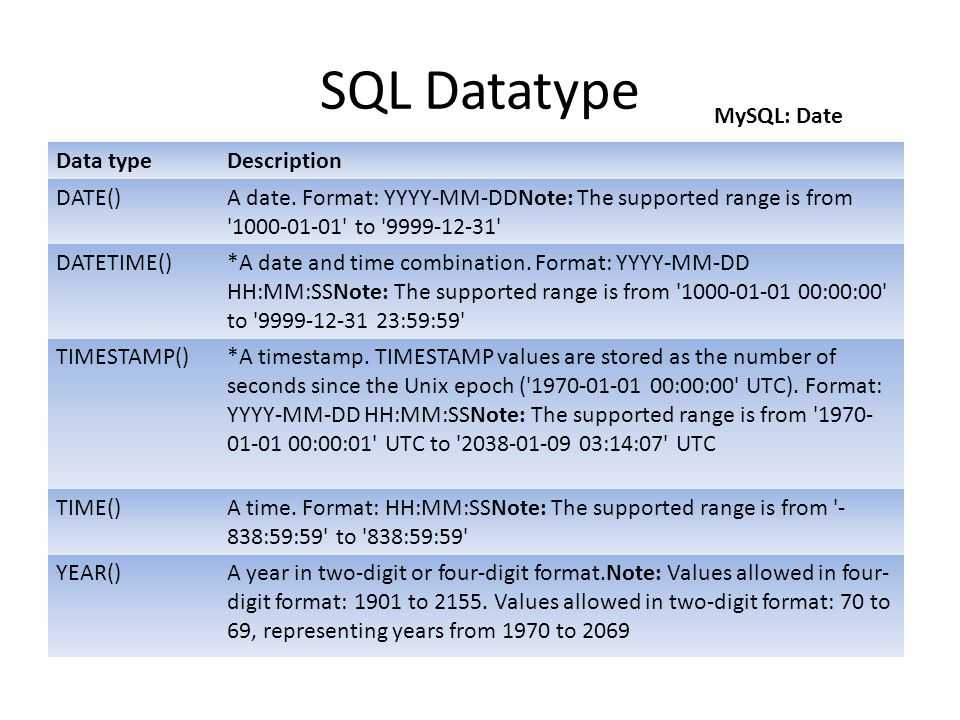
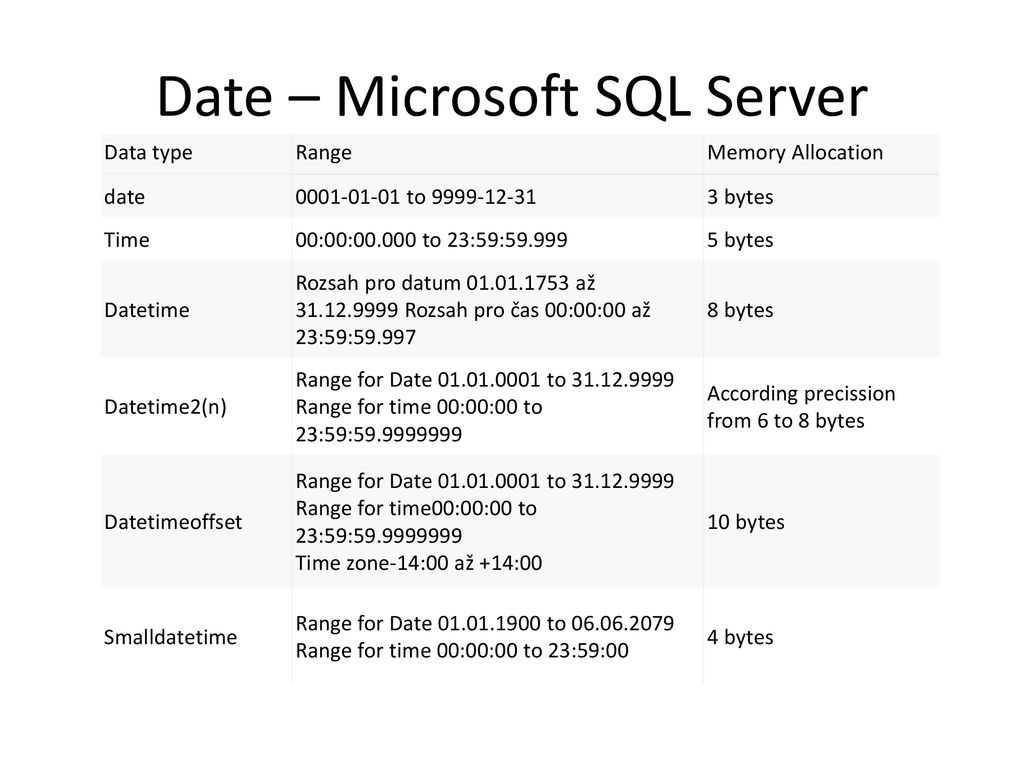
Типы данных SQL — Дата и время
Типы данных SQL Описание Дата в формате ГГГГ-ММ-ДД Дата и время в формате Дата и время в формате timestamp. Однако при получении значения поля оно отображается не в формате timestamp, а в виде ГГГГ-ММ-ДД ЧЧ:ММ:СС Время в формате Год в двух значной или в четырехзначном формате.
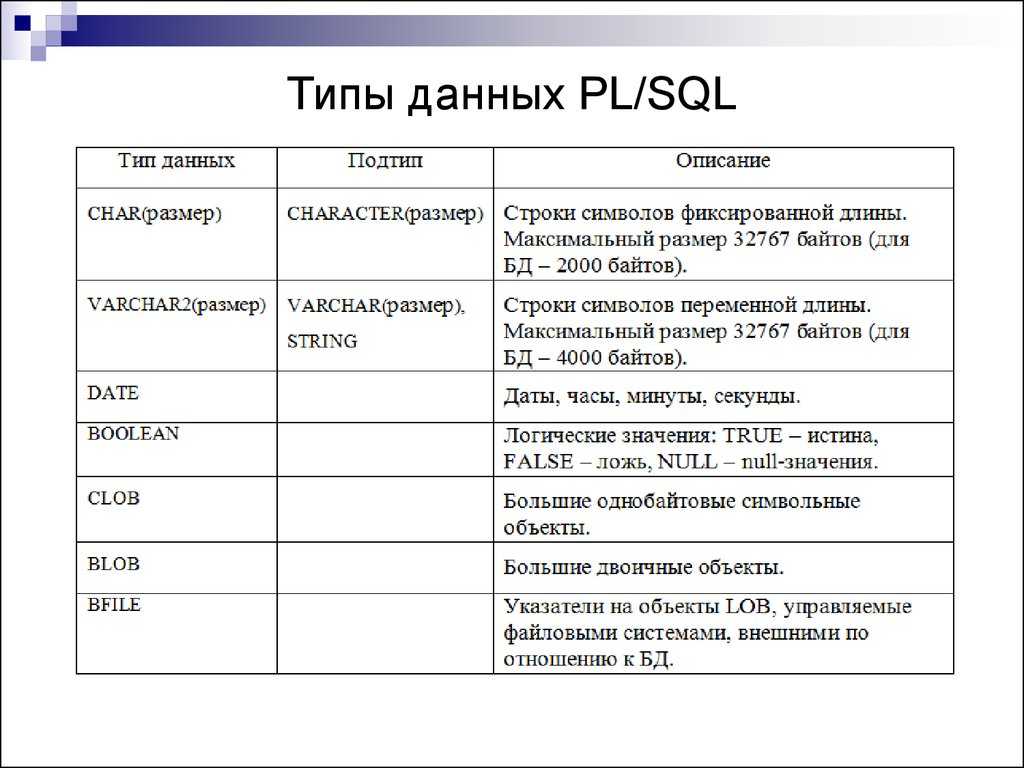
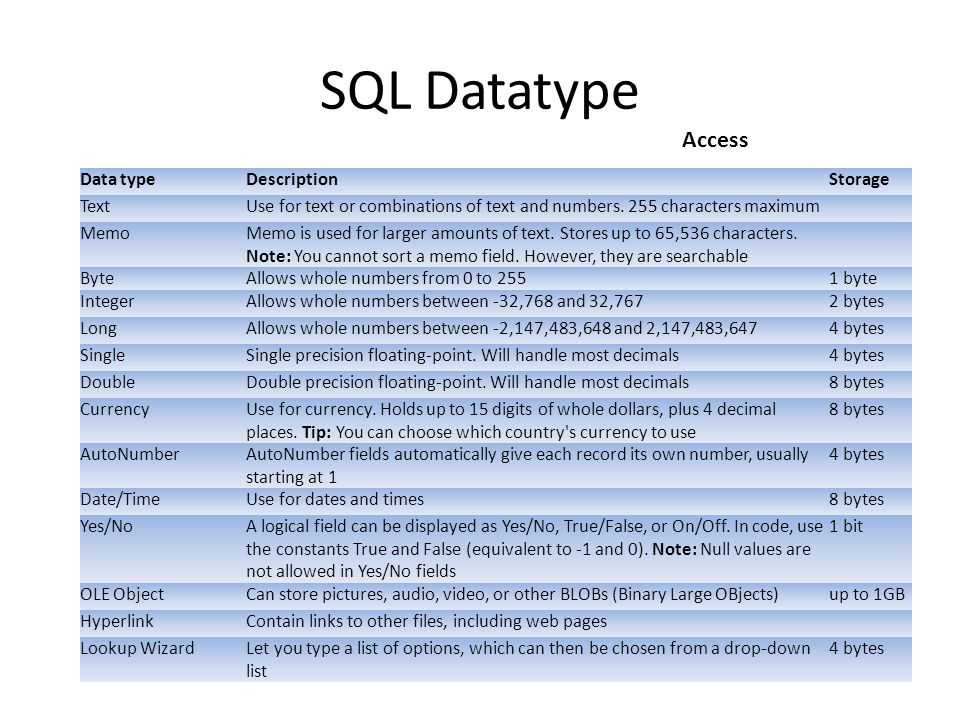
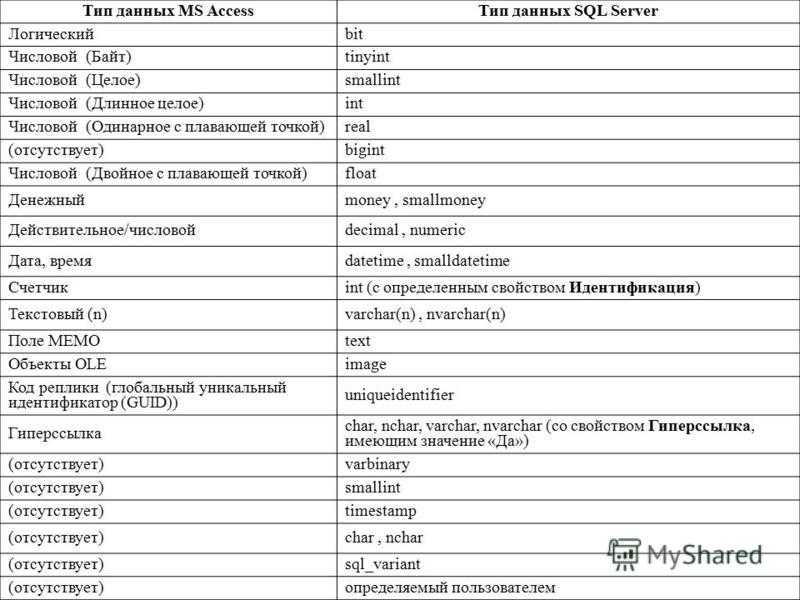
Типы данных Access
Типы данных Access разделяются на следующие группы:
- Текстовый – максимально 255 байтов.
- Мемо — до 64000 байтов.
-
Числовой — 1,2,4 или 8 байтов.Для числового типа размер поля м.б. следующим:
- байт — целые числа от -0 до 255, занимает при хранении 1 байт
- целое — целые числа от -32768 до 32767, занимает 2 байта
- длинное целое — целые числа от -2147483648 до 2147483647, занимает 4 байта
- с плавающей точкой — числа с точностью до 6 знаков от –3,4*1038 до 3,4*1038, занимает 4 байта
- с плавающей точкой — числа с точностью от –1,797*10308 до 1,797*10308, занимает 8 байт
- Дата-время — 8 байтов
- Денежный — 8 байтов, данные о денежных суммах, хранящиеся с 4 знаками после запятой.
- Счетчик — уникальное длинное целое, генерируемое Access при создании каждой новой записи — 4 байта.
- Логический — логические данные 1бит.
- Поле объекта OLE — до 1 гигабайта, картинки, диаграммы и другие объекты OLE из приложений Windows. Объекты OLE могут быть связанными или внедренными.
- Гиперссылки — поле, в котором хранятся гиперссылки. Гиперссылка может быть либо типа UNC (стандартный формат для указания пути с включением сетевого сервера файлов), либо URL(адрес объекта, документа, страницы или объекта другого типа в Интернете или Интранете. Адрес URL определяет протокол для доступа и конечный адрес).
- Мастер подстановок — поле, позволяющее выбрать значение из другой таблицы Accesss или из списка значений, используя поле со списком. Чаще всего используется для ключевых полей. Имеет тот же размер, что и первичный ключ, являющийся также и полем подстановок, обычно 4 байта. (Первичный ключ – одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице Accesss. Не допускает неопределенных .Null. значений, всегда должен иметь уникальный индекс. Служит для связывания таблицы с вторичными ключами других таблиц).
Распространенные ошибки при выборе типа данных в T-SQL
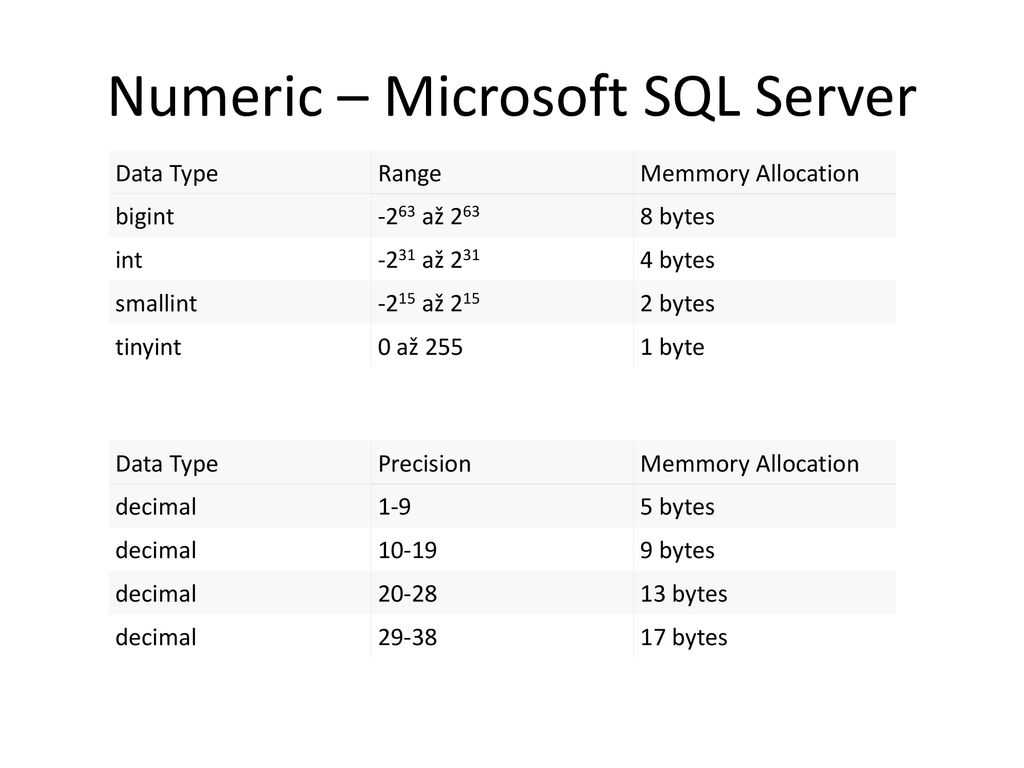
В начале статьи я говорил, что выбор неоптимального типа данных может сказаться на размере базы данных, так вот одной из самых распространенных ошибок при проектировании таблицы является выбор для столбца, который должен содержать тип данных Boolean (т.е. 0 или 1), тип SMALLINT или INT. Как Вы уже поняли, такого типа данных как Boolean в T-SQL нет, поэтому для этих целей разработчики используют похожие (подходящие) типы данных и в большинстве случаев их выбор неправильный. Если Вам нужно хранить только значения 0 или 1 (т.е. как Boolean), то в T-SQL существует специальный тип данных BIT, SQL сервер выделяет для хранения всего 1 байт, но в отличие от типа TINYINT, под который также отводится 1 байт, SQL сервер оптимизирует хранение бит столбцов. Если таблица содержит не больше 8 бит столбцов, столбцы хранятся как 1 байт, если таких столбцов от 9 до 16, то 2 байта и т.д.
Для сравнения давайте посмотрим на разницу.
Таблица 1
--В строке 16 байт
CREATE TABLE TestTable1 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled INT NOT NULL, --4 байта
IsTest INT NOT NULL, --4 байта
)
Таблица 2 (с использованием BIT столбцов)
--В строке 9 байт
CREATE TABLE TestTable2 (
Id INT NOT NULL, --4 байта
IdProperty INT NOT NULL, --4 байта
IsEnabled BIT NOT NULL, --1 байта
IsTest BIT NOT NULL, --0 байта
)
Сравнение
| Количество строк | Размер в мегабайтах (MB) | ||
| Таблица 1 | Таблица 2 (с использованием BIT столбцов) | Разница | |
| 1 000 | 0,02 | 0,01 | 0,01 |
| 10 000 | 0,15 | 0,09 | 0,07 |
| 100 000 | 1,53 | 0,86 | 0,67 |
| 1 000 000 | 15,26 | 8,58 | 6,68 |
| 10 000 000 | 152,59 | 85,83 | 66,76 |
| 100 000 000 | 1525,88 | 858,31 | 667,57 |
Как видите, после добавления нескольких миллионов строк разница будет ощутимая, и это на простой, маленькой, тестовой таблице.
Про типы данных Microsoft SQL Server у меня все, надеюсь, материал был Вам полезен! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу SQL код» – это самоучитель по языку SQL, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
Нравится8Не нравится1
Примеры
A. Отображение значения по умолчанию n при использовании в объявлении переменной
В приведенном ниже примере показано, что значение по умолчанию n равно 1 для типов данных и , если они используются в объявлении переменной.
В. Преобразование данных для отображения
В следующем примере два столбца преобразуются в символьные типы, после чего к ним применяется стиль, применяющий к отображаемым данным конкретный формат. Тип money преобразуется в символьные данные. К нему применяется стиль 1, отображающий значения с запятыми между каждой группой из трех цифр, отсчитывая влево от десятичной точи, и каждой группой из двух цифр, отсчитывая вправо от десятичной точки. Тип datetime преобразуется в символьные данные. К нему применяется стиль 3, отображающий данные в формате дд/мм/гг. В предложении WHERE тип money приводится к символьному типу для выполнения операции сравнения строк.
Результирующий набор:
Г. Преобразование данных uniqueidentifier
В следующем примере значение преобразуется в тип данных .
Следующий пример показывает усечение данных, когда значение является слишком длинным для преобразования в заданный тип данных. Так как тип данных uniqueidentifier ограничен 36 символами, все символы, выходящие за пределы этой длины, будут усечены.
Результирующий набор:
Ограничения столбца «вне строки»
Ниже перечислены некоторые ограничения и пояснения, касающиеся использования столбцов «вне строки» в таблице, оптимизированной для памяти.
- Если имеется индекс columnstore для таблицы, оптимизированной для памяти, то все столбцы должны умещаться «в строке».
- Но все ключевые столбцы индекса должны хранится «в строке». Если ключевой столбец индекса не помещается «в строке», добавление индекса завершается ошибкой.
- Пояснения по изменению таблицы, оптимизированной для памяти, со столбцами «вне строки».
- Для больших объектов (LOB) ограничение размера соответствует аналогичному ограничению для таблиц на диске (лимит 2 ГБ на значения LOB).
- Для обеспечения оптимальной производительности рекомендуется проследить, чтобы большинство столбцов умещалось в 8060 байт.
Некоторые из этих особенностей подробно рассмотрены в записи блога о новых возможностях выполняющейся в памяти OLTP в SQL Server 2016, появившихся после выпуска CTP3.
Тип данных CHAR
Тип данных определяет строку фиксированной длины. При объявлении такой строки необходимо задать ее максимальную длину в диапазоне от 1 до 32 767 байт. Длина может задаваться как в байтах, так и в символах. Например, следующие два объявления создают строки длиной 100 байт и 100 символов соответственно:
feature_name CHAR(100 BYTE); feature_name CHAR(100 CHAR);
Реальный размер 100-символьной строки в байтах зависит от текущего набора символов базы данных. Если используется набор символов с переменной длиной кодировки, PL/SQL выделяет для строки столько места, сколько необходимо для представления заданного количества символов с максимальным количеством байтов. Например, в наборе UTF-8, где символы имеют длину от 1 до 4 байт, PL/SQL при создании строки для хранения 100 символов зарезервирует 300 байт (3 байта ? 100 символов).
Мы уже знаем, что при отсутствии спецификатора или результат будет зависеть от параметра . При компиляции программы эта настройка сохраняется вместе с ней и может использоваться повторно или заменяться при последующей перекомпиляции. С настройкой по умолчанию для следующего объявления будет создана строка длиной 100 байт:



feature_name CHAR(100);
Если длина строки не указана, PL/SQL объявит строку длиной 1 байт. Предположим, переменная объявляется так:
feature_name CHAR;
Как только этой переменной присваивается строка длиной более одного символа, PL/SQL инициирует универсальное исключение . Но при этом не указывается, где именно возникла проблема. Если эта ошибка была получена при объявлении новых переменных или констант, проверьте свои объявления на небрежное использование . Чтобы избежать проблем и облегчить работу программистов, которые придут вам на смену, всегда указывайте длину строки типа . Несколько примеров:
yes_or_no CHAR (1) DEFAULT 'Y'; line_of_text CHAR (80 CHAR); ----- Всегда все 80 символов! whole_paragraph CHAR (10000 BYTE); -- Подумайте обо всех этих пробелах...
Поскольку строка типа имеет фиксированную длину, PL/SQL при необходимости дополняет справа присвоенное значение пробелами, чтобы фактическая длина соответствовала максимальной, указанной в объявлении.
До выхода версии 12c максимальная длина типа данных в SQL была равна 2000; в 12c она была увеличена до максимума PL/SQL: 32 767 байт. Однако следует учитывать, что SQL поддерживает этот максимум только в том случае, если параметру инициализации задано значение .
Преобразование символьных данных
При преобразовании символьного выражения в символьный тип данных другой длины значения, слишком длинные для нового типа данных, усекаются. Тип uniqueidentifier считается символьным типом, используемым при преобразовании из символьного выражения, поэтому на него распространяются правила усечения при преобразовании в символьный тип. См подраздел «Примеры» ниже.
Если символьное выражение преобразуется в символьное выражение другого типа данных или размера, например из char(5) в varchar(5) или из char(20) в char(15) , то преобразованному значению присваиваются параметры сортировки входного значения. Если несимвольное выражение преобразуется в символьный тип данных, то преобразованному значению присваиваются параметры сортировки, заданные по умолчанию в текущей базе данных. В любом случае необходимые параметры сортировки можно присвоить с помощью предложения COLLATE.
Примечание
Преобразование кодовых страниц поддерживается для типов данных char и varchar, однако поддержка типа данных text не предусмотрена. Как и в ранних версиях SQL Server, о потере данных во время преобразования кодовых страниц не сообщается.
Символьные выражения, которые преобразуются в приближенный тип данных numeric, могут содержать необязательную экспоненциальную нотацию (символ e нижнего регистра или E верхнего регистра, за которым следуют необязательный знак плюс (+) или минус (–) и число).
Символьные выражения, преобразуемые в точный тип данных numeric, должны состоять из цифр, десятичного разделителя и необязательного знака плюс (+) или минус (–). Начальные пробелы не учитываются. Разделители в виде запятой запрещены (например, десятичный разделитель в числе 123 456,00).
Кроме того, символьные выражения, преобразуемые в типы данных money или smallmoney, могут содержать необязательный десятичный разделитель и обозначение валюты. Разрешаются разделители в виде запятой, например 123 456,00 руб.
Когда пустая строка преобразовывается в тип int, ее значение становится равным . Когда пустая строка преобразовывается в дату, ее значением становится значение даты по умолчанию, то есть .
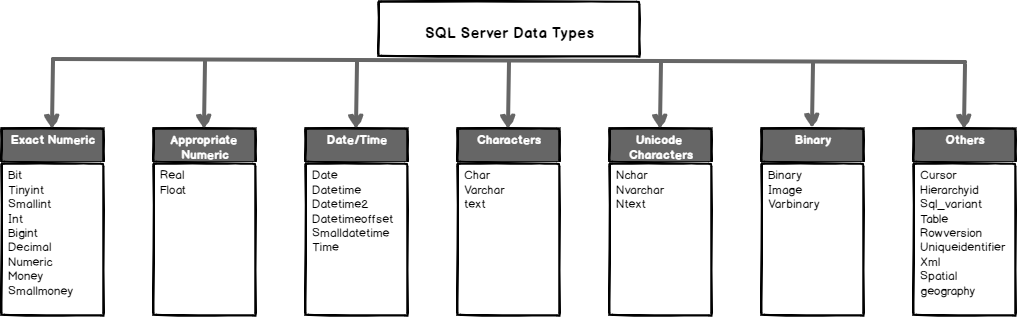
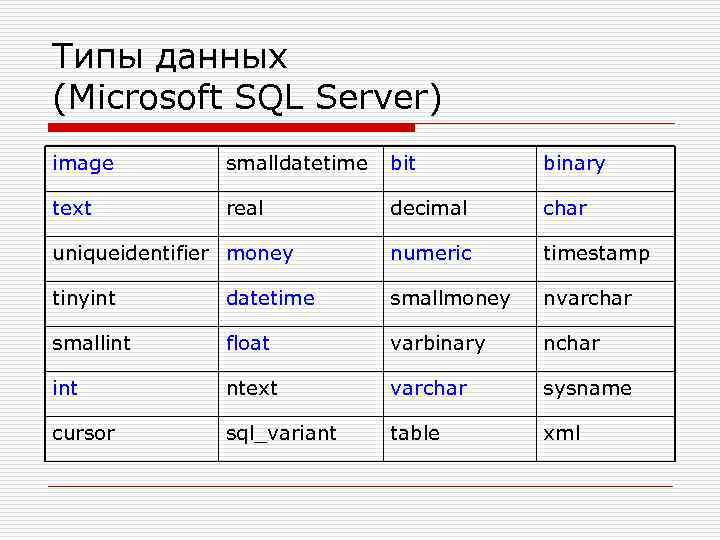
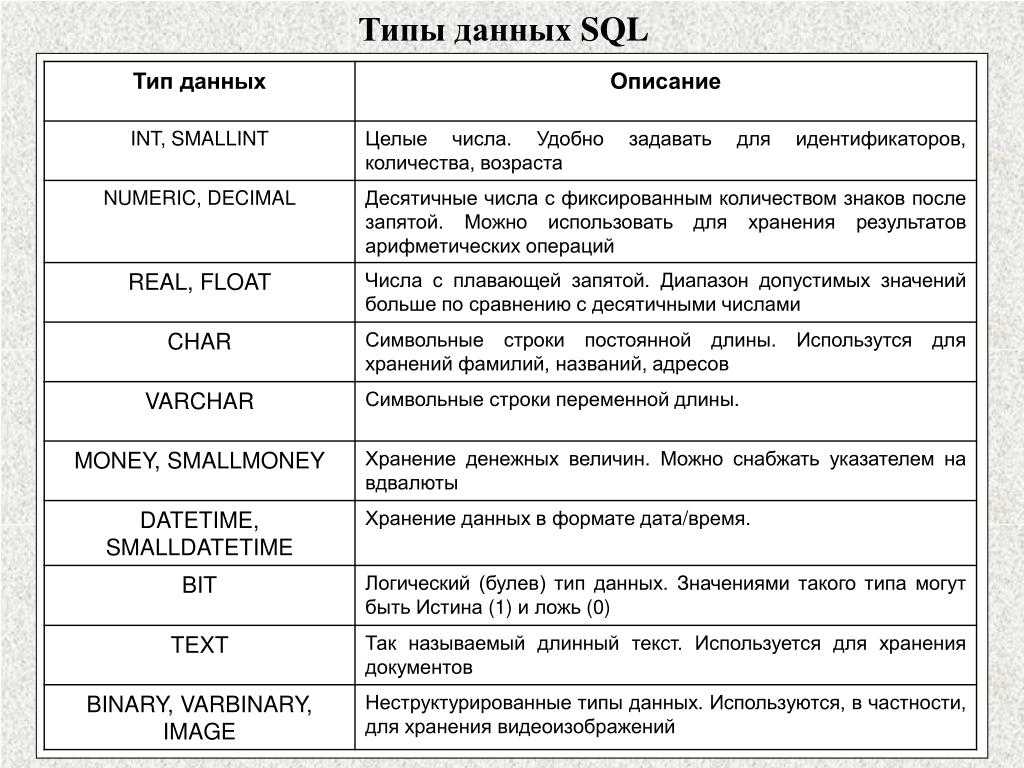
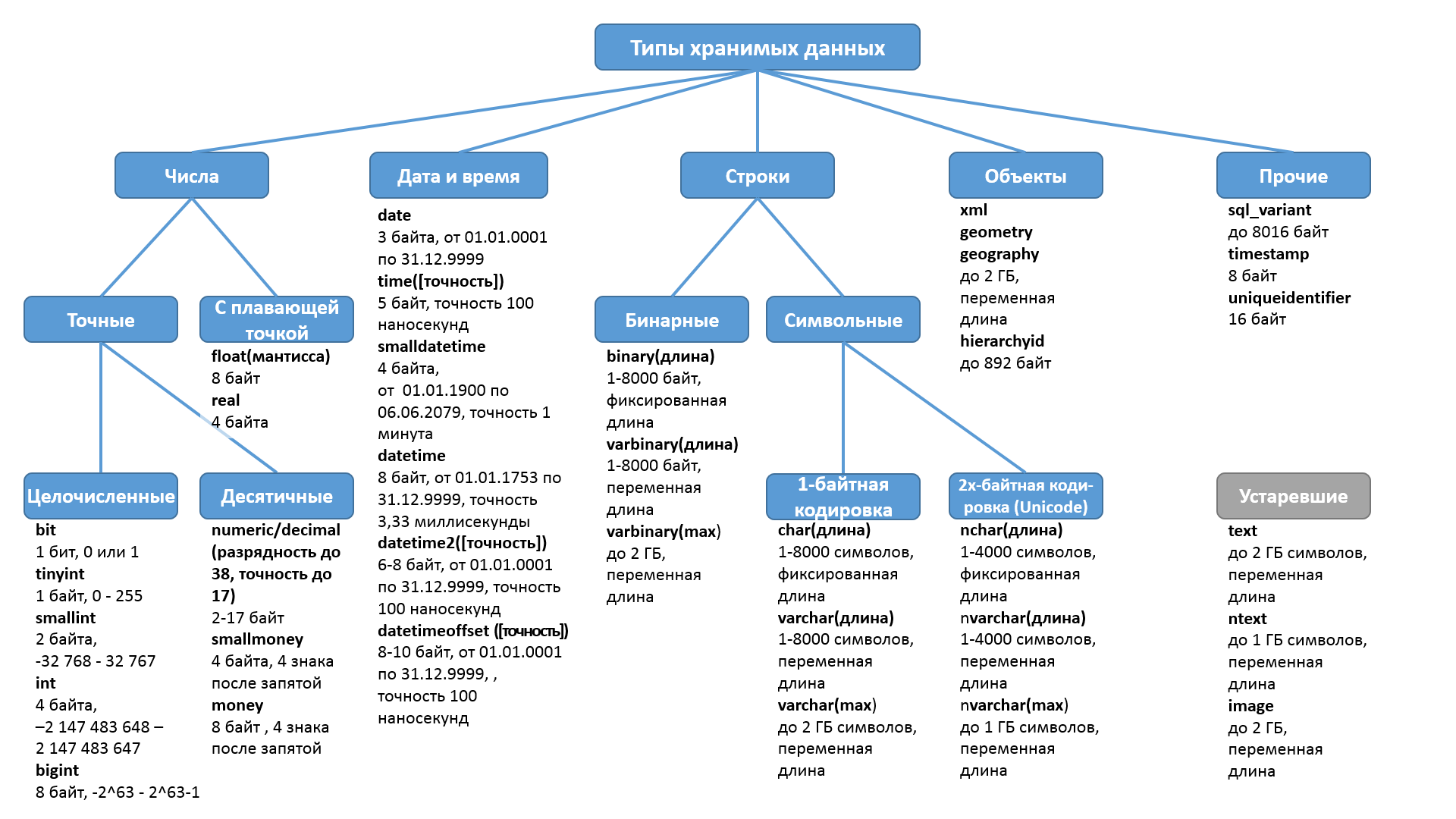
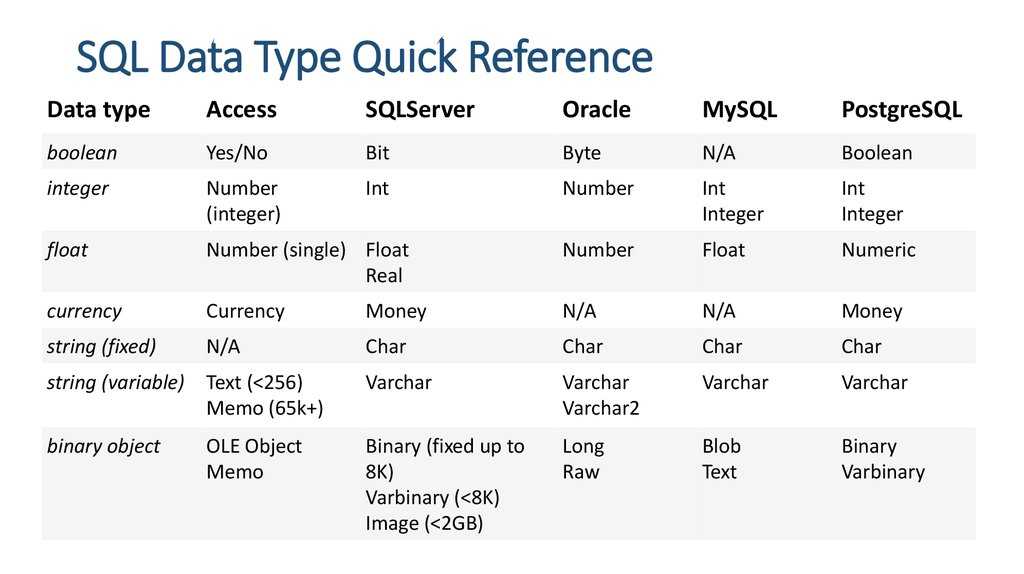
Что такое тип данных в SQL Server?
Тип данных – это характеристика, определяющая, какого рода данные будут храниться в объекте. Например: целые числа, числовые данные с плавающей запятой, данные денежного типа, дата, время, текст, двоичные данные и так далее. У каждого столбца, выражения, переменной или параметра есть определенный тип данных. В Microsoft SQL Server существует набор системных типов данных, который и определяет все доступные по умолчанию типы данных для использования. У разработчиков также существует возможность создавать псевдонимы типов данных основанные на системных типах, а также собственные пользовательские типы данных, о том, как реализовать псевдоним типа данных, мы разговаривали в материале – «Создание псевдонима типа данных в Microsoft SQL Server на T-SQL».
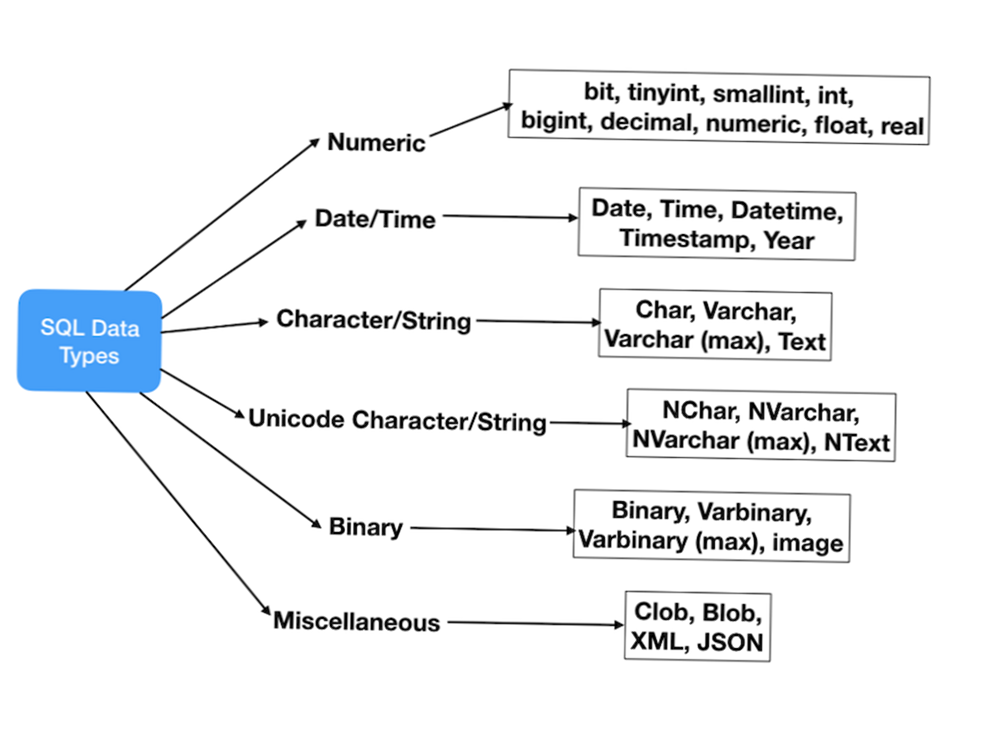
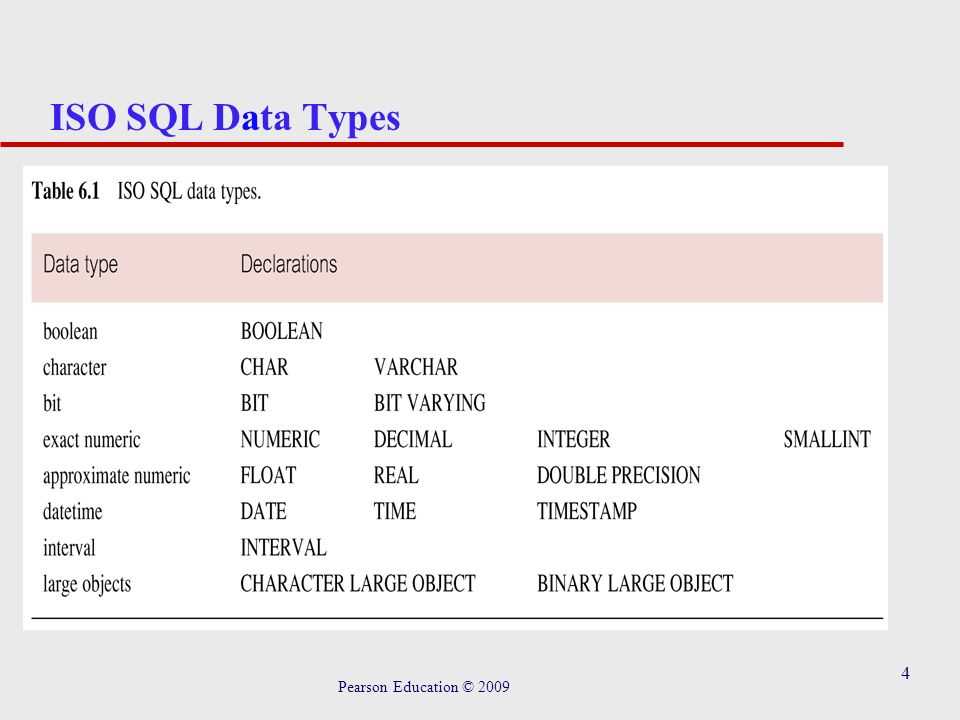
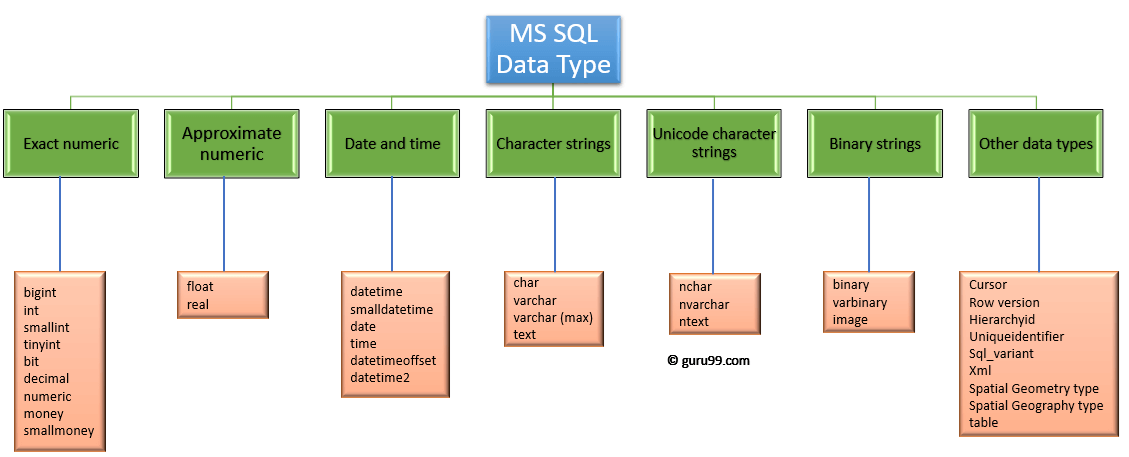
Типы данных в MS SQL Server делятся на следующие категории:
- Точные числа;
- Приблизительные числа;
- Символьные строки;
- Символьные строки в Юникоде;
- Дата и время;
- Двоичные данные;
- Прочие типы данных.
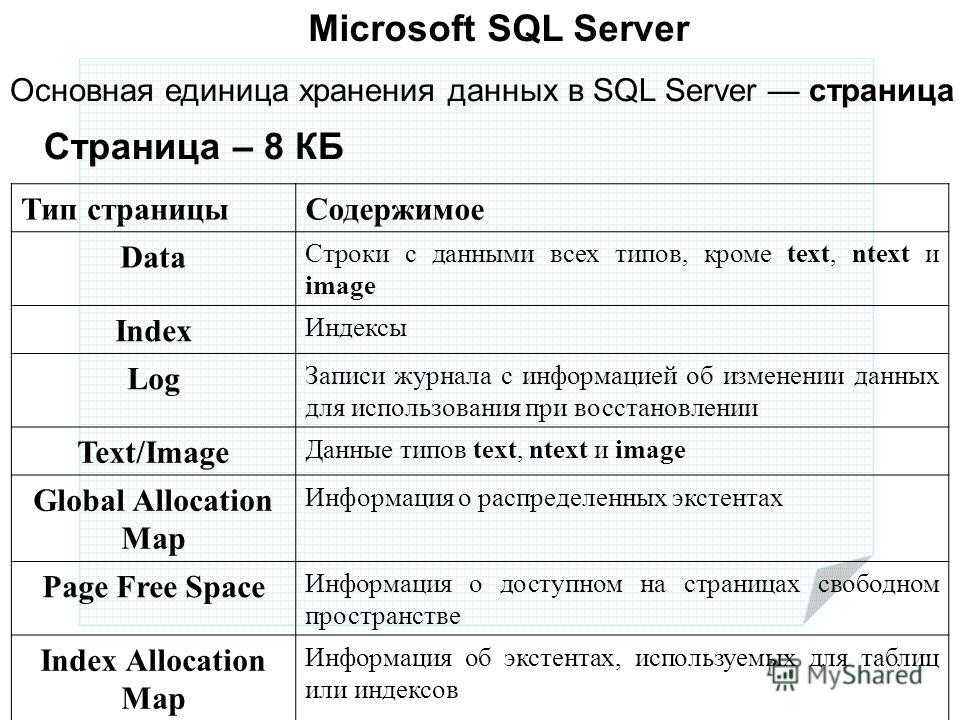
Пример. Вычисление размера строки и таблицы
Для хэш-индекса фактическое число контейнеров округляется в сторону увеличения до ближайшей степени числа 2. Например, если заданное число равно 100 000, то фактическое число контейнеров для индекса составляет 131 072.
Рассмотрим таблицу Orders со следующим определением:
Обратите внимание, что эта таблица содержит один хэш-индекс и некластеризованный индекс (первичный ключ). Кроме того, она содержит три столбца фиксированной длины и один столбец переменной длины, при этом один из столбцов допускает значения NULL ()
Допустим, таблица содержит 8379 строк, а средняя длина значений в столбце составляет 78 символов.
Чтобы определить размер таблицы, сначала необходимо определить размер индексов. Для обоих индексов указан показатель bucket_count, равный 10 000. Эта величина округляется в большую сторону до ближайшей степени числа 2: 16384. Поэтому общий размер индексов для таблицы Orders составляет:
Остается найти размер данных таблицы, который равен
(Пример таблицы содержит 8379 строк.) Теперь у нас есть:
Теперь давайте рассчитаем .
-
Столбцы поверхностных типов:
-
Заполнение для столбцов поверхностных типов равно 0, поскольку общий размер столбцов поверхностного типа является четным числом.
-
Массив смещений для столбцов глубоких типов:
-
Массив значений NULL = 1
-
Заполнение массива значений NULL = 1, так как размер массива значений NULL является нечетным числом, а в таблице есть столбцы глубоких типов.
-
Заполнение
-
8 — наибольшее требования выравнивания.
-
Размер на данный момент равен 16 + 0 + 4 + 1 + 1 = 22.
-
Ближайшее число, кратное 8, — это 24.
-
В итоге заполнение составляет 24 – 22 = 2 байта.
-
-
В таблице нет столбцов глубоких типов фиксированной длины (столбцов глубоких типов фиксированной длины: 0).
-
Фактический размер столбца глубокого типа составляет 2 * 78 = 156. Единственный столбец глубокого типа имеет тип .
-

Для завершения вычисления:
Таким образом, общий размер, занимаемый таблицей в памяти, составляет около 2 мегабайт. Это значение не учитывает потенциальные издержки при выделении памяти, а также управление версиями строк, необходимое для доступа транзакций к этой таблице.
Фактический размер памяти, выделяемый для данной таблицы и используемый ею и ее индексами, можно получить при помощи следующего запроса:
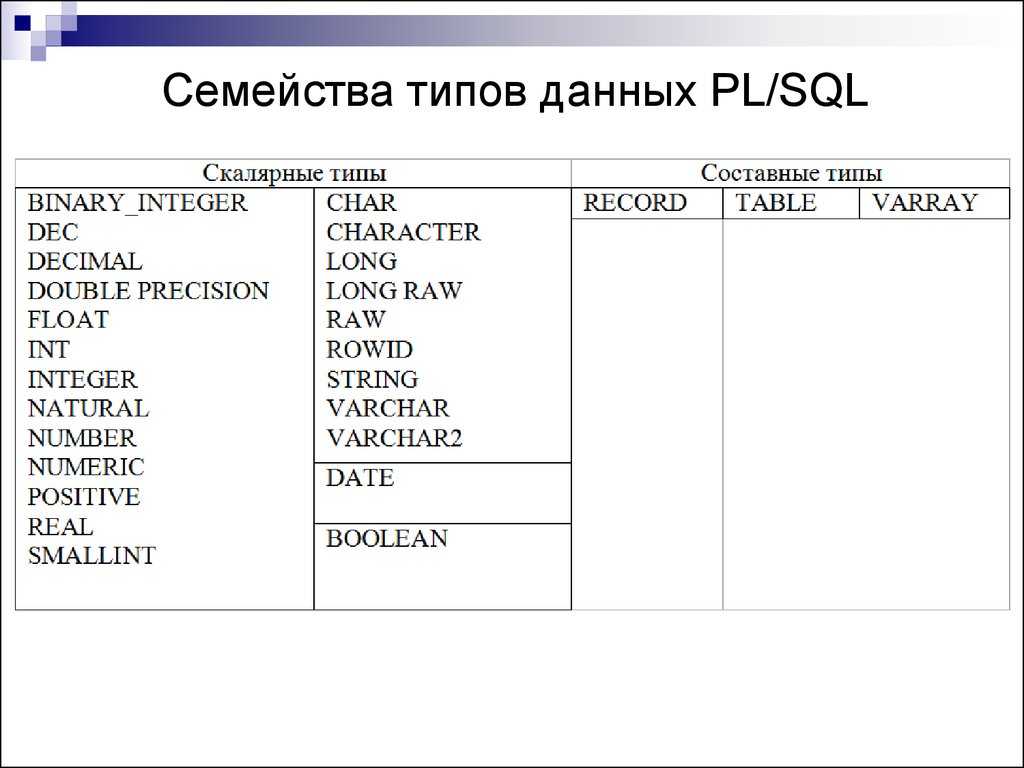
Строковые подтипы
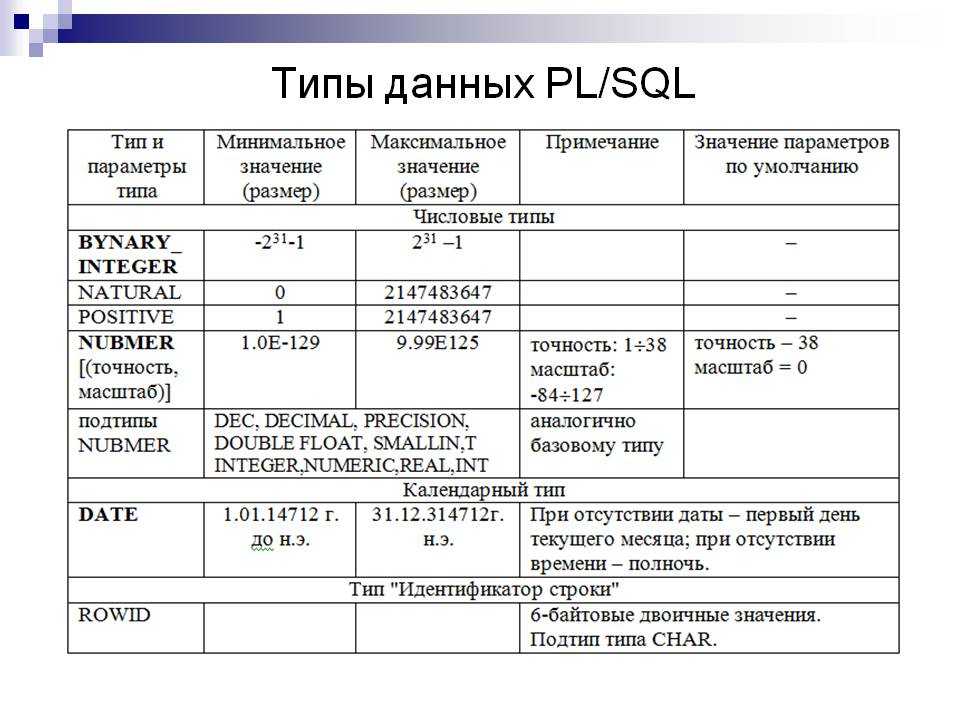
PL/SQL поддерживает некоторые строковые подтипы (табл. 2), которые тоже могут использоваться для объявления символьных строк. Многие из этих подтипов определены только для обеспечения совместимости со стандартом ANSI SQL. Вряд ли они вам когда-нибудь понадобятся, но знать о них все же нужно.
Каждый из перечисленных в таблице подтипов эквивалентен одному из базовых типов данных PL/SQL, указанных в правом столбце. Например:
feature_name VARCHAR2(100); feature_name CHARACTER VARYING(100); feature_name CHAR VARYING(100); feature_name STRING(100);
Подтип заслуживает особого внимания. Уже на протяжении нескольких лет корпорация Oracle собирается изменить определение подтипа данных (в результате чего он перестанет быть эквивалентным ) и предупреждает, что пользоваться им не следует. Я согласен с этой рекомендацией: если существует опасность, что Oracle (или комитет ANSI) изменит поведение , неразумно полагаться на его поведение. Используйте вместо него .
| Подтип | Эквивалентный тип |
| CHAR VARYING | VARCHAR2 |
| CHARACTER | CHAR |
| CHARACTER VARYING | VARCHAR2 |
| NATIONAL CHAR | NCHAR |
| NATIONAL CHAR VARYING | NVARCHAR2 |
| NATIONAL CHARACTER | NCHAR |
| NATIONAL CHARACTER VARYING | NVARCHAR2 |
| NCHAR VARYING | NVARCHAR2 |
| STRING | VARCHAR2 |
| VARCHAR | VARCHAR2 |
Remarks
Часто ошибочно считают, что в типах данных NCHAR(n) и NVARCHAR(n) число n указывает на количество символов. Однако на самом деле число n в NCHAR(n) и NVARCHAR(n) — это длина строки в парах байтов (0–4000). n никогда не определяет количество хранимых символов. То же самое верно и в отношении типов CHAR(n) и VARCHAR(n).
Заблуждение возникает из-за того, что при использовании символов, определенных в диапазоне Юникода 0–65 535, на каждую пару байтов приходится один хранимый символ. Однако в старших диапазонах Юникода (65 536–1 114 111) один символ может занимать две пары байтов. Например, в столбце, определенном как NCHAR(10), Компонент Database Engine может хранить 10 символов, занимающих одну пару байтов (диапазон Юникода 0–65 535), но меньше 10 символов, занимающих две пары байтов (диапазон Юникода 65 536–1 114 111). Дополнительные сведения о хранении символов Юникода и их диапазонах см. в разделе .
Если значение n в определении данных или в инструкции объявления переменной не указано, то длина по умолчанию равна 1. Когда n не задано функцией CAST, длина по умолчанию равняется 30.
Если вы используете nchar или nvarchar, мы рекомендуем:
- использовать nchar, если размеры записей данных в столбцах одинаковые;
- использовать nvarchar, если размеры записей данных в столбцах существенно отличаются;
- использовать nvarchar(max), если размеры записей данных в столбцах существенно отличаются и длина строки может превышать 4000 пар байтов.
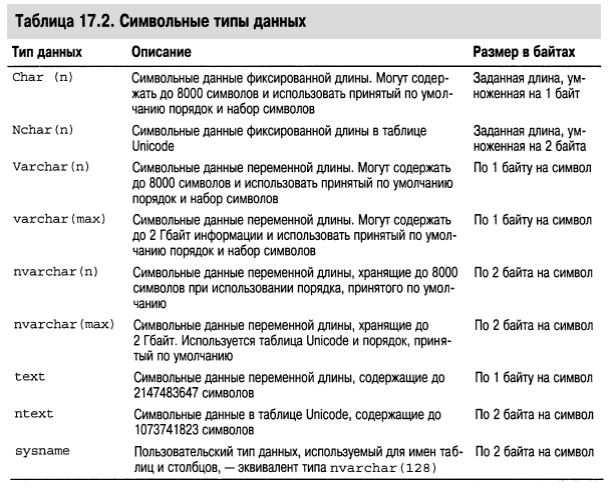
Тип sysname — это предоставляемый системой определяемый пользователем тип данных, который функционально эквивалентен типу nvarchar(128) за исключением того, что он не допускает значения NULL. Тип sysname используется для ссылки на имена объектов баз данных.
Объектам, в которых используются типы данных nchar и nvarchar, назначаются параметры сортировки базы данных по умолчанию, если только иные параметры сортировки не назначены с помощью предложения COLLATE.
Для типов данных nchar и nvarchar параметр SET ANSI_PADDING всегда принимает значение ON. Параметр SET ANSI_PADDING OFF не применяется к типам данных nchar или nvarchar.
Префикс N в строковых константах с символами Юникода указывает на входные данные в кодировке UCS-2 или UTF-16 (в зависимости от того, используются ли параметры сортировки с поддержкой дополнительных символов). Без префикса N строка преобразуется в стандартную кодовую страницу базы данных, и определенные символы могут не распознаваться. Начиная с SQL Server 2019 (15.x) при использовании параметров сортировки с поддержкой UTF-8 стандартная кодовая страница может хранить символы Юникода в кодировке UTF-8.
Примечание
Когда строковая константа имеет префикс N и ее длина не превышает максимальную длину строкового типа данных nvarchar (4000), результатом неявного преобразования будет строка в кодировке UCS-2 или UTF-16. В противном случае результатом неявного преобразования будет большое значение nvarchar(max).
Предупреждение
Каждому ненулевому столбцу varchar(max) и nvarchar(max) необходимо дополнительно выделить 24 байта памяти, которые учитываются в максимальном размере строки в 8060 байт во время операции сортировки. Эти дополнительные байты могут неявно ограничивать число ненулевых столбцов varchar(max) или nvarchar(max) в таблице. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Такой большой размер строки может приводить к ошибкам (например, ошибке 512), которые пользователи не ожидают во время обычных операций. Примерами операций могут служить обновление ключа кластеризованного индекса или сортировка полного набора столбцов.
Синонимы типов данных в Microsoft SQL Server
В MS SQL Server для совместимости со стандартом ISO существуют синонимы системных типов данных. Эти синонимы можно использовать в инструкциях языка Transact-SQL точно также как и соответствующие системные типы данных, единственный момент, что после создания объекта (таблицы, процедуры) синониму назначается базовый тип данных, связанный с этим синонимом, иными словами, каких-либо признаков, что в инструкции использовался синоним, нет.
Синонимы и соответствующие им системные типы данных представлены в таблице ниже:
| Системный тип данных | Синоним типа |
| varbinary | Binary varying |
| varchar | char varying |
| char | character |
| char(1) | character |
| char(n) | character( n ) |
| varchar(n) | character varying( n ) |
| decimal | Dec |
| float | Double precision |
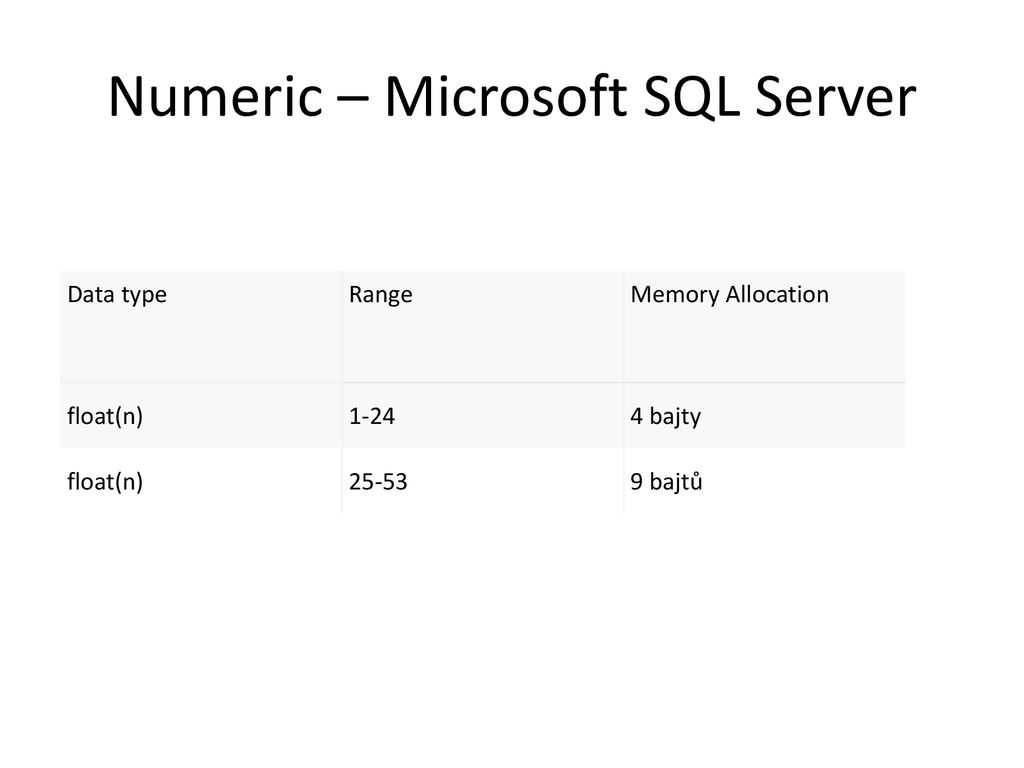
| real | float; n = 1-7 |
| float | float; n = 8-15 |
| int | Integer |
| nchar(n) | national character( n ) |
| nchar(n) | national char( n ) |
| nvarchar(n) | national character varying( n ) |
| nvarchar(n) | national char varying( n ) |
| ntext | national text |
| rowversion | timestamp |